replace selenium by js逆向
正所谓条条道路通罗马,上次我们使用了Selenium自动化工具来爬取网易云的音乐评论,Selenium自动化工具可以驱动浏览器执行特定的动作,获得浏览器当前呈现的页面的源代码,做到可见即可爬,但需要等网页完全加载完,也就是JavaScript完全渲染出来才可以获取到当前的网页源代码,这样的爬取效率太低了、爬取速度太慢了。 追求完美、追求高效率的我们,怎么会容忍效率低下呢? 所以我们今天利用Scrapy框架加js逆向来爬取网易云评论并做词云图 在爬取前,我们首先要了解一下什么是js逆向。js逆向
首先Javascript简称js,js是一种脚本语言,是不需要进行编译的,也是浏览器中的一部分,经常用在web客户端脚本语言,主要是用来给html增加动态功能,也可以进行数据加密。 加密在前端开发和爬虫中是很常见的,当我们掌握了加密算法且可以将加密的密文进行解密破解时,就可以从编程小白摇身变为编程大神,熟练掌握加密算法可以帮助我们实现高效的js逆向。常见的加密算法
js中常见的加密算法有以下几种: 线性散列MD5算法: 保证文件的正确性,防止一些人盗用程序,加些木马或者篡改版权,设计的一套验证系统,广泛用于加密和解密技术上,如用户的密码; 对称加密DES算法: 是一种使用密钥加密的算法,其加密运算、解密运算需要使用的是同样的密钥,加密后密文长度是8的整数倍; 对称加密AES算法: 是DES算法的加强版,采用分组密码体制,加密后密文长度是16的整数倍,汇聚了强安全性、高性能、高效率、易用和灵活等优点,比DES算法的加密强度更高,更安全; 非对称加密算法RSA: 在公开密钥加密和电子商业中被广泛使用,需要公开密钥和私有密钥,只有对应的私有密钥才能解密; base64伪加密: 是一种用64个字符表示任意二进制数据的方法,只是一种编码方式而不是加密算法; https证书秘钥加密: 基于http和SSL/TLS实现的一个协议,保证在网络上传输的数据都是加密的,从而保证数据安全。js逆向作用
我们发送网络请求的时候,往往需要携带请求参数,如下图所示: 有爬虫基础的人都知道,上图发送的是POST网络请求,在发送请求时,我们还要携带一些参数,例如上图中的limit和current,其中limit是每次获取的数据个数,current是页码数。
要想获取上面的URL链接所呈现中的数据时,必须要在发送网络请求时携带limit和current这两个参数。
有时候我们需要携带的请求参数是加密过的参数,如下图所示:
有爬虫基础的人都知道,上图发送的是POST网络请求,在发送请求时,我们还要携带一些参数,例如上图中的limit和current,其中limit是每次获取的数据个数,current是页码数。
要想获取上面的URL链接所呈现中的数据时,必须要在发送网络请求时携带limit和current这两个参数。
有时候我们需要携带的请求参数是加密过的参数,如下图所示:
 同样是发送POST网络请求,很明显这次的参数是已经加密过的参数,该参数是一大串不知道表达什么意思的字符串,这时就需要采用js逆向来破解该参数。
有人可能说,直接复制粘贴那参数,也获取到数据呀。
可是这样只能获取到一小部分数据或者一页的数据,不能获取到多页。
通过上面的例子,我们可以知道,js逆向可以帮助我们破解加密过的参数。
当然除了帮我们破解加密过的参数,还可以帮我们处理以下事情:
模拟登录中密码加密和其他请求参数加密处理;
动态加载且加密数据的捕获和破解;
同样是发送POST网络请求,很明显这次的参数是已经加密过的参数,该参数是一大串不知道表达什么意思的字符串,这时就需要采用js逆向来破解该参数。
有人可能说,直接复制粘贴那参数,也获取到数据呀。
可是这样只能获取到一小部分数据或者一页的数据,不能获取到多页。
通过上面的例子,我们可以知道,js逆向可以帮助我们破解加密过的参数。
当然除了帮我们破解加密过的参数,还可以帮我们处理以下事情:
模拟登录中密码加密和其他请求参数加密处理;
动态加载且加密数据的捕获和破解;
js逆向的实现
那么如何实现js逆向或者破解加密过的参数呢。 要破解加密过的参数,大致可以分为四步:-
寻找加密参数的方法位置找出来;
设置断点找到未加密参数与方法;
把加密方法写入js文件;
调试js文件。
寻找加密函数位置
首先打开开发者模式,找到你要获取的数据的URL请求条目,再把加密参数的变量复制下来,点击右上角三个小点,选择Search。 在通过Search搜索把加密参数函数的存放位置找出来,如下图所示:
在通过Search搜索把加密参数函数的存放位置找出来,如下图所示:
 经过选择我们发现加密函数放在core_b15...中,点击4126这一行就会打开core_b15...,我们再在core_b15...中搜索有没有其他params,键盘同时按下Ctrl F,如下图所示:
经过选择我们发现加密函数放在core_b15...中,点击4126这一行就会打开core_b15...,我们再在core_b15...中搜索有没有其他params,键盘同时按下Ctrl F,如下图所示:
 由上图可知,core_b15...中有34个params,这34个params中都有可能是加密参数,这里我们来告诉大家一个小技巧,一般情况下,加密参数都是以下形式输出的,
由上图可知,core_b15...中有34个params,这34个params中都有可能是加密参数,这里我们来告诉大家一个小技巧,一般情况下,加密参数都是以下形式输出的,参数:
参数 =
所以我们可以在搜索框中稍稍加点东西,例如把搜索框中的params改为params:,结果如下图所示:
 这样params就被我们精确到只有两个,接下来我们开始设置断点。
这样params就被我们精确到只有两个,接下来我们开始设置断点。
设置断点找到未加密参数与函数
在上一步中,我们把params的范围缩短到只有两处,如下图所示:
 第一种图的params只是一个类似字典的变量,而第二张图的params:bYm0x.encText,表示在bYm0x中选取encText的值赋给params,而在13367行代码中,表示encSecKey为bYm0x中encSecKey的值,所以我们可以通过变量bYm0x来获取,而在params:bYm0x.encText上两行代码中,bYm0x变量中window调用了asrsea()方法,13364行代码是我们加密参数的函数。
我们把鼠标放在window.asrsea中间,如下图所示:
第一种图的params只是一个类似字典的变量,而第二张图的params:bYm0x.encText,表示在bYm0x中选取encText的值赋给params,而在13367行代码中,表示encSecKey为bYm0x中encSecKey的值,所以我们可以通过变量bYm0x来获取,而在params:bYm0x.encText上两行代码中,bYm0x变量中window调用了asrsea()方法,13364行代码是我们加密参数的函数。
我们把鼠标放在window.asrsea中间,如下图所示:
 由上图可知,window.asrsea通过function d函数中调用的,其传入参数为d,e,f,g,点击f d(d,e,f,g),如下图所示:
由上图可知,window.asrsea通过function d函数中调用的,其传入参数为d,e,f,g,点击f d(d,e,f,g),如下图所示:
 当我们不知道从哪里设置断点时,我们可以尝试在它调用函数的一行设置断点或者你认为哪行代码可疑就在哪行代码设置断点,刷新页面,如下图所示:
当我们不知道从哪里设置断点时,我们可以尝试在它调用函数的一行设置断点或者你认为哪行代码可疑就在哪行代码设置断点,刷新页面,如下图所示:
 点击上图的1,一步步放开断点,注意观察上图中的2,3处的变化,如下图如下图所示:
点击上图的1,一步步放开断点,注意观察上图中的2,3处的变化,如下图如下图所示:
 当左边出现了评论区,但没出现评论内容时,这时右边的方框刚好出现了d,e,f,g这三个数据,而且d中的数字刚好是歌曲的id。
我们这四个参数复制下来,并去除\,观察一下:
当左边出现了评论区,但没出现评论内容时,这时右边的方框刚好出现了d,e,f,g这三个数据,而且d中的数字刚好是歌曲的id。
我们这四个参数复制下来,并去除\,观察一下:
d: "{"rid":"R_SO_4_1874158536","threadId":"R_SO_4_1874158536","pageNo":"1","pageSize":"20","cursor":"-1","offset":"0","orderType":"1","csrf_token":""}"
e: "010001"
f: "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
g: "0CoJUm6Qyw8W8jud"
通过上面的代码,我们推测rid和threadId是单曲id,pageNo是评论区的页数,pageSize是评论数据的行数,其他的不认识!
!
!
为了证实推测,我们换个歌单来测试获取d,e,f,g这四个参数:
d: "{"rid":"A_PL_0_6892176976","threadId":"A_PL_0_6892176976",\"pageNo":"1","pageSize":"20","cursor":"-1","offset":"0","orderType":"1","csrf_token":""}"
e: "010001"
f: "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
g: "0CoJUm6Qyw8W8jud"
通过观察可以发现,我们的推测是正确的,而且e,f,g是固定不变的,那么我们可以确定参数d中的参数就是未加密的参数,既然找到了未加密的参数,那么我们先把未加密的参数写入js文件中。
注意:
rid中的A_PL_0代表的是歌单,而R_SO_4代表的是单曲。
把加密参数的方法写入js文件
未加密的参数我们在上一步已经获取到了,也就知道了加密参数的函数为接下来开始把加密参数的方法并写入js文件中。 该加密参数方法如下图所示:
加密参数方法为window.asrsea(),所以我们直接复制粘贴第13364行代码作为我们的加密参数方法,并写在入口函数中,并返回变量bYm0x,具体代码如下所示:
function start(){
var bYm0x = window.asrsea(JSON.stringify(i8a), bqf4j(["流泪", "强"]), bqf4j(Sr6l.md), bqf4j(["爱心", "女孩", "惊恐", "大笑"]));
return bYm0x
}
将鼠标放在window.asrsea中间,如下图所示:
在图中我们可以知道window.asrsea()调用了function d函数,而传入的参数对应着未加密的参数d、e、f、g,而d属于字典,e、f、g属于常量,所以我们可以把上面的代码改写为:
function start(){
var bYm0x=window.asrsea(JSON.stringify(d),e,f,g);
return bYm0x
}
写了入口函数后,我们开始观察function d函数,如下图所示:
通过function d()函数,我们发现function d()函数调用了a()函数、b()函数、c()函数,所以我们要把这些函数都复制在刚才的js文件中。
当我们不知道要复制哪些代码时,就直接复制function d函数的外面一层花括号的所有代码,也就是第13217行代码为复制的开始点,第13257行代码为复制的结束点。
为了我们的js文件可以在控制台看到调试的结果,我们需要添加以下代码:
console.log(start())
调试js文件
好了,我们已经把代码复制在js文件中了,在调试js文件前,我们先安装node.js和node.js插件。node.js
node.js安装方式很简单,进入node.js官网,如下图所示: 大家选择对应的系统来下载安装,由于安装实在太简单了,都是无脑下一步就可以了,当然最好参照网上的教程来安装,这里我们就不讲解如何安装node.js。
注意:
一定要安装node.js,否则会在调试js文件中报以下错误:
大家选择对应的系统来下载安装,由于安装实在太简单了,都是无脑下一步就可以了,当然最好参照网上的教程来安装,这里我们就不讲解如何安装node.js。
注意:
一定要安装node.js,否则会在调试js文件中报以下错误:
execjs._exceptions.ProgramError: TypeError: ‘JSON‘ 未定义
node.js插件
我们写好js文件后,需要进行调试,而在pycharm中调试js文件需要安装node.js插件。 首先进入pycharm中的setting配置,如下图所示: 按照上图中的步骤,即可安装好插件。
好了,准备工作已经做好了,现在开始调试js文件,运行刚才的js文件,会发现报了以下错误:
按照上图中的步骤,即可安装好插件。
好了,准备工作已经做好了,现在开始调试js文件,运行刚才的js文件,会发现报了以下错误:
window.asrsea = d,
^
ReferenceError: window is not defined
该错误是说window没定义,这时我们只需要在最前面添加以下代码即可:
window={}
进行运行我们的js文件,发现又报错了,错误如下所示:
var c = CryptoJS.enc.Utf8.parse(b)
^
ReferenceError: CryptoJS is not defined
错误提示又是参数没定义,但CryptoJS就不能简单的设置一个空字典,这需要我们继续在刚才的core_b15...中寻找CryptoJS了,如下图所示:
 由图中可知,CryptoJS一共要13处那么多,那么我们该从何开始复制呢,又从何处结束复制呢,当我们不知道在哪里开始复制时,直接把所有的CrpytoJS都复制下来,请记住一个原则,宁愿复制多了也不复制少了,多了不会报错,少了会报错,而且还要找错,重新复制。
好了,我们复制完后,继续运行js文件。
运行结果如下:
由图中可知,CryptoJS一共要13处那么多,那么我们该从何开始复制呢,又从何处结束复制呢,当我们不知道在哪里开始复制时,直接把所有的CrpytoJS都复制下来,请记住一个原则,宁愿复制多了也不复制少了,多了不会报错,少了会报错,而且还要找错,重新复制。
好了,我们复制完后,继续运行js文件。
运行结果如下:
 好了,js文件已经运行准确无误了。
接下来开始爬取数据
好了,js文件已经运行准确无误了。
接下来开始爬取数据数据爬取
我们是通过Scrapy框架来爬取数据,所以我们首先来创建Scrapy项目和spider爬虫。创建Scrapy项目、Spider爬虫
创建Scrapy项目和Spider爬虫很简单,依次执行以下代码即可:scrapy startproject <Scrapy项目名>
cd <Scrapy项目名>
scrapy genspider <爬虫名字> <允许爬取的域名>
其中,我们的Scrapy项目名为NeteaseCould,爬虫名字为:
NC,允许爬取的域名为:
music.163.com。
好了创建Scrapy项目后,接下来我们创建一个名为JS的文件夹来存放刚才编写的js文件,项目目录如下所示:
 这里我们还创建了一个名为Read_js.py文件,该文件用来读取js文件。
这里我们还创建了一个名为Read_js.py文件,该文件用来读取js文件。
读取js文件——Read_js.py
我们编写好js文件后,当然要把它读取出来,具体代码如下所示:def get_js():
path = dirname(realpath(__file__)) + '/js/' + 'wangyi' + '.js'
with open(path,'r',encoding='utf-8')as f:
r_js=f.read()
c_js=execjs.compile(r_js)
u_js=c_js.call('start')
data={
"params":u_js['encText'],
"encSecKey":u_js['encSecKey']
}
return data
我们把读取到的js文件内容存放在r_js变量中,然后通过execjs.compile()方法获取代码编译完成后的对象,再通过call()方法来调用js文件中的入口函数,也就是start()函数。
然后将获取到的数据存放在字典data中,最后返回字典data。
对了,为了使我们的代码更灵活,我们可以把参数d放在Read_js.py文件中,具体代码如下所示:
url = 'https://music.163.com/#/song?id=17177324'
id = url.split('=')[-1]
d = {
"rid": f"R_SO_4_{id}",
"threadId": f"R_SO_4_{id}",
"pageNo": "1",
"pageSize": "5",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"csrf_token": ""
}
u_js=c_js.call('start',d)
首先利用split()方法把歌曲的id获取下来,然后放在参数d中,当我们需要获取另一首歌的评论信息的时候,只需要修改上面的url即可。
注意:
参数d中R_SO_4代表的单曲,当我们要获取其他的评论信息时,则需要更改R_SO_4,例如获取歌单的时候则需要更改为A_PL_0。
items.py文件
在获取数据前,我们先在items.py文件中,定义爬取数据的字典,具体代码如下所示:import scrapy
class NeteasecouldItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
content = scrapy.Field()
NC.py文件
在定义字段后,先看看评论数据的位置,如下图所示: 现在我们开始获取网易云音乐评论的数据,具体代码如下所示:
现在我们开始获取网易云音乐评论的数据,具体代码如下所示:
import scrapy
from NeteaseCould.Read_js import get_js
from NeteaseCould.items import NeteasecouldItem
class NcSpider(scrapy.Spider):
name = 'NC'
allowed_domains = ['music.163.com']
start_urls = ['https://music.163.com/weapi/comment/resource/comments/get?csrf_token=']
def start_requests(self):
js=get_js()
yield scrapy.FormRequest('https://music.163.com/weapi/comment/resource/comments/get?csrf_token=',formdata=js,callback=self.parse)
def parse(self, response):
json=response.json()
p=json.get('data').get('comments')
for i in p:
item = NeteasecouldItem()
item['content']=i.get('content')
yield item
首先我们导入get_js和NeteasecouldItem,再将start_urls中的链接修改为https://music.163.com/weapi/comment/resource/comments/get?csrf_token=。
由于我们发送的是POST请求,所以我们需要重写start_requests()方法,在start_requests()方法中,我们先调用了get_js()方法,然后在通过ForMReuqest()方法发送网络请求。
其中,formdata=相当于我们普通爬虫的data=callback=self.parse()表示将响应返回给parse()方法。
最后通过parse()方法进行数据的获取并通过yield生成器返回给引擎。
pipelines.py文件
当我们需要把数据放在数据库或者存放在.txt文件中数,则需要在pipelines.py文件编写代码,这里我们把数据存放在txt文件中,具体代码如下所示:from itemadapter import ItemAdapter
class NeteasecouldPipeline:
def process_item(self, item, spider):
with open('评论.txt','a',encoding='utf-8')as f:
f.write(item['content'])
f.write('\n')
获取多条评论
对了,如何获取多条评论呢,通常情况下,我们需要进行翻页来获取多条评论,但是这次不同,我们可以修改参数d中的数据就可以获取多条评论,参数d如下所示:d = {
"rid": f"R_SO_4_{id}",
"threadId": f"R_SO_4_{id}",
"pageNo": "1",
"pageSize": "5",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"csrf_token": ""
}
我们可以修改pageSize的数据,例如我现在的pageSize对应的是5,所以只获取五条评论。
settings.py文件
最后,我们需要在settings.py文件中做一些配置,具体代码如下:#屏蔽日志的输出
LOG_LEVEL="WARNING"
#开启引擎
ITEM_PIPELINES = {
'NeteaseCould.pipelines.NeteasecouldPipeline': 300,
}
结果展示
所有的代码已经编写完毕了,现在我们开始运行爬虫,执行如下代码:scrapy crawl NC
运行结果如下:

制作词云
制作词云我们需要jieba库,wordcloud库、imageio库,其安装方式如下:pip install jieba
pip install wordcloud
pip install imageio
在前面的步骤中,我们已经成功获取到评论并把评论数据保存在txt文本中,接下来我们将开始制作词云,具体代码如下:
import jieba
import wordcloud
import imageio
img_read=imageio.imread('小熊.jpg')
file_open=open('评论.txt', 'r', encoding='utf-8')
txt=file_open.read()
Cloud=wordcloud.WordCloud(width=1000,height=1000,background_color='white',mask=img_read,scale=8,font_path='C:\Windows\Fonts\msyhbd.ttc',stopwords={'的','了','是'})
txtlist=jieba.lcut(txt)
string=' '.join(txtlist)
Cloud.generate(string)
Cloud.to_file('小熊.png')
首先我们导入jieba、wordcloud、imageio库,再调用imageio.imread()方法来读取词云的背景图,然后再调用wordcloud.WordCloud()方法,把词云图设置宽高为1000,背景色为白色,词云图背景为刚才读取的图片。
注意:
当我们做的词云有中文时,我们要把系统文字路径传入到wordcloud.WordCloud()方法中,这里我们还把“的,了,是”在词云中屏蔽掉。
然后我们调用jieba.lcut()方法把text.txt文本中的文字进行切割,由于我们分割出来的文字是以列表的形式保存的,所以调用join()方法把列表转换为字符最后调用generate()方法生成词云,调用to_file()方法保存词云图。
js逆向技巧分享
当我们抓取网页端数据时,经常被加密参数、加密数据所困扰,如何快速定位这些加解密函数,尤为重要。本片文章是我逆向js时一些技巧的总结,如有遗漏,欢迎补充。 所需环境:Chrome浏览器1. 搜索
1.1 全局搜索
适用于根据关键词快速定位关键文件及代码当前页面右键->检查,弹出检查工具
 搜索支持 关键词、正则表达式
搜索支持 关键词、正则表达式
1.2 代码内搜索
适用于根据关键词快速定位关键代码点击代码,然后按ctrl+f 或 command+f 调出搜索框。搜索支持 关键词、css表达式、xpath

2. debug
2.1 常规debug
适用于分析关键函数代码逻辑埋下断点
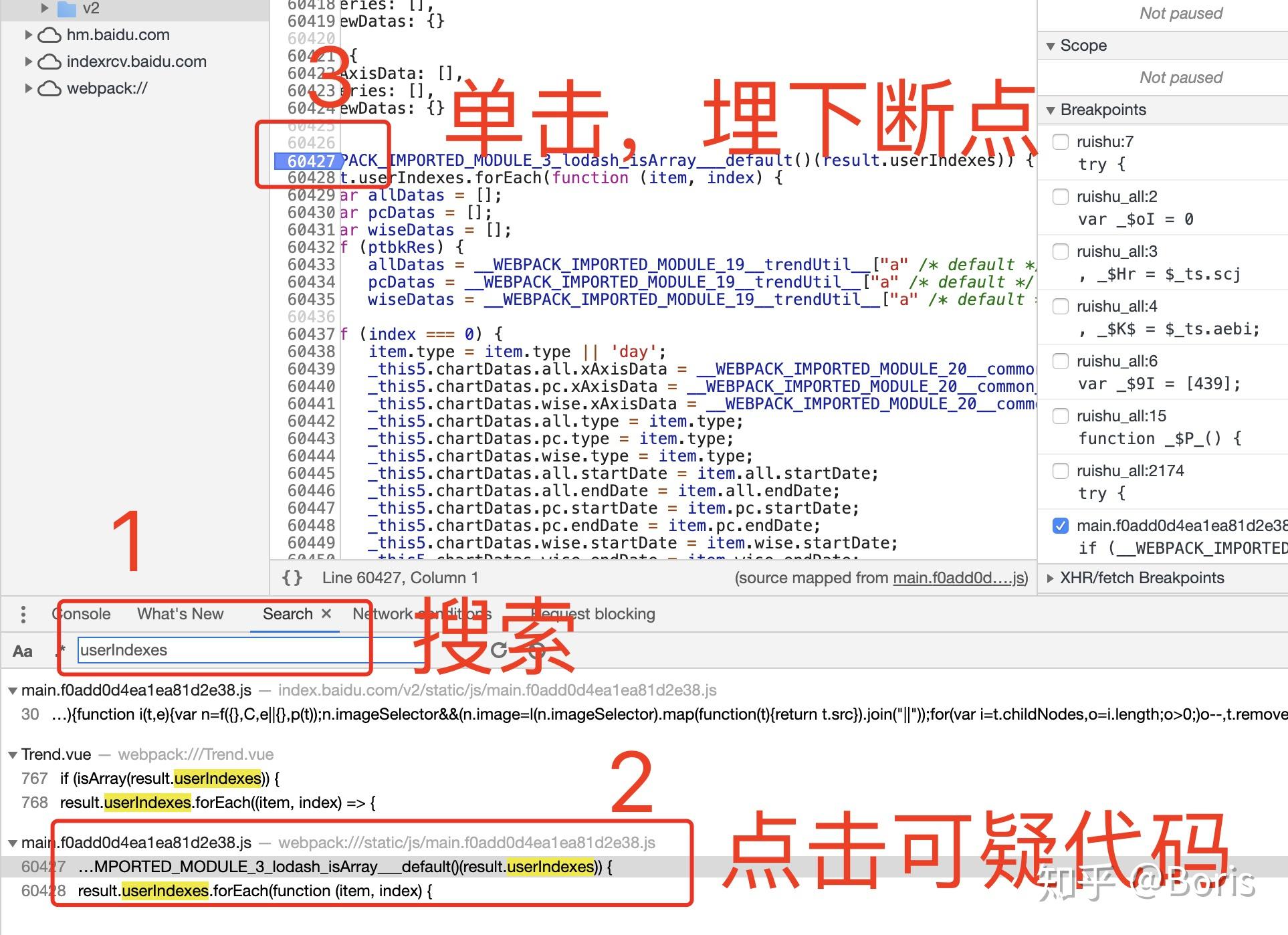 调试
调试
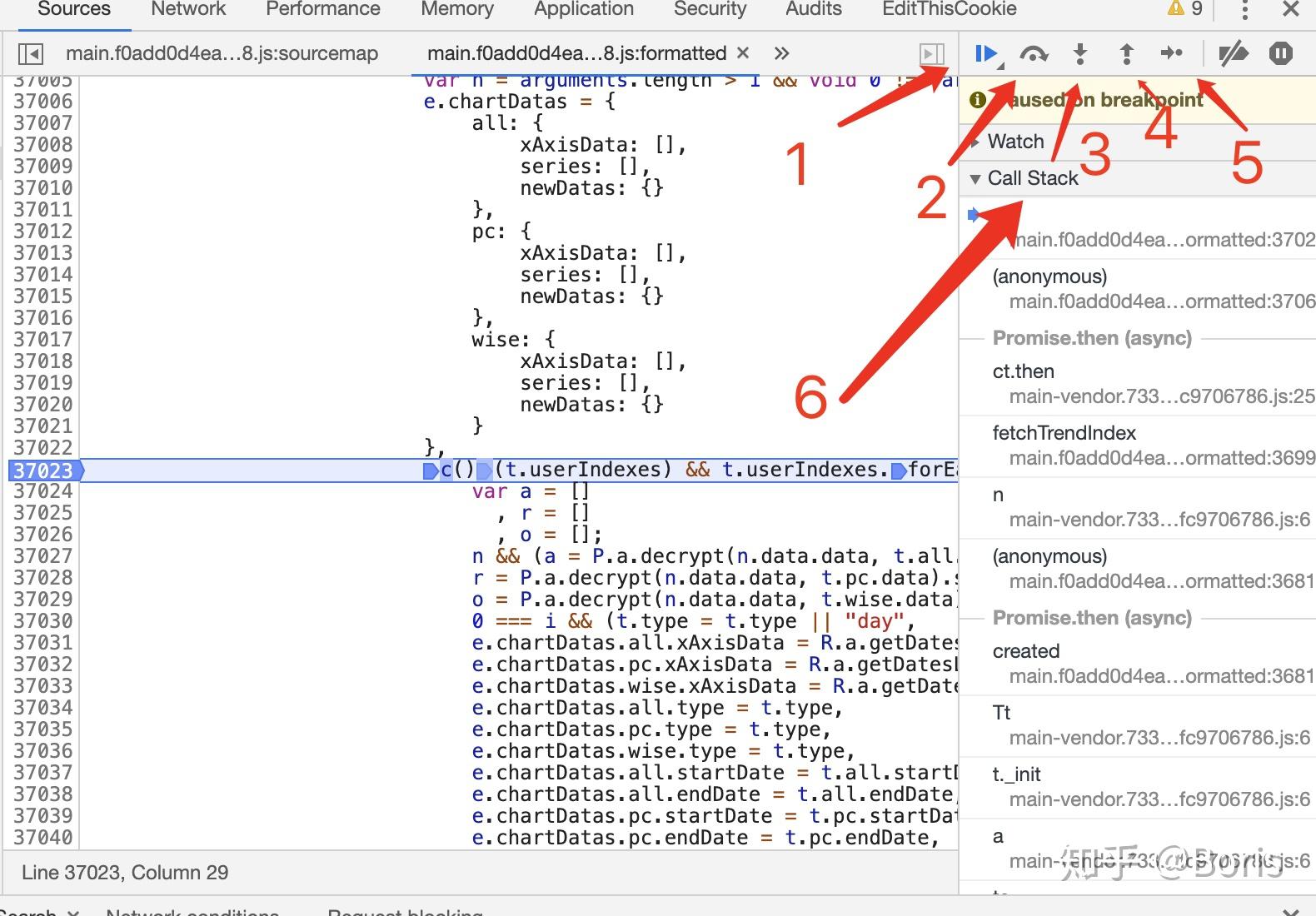 如图所示,我标记了1到6,下面分别介绍其含义
1.执行到下一个端点
2.执行下一步,不会进入所调用的函数内部
3.进入所调用的函数内部
4.跳出函数内部 5.一步步执行代码,遇到有函数调用,则进入函数
6.Call Stack 为代码调用的堆栈信息,代码执行顺序为由下至上,这对于着关键函数前后调用关系很有帮助
如图所示,我标记了1到6,下面分别介绍其含义
1.执行到下一个端点
2.执行下一步,不会进入所调用的函数内部
3.进入所调用的函数内部
4.跳出函数内部 5.一步步执行代码,遇到有函数调用,则进入函数
6.Call Stack 为代码调用的堆栈信息,代码执行顺序为由下至上,这对于着关键函数前后调用关系很有帮助
2.2 XHR debug
匹配url中关键词,匹配到则跳转到参数生成处,适用于url中的加密参数全局搜索搜不到,可采用这种方式拦截
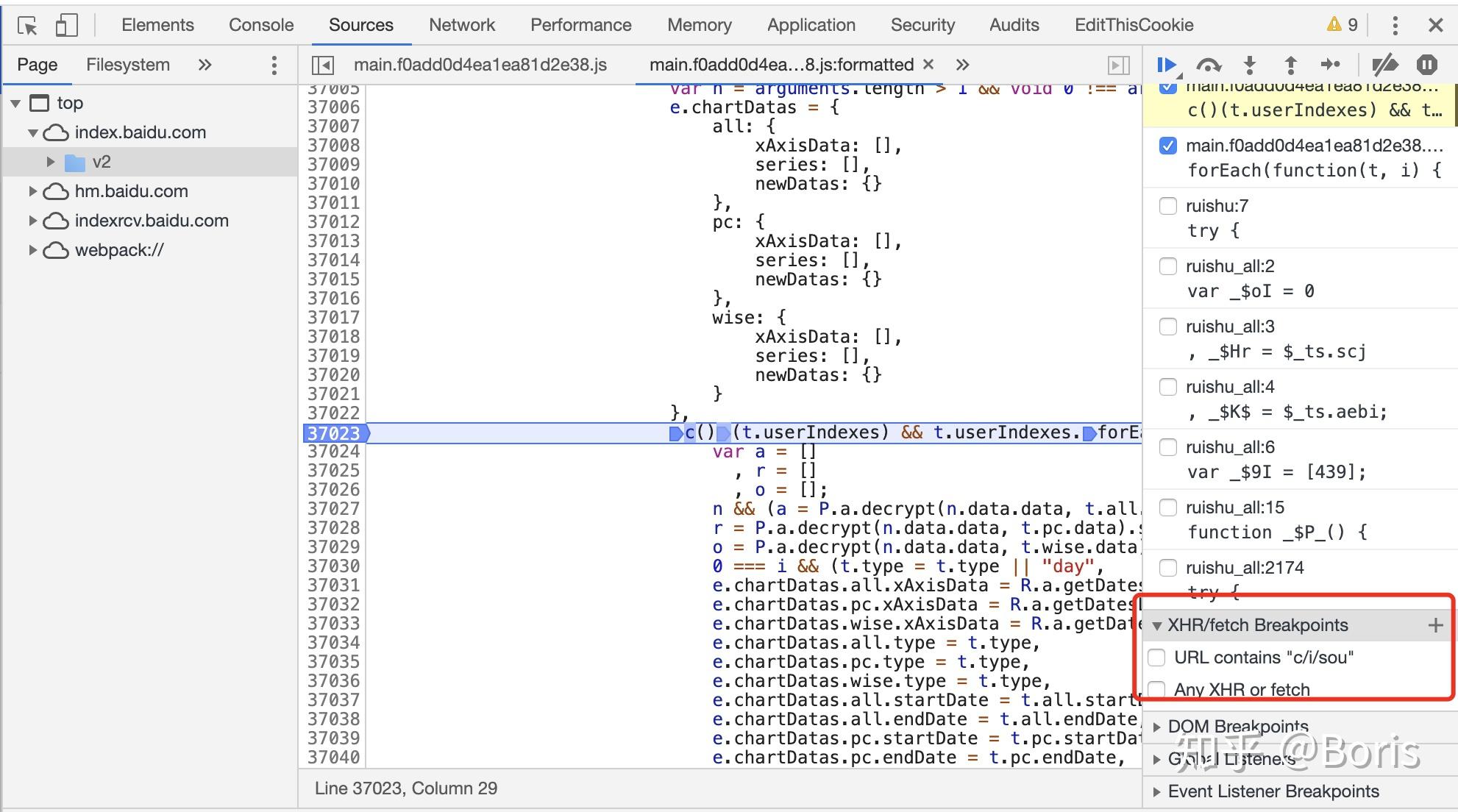
2.3 行为debug
适用于点击按钮时,分析代码执行逻辑
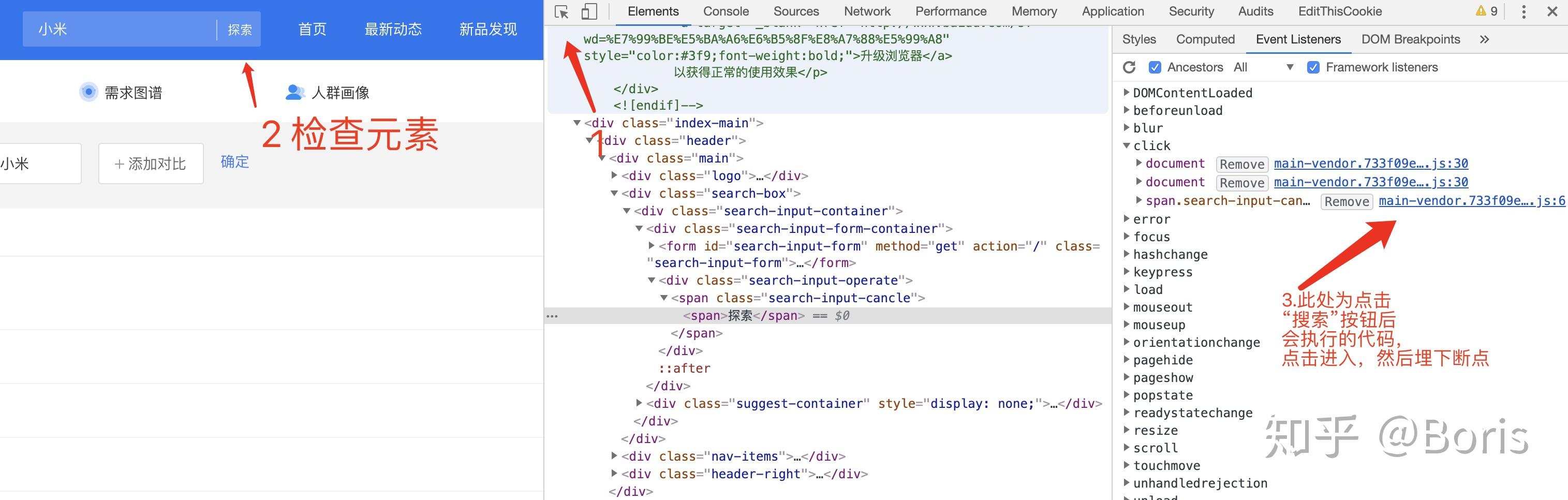 如图所示,可快速定位点击探索按钮后,所执行的js。
如图所示,可快速定位点击探索按钮后,所执行的js。
3 查看请求调用的堆栈
可以在 Network 选项卡下,该请求的 Initiator 列里看到它的调用栈,调用顺序由上而下: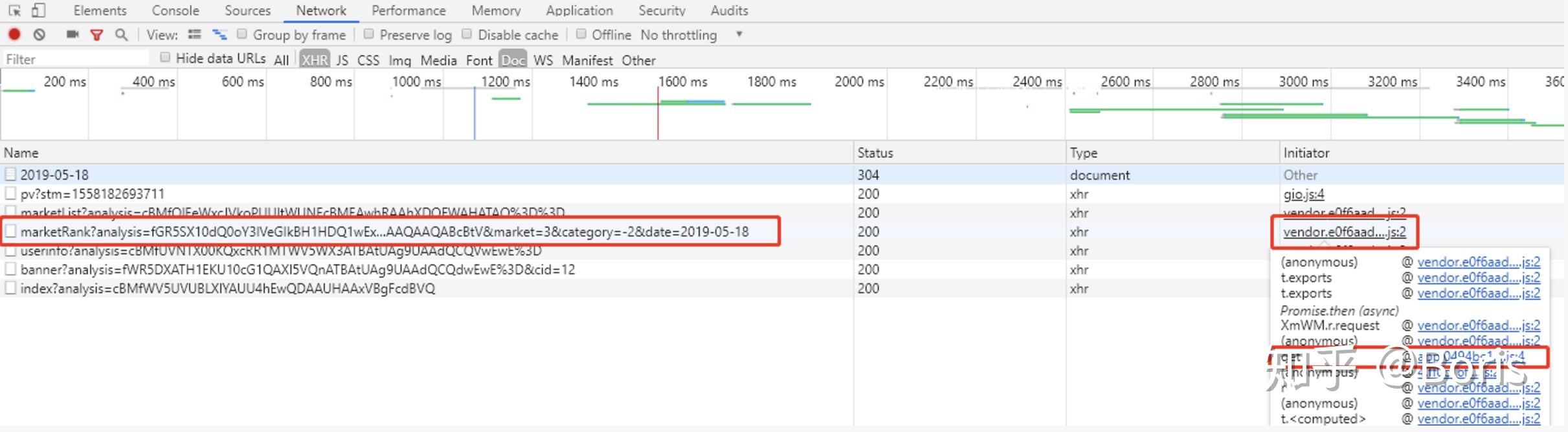
4. 执行堆内存中的函数
当debug到某一个函数时,我们想主动调用,比如传递下自定义的参数,这时可以在检查工具里的console里调用 此处要注意,只有debug打这个函数时,控制台里才可以调用。如果想保留这个函数,可使用this.xxx=xxx 的方式。之后调用时无需debug到xxx函数,直接使用http://this.xxx 即可。
此处要注意,只有debug打这个函数时,控制台里才可以调用。如果想保留这个函数,可使用this.xxx=xxx 的方式。之后调用时无需debug到xxx函数,直接使用http://this.xxx 即可。
5. 修改堆栈中的参数值
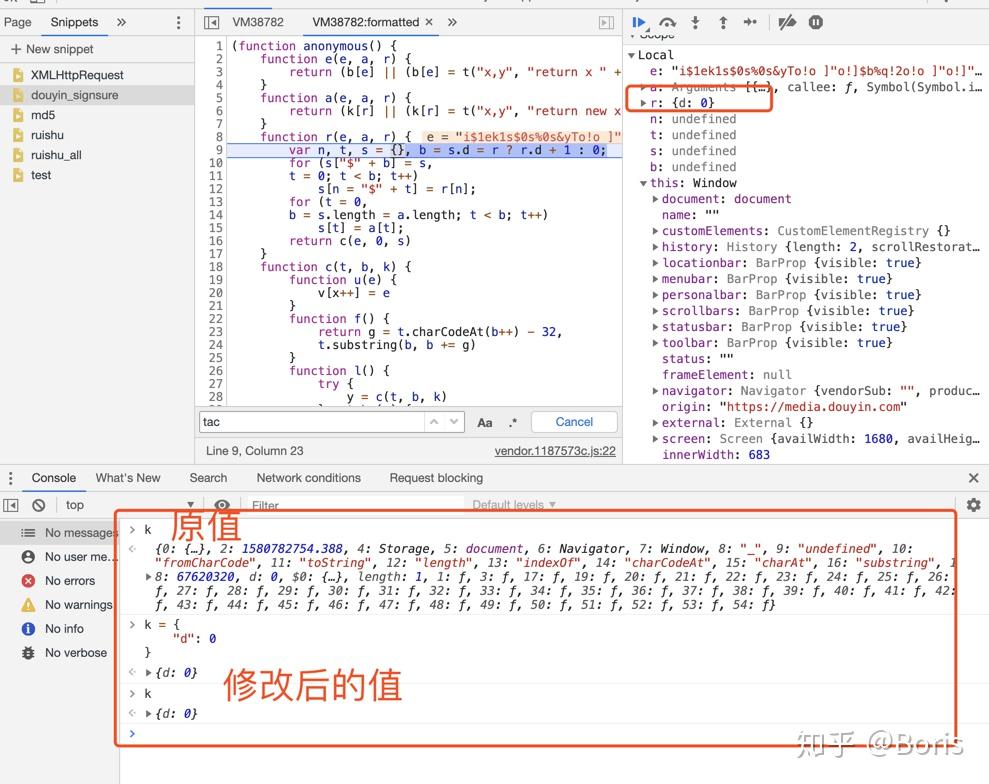
6. 写js代码
7. 打印windows对象的值
在console中输入如下代码,如只打印_$开头的变量值for (var p in window) {
if (p.substr(0, 2) !== "_$")
continue;
console.log(p + " >>> " + eval(p))
}
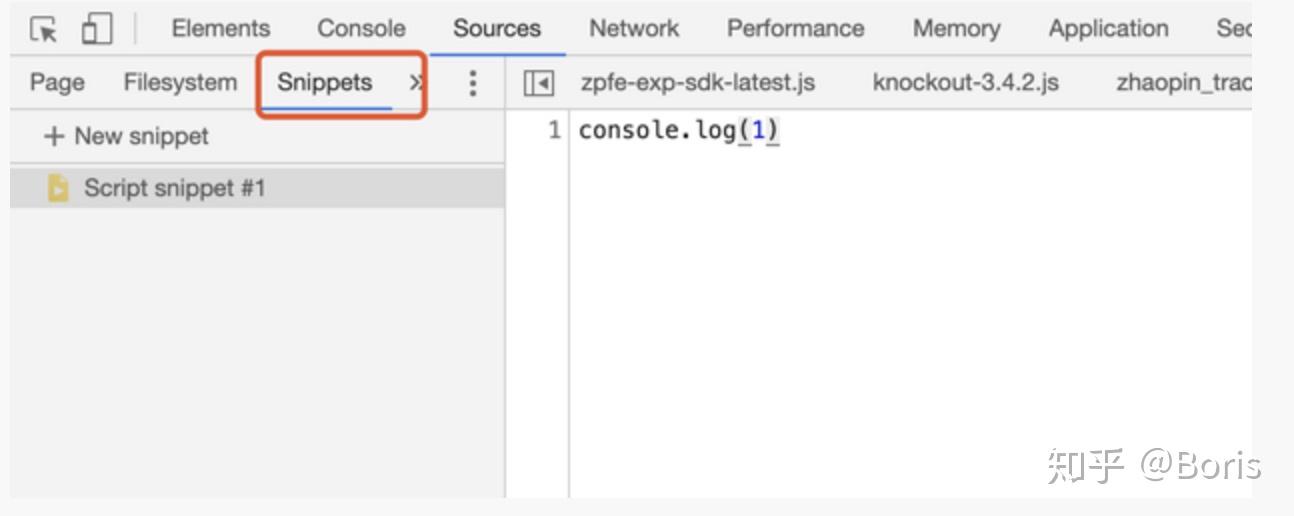
8. 勾子
以chrome插件的方式,在匹配到关键词处插入断点
8.1 cookie钩子
用于定位cookie中关键参数生成位置
var code = function(){
var org = document.cookie.__lookupSetter__('cookie');
document.__defineSetter__("cookie",function(cookie){
if(cookie.indexOf('TSdc75a61a')>-1){
debugger;
}
org = cookie;
});
document.__defineGetter__("cookie",function(){return org;});
}
var script = document.createElement('script');
script.textContent = '(' + code + ')()';
(document.head||document.documentElement).appendChild(script);
script.parentNode.removeChild(script);
当cookie中匹配到了 TSdc75a61a, 则插入断点。
8.2 请求钩子
用于定位请求中关键参数生成位置
var code = function(){
var open = window.XMLHttpRequest.prototype.open;
window.XMLHttpRequest.prototype.open = function (method, url, async){
if (url.indexOf("MmEwMD")>-1){
debugger;
}
return open.apply(this, arguments);
};
}
var script = document.createElement('script');
script.textContent = '(' + code + ')()';
(document.head||document.documentElement).appendChild(script);
script.parentNode.removeChild(script);
当请求的url里包含MmEwMD时,则插入断点
8.3 header钩子
用于定位header中关键参数生成位置
var code = function(){
var org = window.XMLHttpRequest.prototype.setRequestHeader;
window.XMLHttpRequest.prototype.setRequestHeader = function(key,value){
if(key=='Authorization'){
debugger;
}
return org.apply(this,arguments);
}
}
var script = document.createElement('script');
script.textContent = '(' + code + ')()';
(document.head||document.documentElement).appendChild(script);
script.parentNode.removeChild(script);
当header中包含Authorization时,则插入断点
8.4 manifest.json
插件的配置文件
{
"name": "Injection",
"version": "2.0",
"description": "RequestHeader钩子",
"manifest_version": 2,
"content_scripts": [
{
"matches": [
"<all_urls>"
],
"js": [
"inject.js"
],
"all_frames": true,
"permissions": [
"tabs"
],
"run_at": "document_start"
}
]
}
使用方法
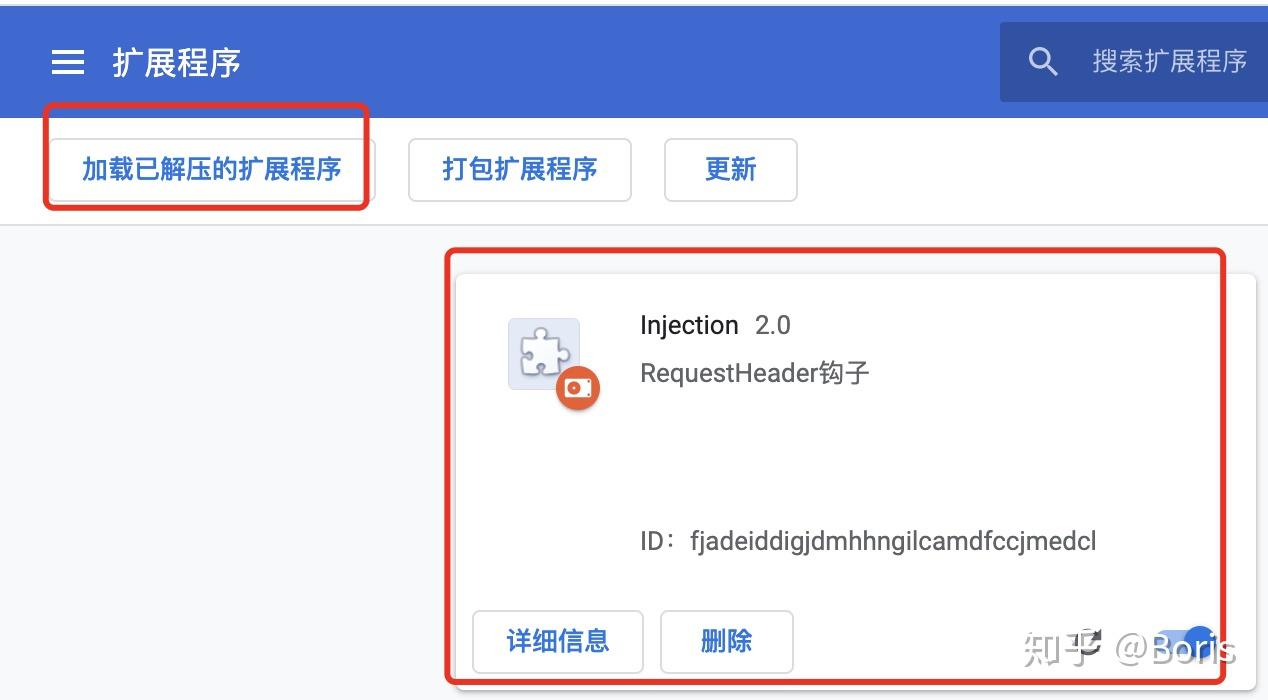
如图所示,创建一个文件夹,文件夹中创建一个钩子函数文件inject.js 及 插件的配置文件 manifest.json 即可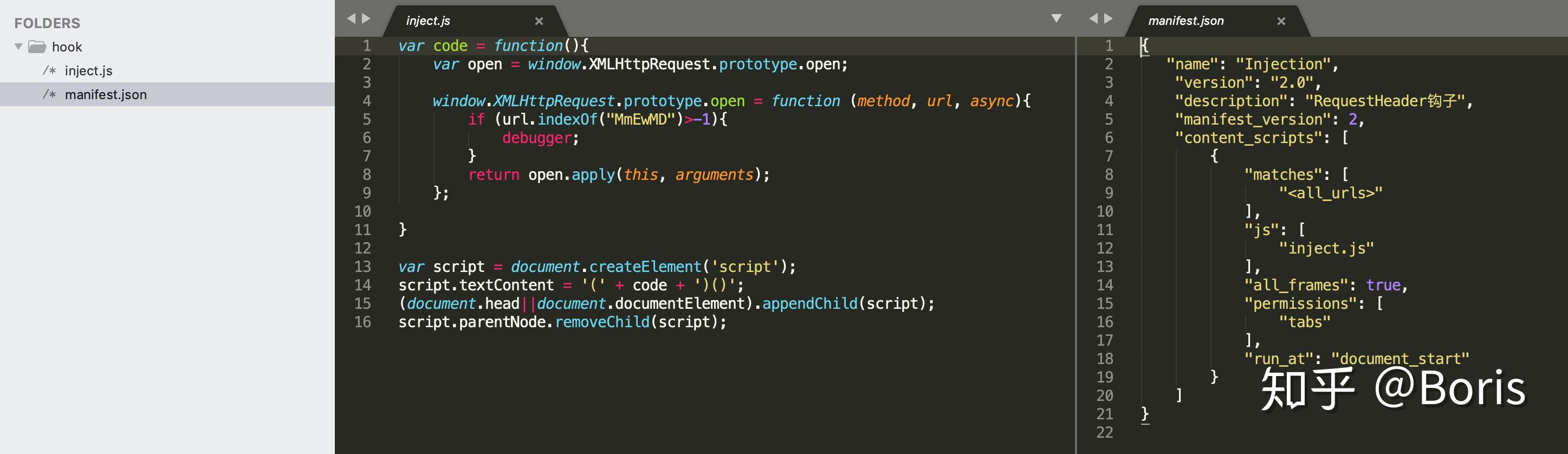 打开chrome 的扩展程序, 加载已解压的扩展程序,选择步骤1创建的文件夹即可
打开chrome 的扩展程序, 加载已解压的扩展程序,选择步骤1创建的文件夹即可
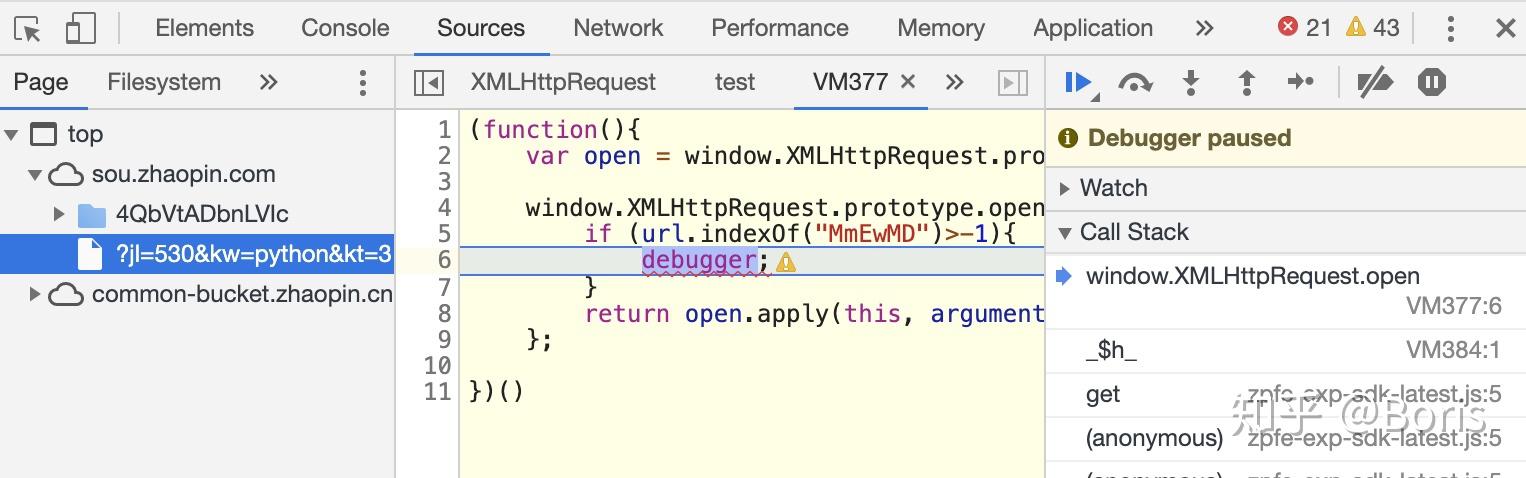
 切换回原网页,刷新页面,若钩子函数关键词匹配到了,则触发debug
切换回原网页,刷新页面,若钩子函数关键词匹配到了,则触发debug
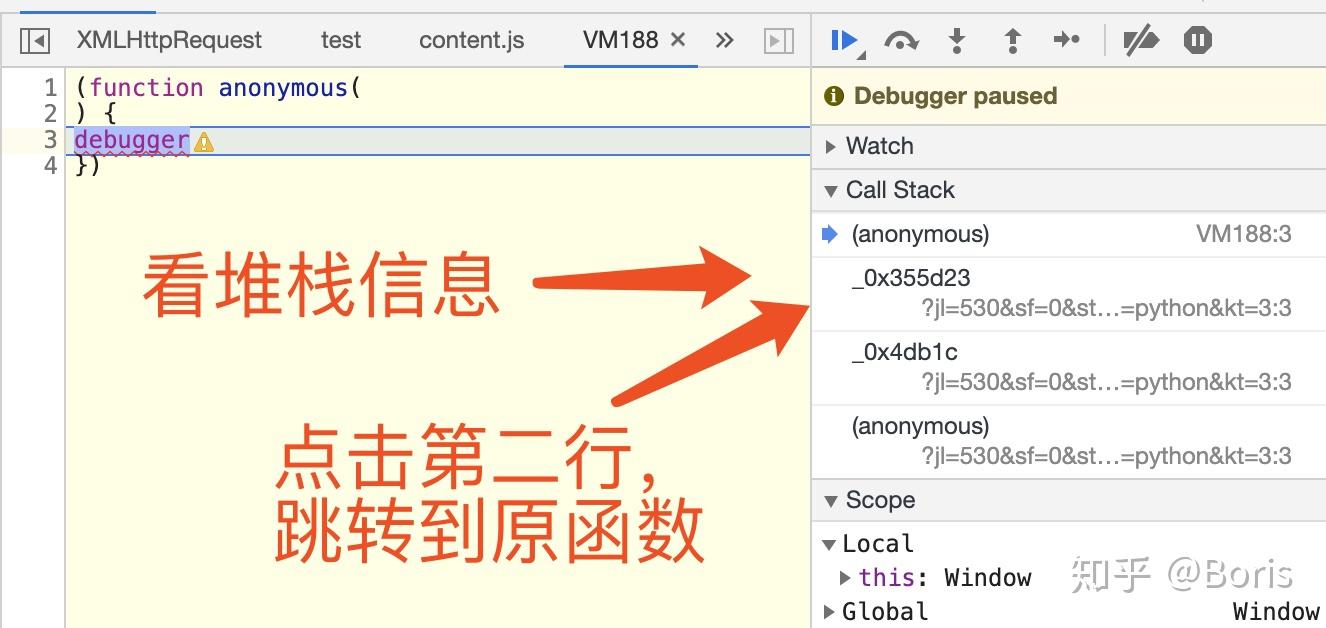
9. 破解无限debugger防调试
如果你打开chrome的检查工具,发现自动断到了如下的位置,那么这种手段为常用的反调试手段 对应的破解手段如下:
对应的破解手段如下:
9.1 方法置空
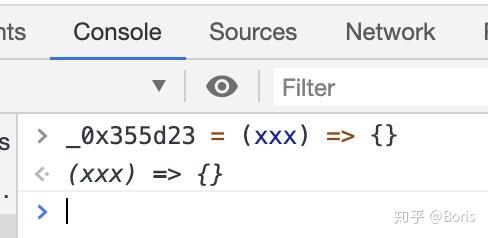
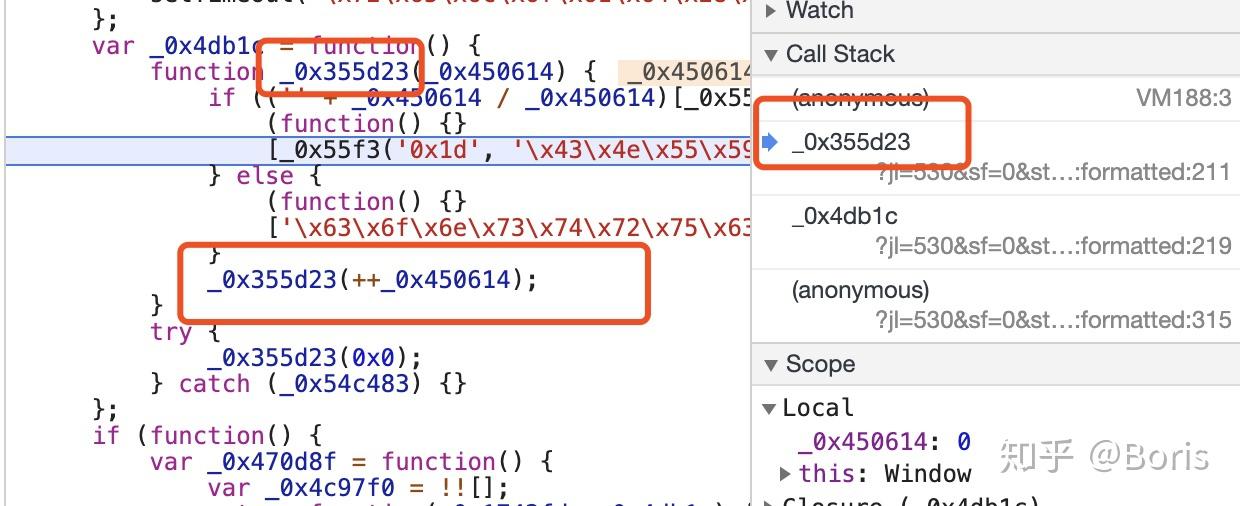 从原函数中可以看到这是一个无限递归的函数,目的就是当你开启了检查工具时,出现无数次debug,阻止你debug调试。那么我们重写这个函数就可以了,在Console 一栏中使用匿名函数给本函数重新赋值,这样就把
从原函数中可以看到这是一个无限递归的函数,目的就是当你开启了检查工具时,出现无数次debug,阻止你debug调试。那么我们重写这个函数就可以了,在Console 一栏中使用匿名函数给本函数重新赋值,这样就把_0x355d23函数变为了一个空函数,达到了破解无限debugger的目的
9.2 干掉定时器
适用于定时器类触发的debugfor (var i = 1; i < 99999; i++)window.clearInterval(i);
9.3 中间人拦截替换无限debug函数
推荐使用mitmproxy拦截10. console中使用xpath或css
xpath: $x("your_xpath_selector")
css: $$("css_selector")
11. Network下 Filters(过滤器)
筛选框可以实现很多定制化的筛选,比如字符串匹配,关键词筛选等,其中关键词筛选主要有如下几种(输入-显示全部):
domain:仅显示来自指定域的资源。您可以使用通配符()来包括多个域。例如,.com显示以.com结尾的所有域名中的资源。 DevTools会在自动完成下拉菜单中自动填充它遇到的所有域。
has-response-header:显示包含指定HTTP响应头信息的资源。 DevTools会在自动完成下拉菜单中自动填充它遇到的所有响应头。
is:通过is:running找出WebSocket请求。
larger-than(大于) :显示大于指定大小的资源(以字节为单位)。设置值1000等效于设置值1k。
method(方法) :显示通过指定的HTTP方法类型检索的资源。DevTools使用它遇到的所有HTTP方法填充下拉列表。
mime-type(mime类型:显示指定MIME类型的资源。 DevTools使用它遇到的所有MIME类型填充下拉列表。
mixed-content(混合内容:显示所有混合内容资源(mixed-content:all)或仅显示当前显示的内容(mixed-content:displayed)。
Scheme(协议):显示通过不受保护的HTTP(scheme:http)或受保护的HTTPS(scheme:https)检索的资源。
set-cookie-domain(cookie域):显示具有Set-Cookie头,并且其Domain属性与指定值匹配的资源。DevTools会在自动完成下拉菜单中自动填充它遇到的所有Cookie域。
set-cookie-name(cookie名):显示具有Set-Cookie头,并且名称与指定值匹配的资源。DevTools会在自动完成下拉菜单中自动填充它遇到的所有Cookie名。
set-cookie-value(cookie值):显示具有Set-Cookie头,并且值与指定值匹配的资源。DevTools会在自动完成下拉菜单中自动填充它遇到的所有cookie值。
status-code(状态码):仅显示其HTTP状态代码与指定代码匹配的资源。DevTools会在自动完成下拉菜单中自动填充它遇到的所有状态码。
8.2.1 理解何为逆向
与逆向相对的是正向,正向即采用某种加密方式对数据进行加密,或对加密代码进行混淆,对请求过程进行多重防护,以增加反爬策略的复杂度。
那么逆向就很好理解了:对加密的方式和请求过程进行破解、还原。
加密无非是采用8.1节所介绍的加密处理算法,难点在于js加密代码的定位,找出加密密钥(js代码中的密钥,或通过服务端接口、cookie返回的密钥)。对于JS逆向的破解需保持较大的耐心,对请求链,请求参数进行梳理和分析,分析每一步的代码逻辑,然后用Python进行模拟,在Python中模拟js代码的执行,可以使用第三方模块,比如PyV8, PyExecJS等。 现在分别从以下五个方面来浅析如何做JS逆向。
8.2.2 熟悉前端JavaScript
通常说的js,指的是javascript语言, 能看懂javascript代码是做js逆向的前提。 编程语言在许多方面是相通的,比如直接量,变量,数据类型,控制结构等,同学们在学习javascript时,可以对照着Python语言来进行学习,以达到快速掌握的目的。js逆向只需掌握基础的语法和数据结构,能看得懂代码、分析出代码的执行过程即可,无需深入学习。
8.2.3 快速定位请求源码
关于请求接口的分析,同学们可参照教程5.1节的chipscoco抓包案例所介绍的方法。 下图所示为雪球的登录请求接口: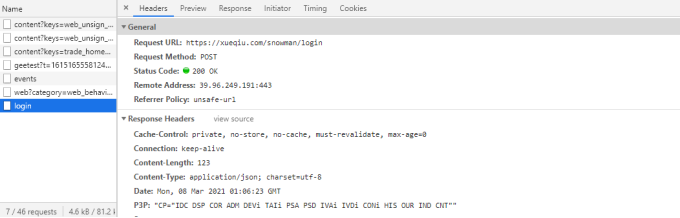 从上图可知登录的请求url为/snowman/login。
在Headers面板中鼠标下滑到底部,可以找到登录接口的请求参数:
从上图可知登录的请求url为/snowman/login。
在Headers面板中鼠标下滑到底部,可以找到登录接口的请求参数:
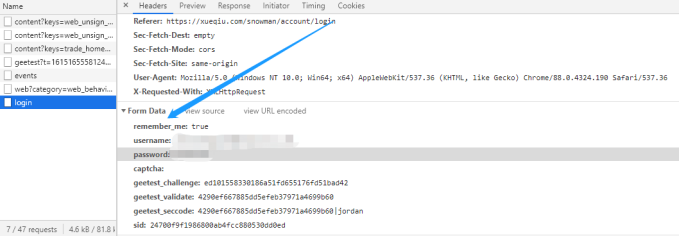 从上图可知给登录接口传递的参数为username,password,captcha等。
从上图可知给登录接口传递的参数为username,password,captcha等。
username表示用户名,password表示登录密码,captcha表示图片验证码。在找到了请求url以后,怎么快速找到发起请求的js源代码呢? 此时可以在chrome开发者模式中按下快捷键CTRL+SHIFT+F全局搜索/snowman/login:
 点击搜索结果即可跳转到发起登录请求的源码位置:
点击搜索结果即可跳转到发起登录请求的源码位置:
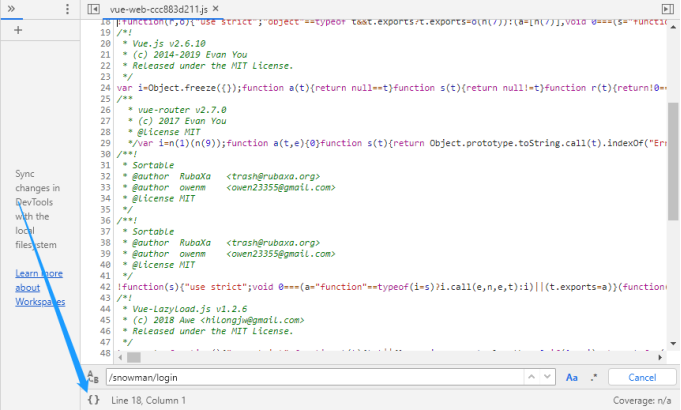 在出现的源码窗口中,可点击上图箭头所示的{}符号对代码进行格式化。
继续在源码所在的视图窗口中使用快捷键CTRL+F搜索/snowman/login:
在出现的源码窗口中,可点击上图箭头所示的{}符号对代码进行格式化。
继续在源码所在的视图窗口中使用快捷键CTRL+F搜索/snowman/login:
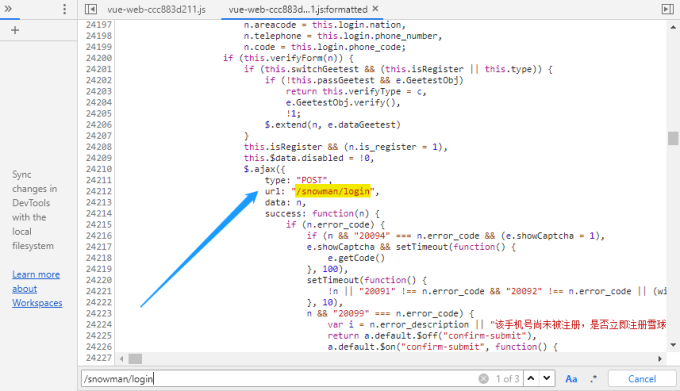 从上图可知,已经快速的定位到了发起登录请求的源码位置,为了进一步验证请求参数,可以在请求参数data所在的行设置断点(点击行号即可设置断点):
从上图可知,已经快速的定位到了发起登录请求的源码位置,为了进一步验证请求参数,可以在请求参数data所在的行设置断点(点击行号即可设置断点):
 设置断点以后,退出再重新登录,然后在控制台执行console.log(n)输出请求参数(也可以在源码视窗中鼠标悬浮对应的参数来显示参数值)
设置断点以后,退出再重新登录,然后在控制台执行console.log(n)输出请求参数(也可以在源码视窗中鼠标悬浮对应的参数来显示参数值)
 调试出了请求参数以后,需要继续在当前源码窗口中进行搜索或按下CTRL+SHIFT+F进行全局搜索,然后分析参数值是如何生成的,再用Python代码进行模拟。
比如雪球登录请求的geetest_challenge参数,该参数值是动态生成的,需要定位到该参数的源码位置,然后着手进行分析。
调试出了请求参数以后,需要继续在当前源码窗口中进行搜索或按下CTRL+SHIFT+F进行全局搜索,然后分析参数值是如何生成的,再用Python代码进行模拟。
比如雪球登录请求的geetest_challenge参数,该参数值是动态生成的,需要定位到该参数的源码位置,然后着手进行分析。
破解参数的加密方式也可以采用同样的办法,即全文搜索与加密相关的关键字,比如md5,hmac,aes, rsa,encrypt等。 读者可以在网上搜罗与加密相关的其它关键字,然后在chrome中全局搜索,这是比较快捷的方法。初学逆向的同学,需要熟练掌握chrome浏览器的使用方法:全局搜索,断点调试,查看接口的请求链等。 站点也会不定期更新反爬策略,比如变更请求接口、请求参数,对代码进行混淆等。 逆向并不是一门高深的技术,琐碎又乏味,但也并不简单,做逆向破解的人需要保持极大的耐心。
8.2.4 理解JS源码混淆
上节举的例子比较容易定位源码位置,但如果前端人员将请求url或其它参数名进行混淆,那么我们是搜索不出来的。 举个简单的例子,前端可以将请求url/snowman/login混淆成以下形式:"\x2f\x73\x6e\x6f\x77\x6d\x61\x6e\x2f\x6c\x6f\x67\x69\x6e"经过混淆后的源码大幅增加了逆向破解的难度,在逆向过程中如果遇到这种情况,该怎么办呢?所谓知己知彼,百战不殆,同学们需要先掌握前端常用的代码混淆方法。 (1) 命名混淆 命名混淆主要指对直接量,变量名,函数名,参数名等变换下形式,以大幅降低源码的可读性。 命名混淆很考验逆向人员的基础知识:JS语言特性,进制转换,字符编码等。 以字符串直接量进行举例,JS提供了将数值对象转换为字符串对象的方法,利用这样的特性,前端人员可以先获取字符的数字编码,然后将数字编码转换为二进制或十六进制。 未混淆的JS代码: // 为方便同学门理解,hmac的密钥只包含两个字符 var hmac_key = "A="; 混淆后的JS代码: // 0x41是字符A的十六进制ASCII码,0x3d是字符=的十六进制ASCII码 // 通过fromCharCode方法将ascii码转换为字符,再通过+进行拼接 var hmac_key = String.fromCharCode(0x41)+String.fromCharCode(0x3d); 上文中的变量名比较明显,此时可以将可读性强的变量名hmac_key进行修改,或者使用JS中的对象来变换为更复杂的形式: // 实际要获取的是对象e的k值 var e = {k:String.fromCharCode(0x41)+String.fromCharCode(0x3d)}; 字符串对象的fromCharCode方法依然过于明显,此时又该怎么进一步混淆呢?这留给同学们进行思考。 (2) 逻辑混淆 所谓逻辑混淆,是指对代码的执行过程进行混淆,让本来一段简单的执行逻辑变得曲折陡峭。 对代码逻辑进行混淆通常会使用到编程语言中的控制结构。 未混淆的JS代码: // 前端使用jQuery框架发起ajax请求,仅需一行代码 $.ajax({type: "POST", url: "/snowman/login",data: n}); 混淆后的JS代码: // 定义函数r function r() { // 利用字符a,j,x来拼接成字符串ajax var a = ["j", "x", "a"]; // i中的元素为字符串ajax中的字符在a中的索引 var i= [2,0,2,1]; var _$r="; // 下面的for循环看似复杂,其实逻辑很简单,就是将字符拼接为ajax for (_$i in i){ switch(i[_$i]){ case 0: _$r+=a[i[_$i]]; break; case 1: _$r+=a[1]; break; case 2: _$r+=a[i[_$i]]; break } } // 函数返回的实际是字符串"ajax" return _$r; } function c() { var _$r = {type: "POST"}; _$r["u"+"r"+"l"] = "/snowman/login"; // 调用r函数,返回字符串ajax,$[r()]等价于$["ajax"],$["ajax"]等价于$.ajax $[r()](_$r); } c(); 从以上代码实例可看出,原本只需一行代码即可发起ajax请求,但经过混淆以后,代码的执行逻辑变得迂回曲折,如果继续对字符串直接量 、变量名等进行混淆,那么代码将变得更加难以阅读。 (3) 动态执行 JavaScript提供了动态执行js代码的机制,比如常见的eval函数。 将一段源码字符串作为参数传递给eval,eval会将其解释为js代码并执行。 eval的代码实例: // eval会将字符串解释为js代码并执行 eval("var a=1;var b=2;var c=a+b; console.log(c);"); 利用这样的机制,可以先将源码字符串进行编码,然后在eval函数中解码再执行。 编码的目的同样是增加源码阅读的难度。 同学们可以在网上搜索eval加密工具,然后将上文中的字符串进行eval加密。 加密后的eval代码如下: // 原始代码为"var a=1;var b=2;var c=a+b;console.log(c);" eval(function(p,a,c,k,e,r){e=String;if('0'.replace(0,e)==0){while(c--)r[e(c)]=k[c];k=[function(e){return r[e]||e}];e=function(){return'[0]'};c=1};while(c--)if(k[c])p=p.replace(new RegExp('\\b'+e(c)+'\\b','g'),k[c]);return p} ('0 a=1;0 b=2;0 c=a+b;console.log(c);',[],1,'var'.split('|'),0,{})) 从上文的源码可知,该eval加密使用的方式主要为字符串替换以及正则表达式。
除了本节介绍的代码混淆方式,前端经常使用的还有源码压缩,js隐藏等技术,不会单一的只使用其中一种,会组合多种方式进行混淆。 感兴趣的读者可以查找相关资料作进一步学习。
8.2.5 JS代码调试利器
js源码经过混淆以后,很难对代码的执行过程进行分析,这难倒了不少逆向人员。 但同学们要知道的是,无论代码怎么混淆,最终还是要在浏览器中执行。 做JS逆向最关键的是定位到参数生成或参数加密的核心代码。 核心代码的定位,同学门需熟练掌握chrome浏览器的调试方法。在这里薯条老师推荐一款开发神器webstorm, 同学们可以将待分析的JS代码全部复制到IDE中,然后在IDE中进行代码调试。webstorm同时还支持对压缩后的代码重新格式化,以8.2.4节中的eval加密代码为例,将其复制到webstorm中:
 然后按下CTRL+ALT+L快捷键对代码进行格式化:
然后按下CTRL+ALT+L快捷键对代码进行格式化:
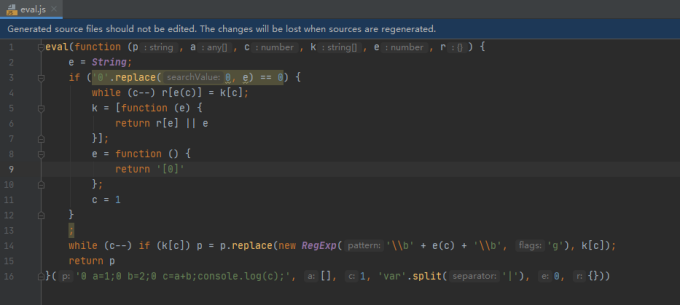 格式化完毕以后就可以着手对代码进行调试。
如需执行js代码来验证输出,也可以在视窗中右键点击run菜单来执行窗口中的js代码。
下图所示为eval加密代码执行后的输出结果:
格式化完毕以后就可以着手对代码进行调试。
如需执行js代码来验证输出,也可以在视窗中右键点击run菜单来执行窗口中的js代码。
下图所示为eval加密代码执行后的输出结果:

8.2.6 模拟JS代码的执行
做完逆向工作以后,python爬虫工程师最后需要做的是将与加密相关的核心代码用python模拟出来,然而实际情况是经过混淆、打包后的代码错综复杂,难以模拟。 此时我们可以整段代码封装为单独的函数调用,再将js代码保存到js脚本文件中,最后通过Python中的第三方模块来执行文件中的js代码,获得js程序的输出。Python社区比较流行的js执行工具有PyV8, PyExecJS等。 本节以PyExecJS为例,来讲解在Python中模拟js代码执行的用法。PyExecJS的安装很简单,直接在命令行中执行pip install PyExecJS。 下图所示为未混淆的js代码:
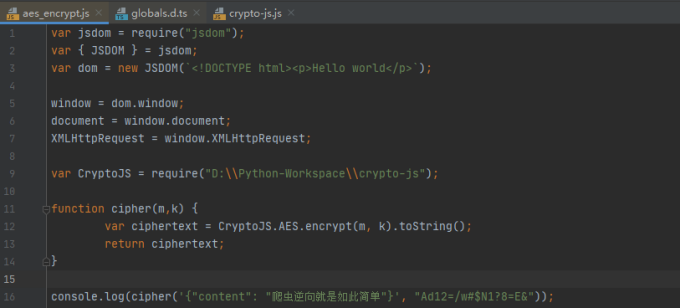 该js代码定义了一个cipher函数,使用crypto-js对请求参数进行加密。
该js代码定义了一个cipher函数,使用crypto-js对请求参数进行加密。
crypto-js的github地址:https://github.com/brix/crypto-js在webstorm中执行窗口中的js脚本程序,来测试crypto-js的AES加密功能:
 现在将该js代码使用eval进行混淆,下图所示为经过eval处理后的混淆代码:
现在将该js代码使用eval进行混淆,下图所示为经过eval处理后的混淆代码:
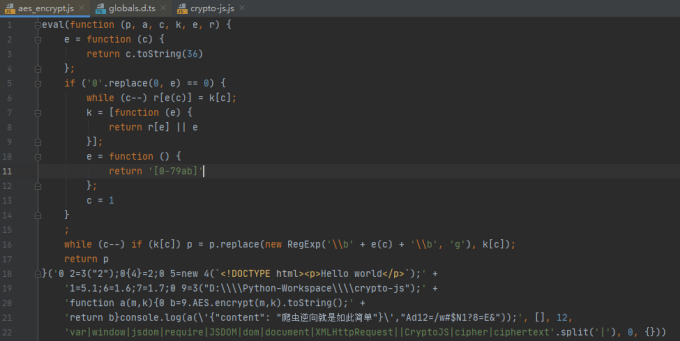 继续点击窗口中的运行菜单:
继续点击窗口中的运行菜单:
 输出结果与混淆前的输出是一样的,这说明,即便代码经过混淆,经过eval加密处理,依然可以执行。
现在通过Python中的execjs来执行上文中的js加密代码:
// 导入execjs模块
import execjs
with open(r'aes_encrypt.js', 'r', encoding='utf8') as f:
js_code = f.read()
# 执行compile方法将js源码编译为上下文处理对象
js_context = execjs.compile(js_code,
# cwd指向的是通过npm安装的Node模块的路径
cwd=r'C:\Users\86188\AppData\Roaming\npm\node_modules')
# 通过上下文对象调用源码中的cipher函数
print(js_context.call("cipher", '{"author": "薯条老师"}', "Ad12=/w#$N1?8=E&"))
输出结果与混淆前的输出是一样的,这说明,即便代码经过混淆,经过eval加密处理,依然可以执行。
现在通过Python中的execjs来执行上文中的js加密代码:
// 导入execjs模块
import execjs
with open(r'aes_encrypt.js', 'r', encoding='utf8') as f:
js_code = f.read()
# 执行compile方法将js源码编译为上下文处理对象
js_context = execjs.compile(js_code,
# cwd指向的是通过npm安装的Node模块的路径
cwd=r'C:\Users\86188\AppData\Roaming\npm\node_modules')
# 通过上下文对象调用源码中的cipher函数
print(js_context.call("cipher", '{"author": "薯条老师"}', "Ad12=/w#$N1?8=E&"))
js逆向解密经历
爬虫采集用的是scrapy-redis框架,本以为二次爬取可以轻松完成的,可没想到爬虫启动没几秒,出现了大堆的重试提示,心里顿时就咯噔一下,悠闲时光估计要结束了。 仔细分析后,发现是获取店铺列表的请求出现问题,通过浏览器抓包,发现请求头参数中相比之前多了一个X-Shard和x-uab参数,如下图所示: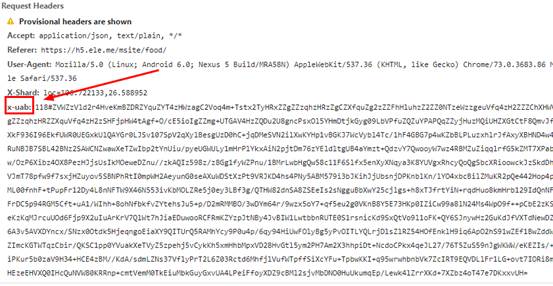 X-Shard倒是没什么问题,一看就是兴趣点的经纬度,但x-uab看过之后就让人心里苦了,js加密啊,只能去逆向解密了。
X-Shard倒是没什么问题,一看就是兴趣点的经纬度,但x-uab看过之后就让人心里苦了,js加密啊,只能去逆向解密了。
2 js逆向求解
最直接的思路是根据“x-uab”关键字在所有关键中查找(chrome浏览器-source中按ctrl + shift + F快捷键),结果如下所示: 接下来,打个断点调试一下:在数字那里点一下,数字位置出现蓝点,表示添加断点成功,然后刷新获取店铺列表的页面,程序会在断点处停下。如下所示:
接下来,打个断点调试一下:在数字那里点一下,数字位置出现蓝点,表示添加断点成功,然后刷新获取店铺列表的页面,程序会在断点处停下。如下所示:
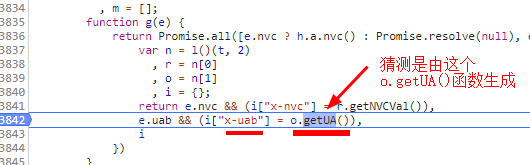 在控制台调试o.getUA()函数,看一下输出:
在控制台调试o.getUA()函数,看一下输出:
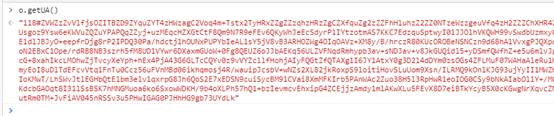 果然是,证明猜测没错,就是这个o.getUA()函数负责生成请求头中的x-uab参数。
继续向下查看这个getUA()函数的引用(把光标放在要查看的函数上,就可以查看这个函数的引用),就是下图这个函数:
果然是,证明猜测没错,就是这个o.getUA()函数负责生成请求头中的x-uab参数。
继续向下查看这个getUA()函数的引用(把光标放在要查看的函数上,就可以查看这个函数的引用),就是下图这个函数:
 图中的s就是我们要的x-uab参数,下图在控制台输出可以证明:
图中的s就是我们要的x-uab参数,下图在控制台输出可以证明:
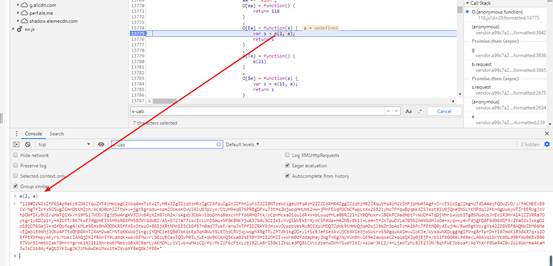 所以,u-xab是这里的e生成的,而函数e传入的参数中,第一个是常量2,第二个参数a是undefined,呵,看起来没有传其它参数。继续向下找这个e(2,a)函数:
所以,u-xab是这里的e生成的,而函数e传入的参数中,第一个是常量2,第二个参数a是undefined,呵,看起来没有传其它参数。继续向下找这个e(2,a)函数:
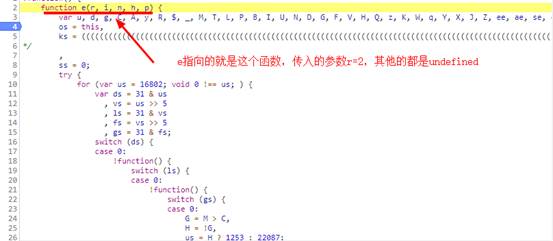 就是这个function e(r, i, n, h, p) 方法,直接运行可以获取加密后的参数。把这个function e(r, i, n, h, p) 方法全部代码取出来,另存为一个js文件。
就是这个function e(r, i, n, h, p) 方法,直接运行可以获取加密后的参数。把这个function e(r, i, n, h, p) 方法全部代码取出来,另存为一个js文件。
3 撸代码
3.1 方案一
你以为上面找出生成x-uab的js代码,就大功告成了吗?少年,you are too young too simple! 怎么把这段js脚本运行起来,才是关(nan)键(dian)。 这个function e(r, i, n, h, p) 函数有近4万行代码,重新用Python实现难(jiu)度(shi)有(bu)点(ke)大(neng)。所以,我选择直接用Python来执行这段js脚本。 怎么用python执行js脚本,度娘会给你一堆资料,自己查吧。我这里选择的是execjs。 因为在上面复制出来的脚本中,只单单定义了一个e(r, i, n, h, p)方法,并没有调用这个方法,所以,我要要在js文件的末尾添加一些代码来调用:
function getParam() {
var a;
var param = e(2,a);
return param
};
然后,开始撸Python代码吧:
import execjs
node = execjs.get()
file = 'eleme.js'
ctx = node.compile(open(file).read())
js_encode = 'getParam()'
params = ctx.eval(js_encode)
print(params)
尝试执行,心凉,代码异常:
execjs._exceptions.ProgramError: TypeError: 'window' 未定义
window对象估计是浏览器打开是创建的,蕴含浏览器的信息,所以用Python来执行这段代码时,没有这个对西乡。本来想尝试伪造window对象,但查找之后发现js脚本中上百个地方用到window,这还没完,代码经过混淆,在下水平不够,没法追根溯源(这地方困扰了我许久,哪位前辈如果知道方法,请告知)。
后来,从一个前辈那里(感谢前辈)获知一个方法绕过去。这个前辈的方法是将execjs的引擎换成PhantomJS这个无头浏览器(之前用的引擎是node.js),换句话说就是用PhantomJS来执行js脚本,PhantomJS是一个浏览器,自然就会创建window对象。
使用PhantomJS之前,需要下载它的驱动,然后放下Python代码统一目录下。对之前的Python代码也进行修改:
import execjs
import os
os.environ["EXECJS_RUNTIME"] = "PhantomJS"
node = execjs.get()
file = 'eleme.js'
ctx = node.compile(open(file).read())
js_encode = 'getParam()'
params = ctx.eval(js_encode)
print(params)
果然,按照这个方法,成功获取加密字符串。
3.2 方案二
事实上,这个方案二才是我在出现未定义window对象异常后首先尝试的方法,不过因为往js代码中添加的js脚本有问题,以为行不通,所以请教前辈,得到了方案一。 方案二的思路和方案一类似,不过更加粗暴一些。不是因为没在浏览器执行,造成没有window对象吗?那我就模拟浏览器来执行。 在执行之前,同样要修改js脚本,在js文件末尾调用e方法,添加如下代码:
var a;
var param = e(2,a);
return param;
切记:不要放在任何函数里面,我之前就是因为将这段代码放在函数里头强制执行,导致的结果就是在浏览器里可以获取加密字符串,但是在Python中获取到的却是None。
模拟浏览器用的selenium和chrome的webDriver,代码如下:
from selenium import webdriver
browser = webdriver.Chrome(executable_path='chromedriver.exe')
with open('eleme.js', 'r') as f:
js = f.read()
print(browser.execute_script(js))
这个方法也是可以获得加密之后的字符串。
最后,有必要说一下的是,如果需要获取大量的x-uab,采用方案二效率会高一下,因为采用方案二的话,可以自打开一个浏览器(都调用一个webdriver对象),然后快速执行js,返回加密字符串。
 这个问题耽搁了我很长时间,没法调试啊!
js逆向解析技巧--selenium
由于工作后期偏向架构方向,很久没做单独的爬取操作,居然有点忘记js的逆向过程了,研究了一晚上终于有了点头绪,记录下来免得以后忘记。
下面内容以对美团店铺抓取时需要破解的_token加密为准。
这个问题耽搁了我很长时间,没法调试啊!
js逆向解析技巧--selenium
由于工作后期偏向架构方向,很久没做单独的爬取操作,居然有点忘记js的逆向过程了,研究了一晚上终于有了点头绪,记录下来免得以后忘记。
下面内容以对美团店铺抓取时需要破解的_token加密为准。
 然而观察该请求所携带的参数我们发现,大多数参数是可以通过找规律的办法得到解决的,但_token这个参数是被加密过得,我们无法获取到它的值,这就需要通过反编译来解决问题。
然而观察该请求所携带的参数我们发现,大多数参数是可以通过找规律的办法得到解决的,但_token这个参数是被加密过得,我们无法获取到它的值,这就需要通过反编译来解决问题。
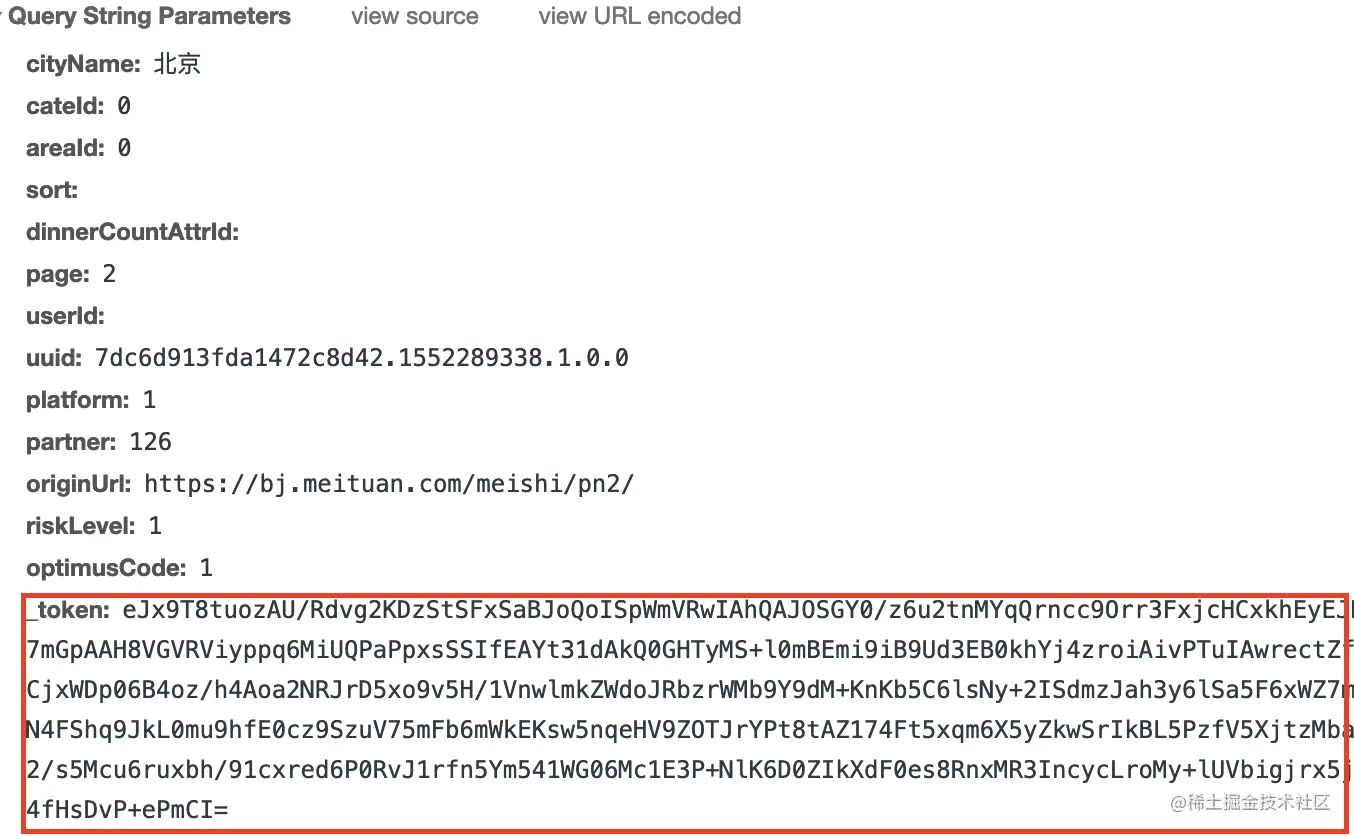 通常情况下,我们可以全局搜索_token来看是否能找到对其进行加密的js,但有的时候,数据的整个键值对都是被加密过得(参考知乎登陆的加密),我们无法通过键找到对应值得加密算法。这时候可以尝试搜索请求url中的关键部分来定位加密部位。
通常情况下,我们可以全局搜索_token来看是否能找到对其进行加密的js,但有的时候,数据的整个键值对都是被加密过得(参考知乎登陆的加密),我们无法通过键找到对应值得加密算法。这时候可以尝试搜索请求url中的关键部分来定位加密部位。
 我们可以看到,根据getPoiList我们找到了_token的的值为d,d又是通过Rohr_Opt.reload(p)方法进行加密得到想要的结果的。
我们在这个位置打上断点,再次执行下一页,当执行到reload时,我们进入找到了_token的加密js,打上断点继续观察就可以看到加密的整个流程了,如果你是js高手,可以尝试解密js,然后用python重写,这样结果的性能会好一些,但我这里使用了python直接调用js的方法进行加密。
我们可以看到,根据getPoiList我们找到了_token的的值为d,d又是通过Rohr_Opt.reload(p)方法进行加密得到想要的结果的。
我们在这个位置打上断点,再次执行下一页,当执行到reload时,我们进入找到了_token的加密js,打上断点继续观察就可以看到加密的整个流程了,如果你是js高手,可以尝试解密js,然后用python重写,这样结果的性能会好一些,但我这里使用了python直接调用js的方法进行加密。
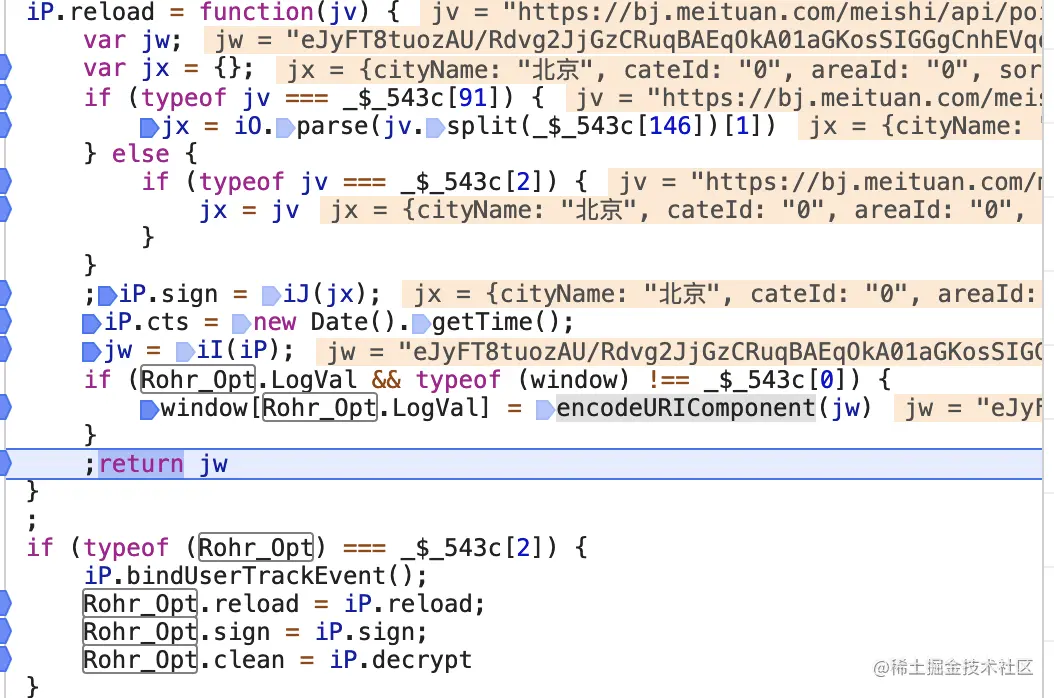 以上就是js加密的关键部位了。到这里chrome的断点调试完成。
以上就是js加密的关键部位了。到这里chrome的断点调试完成。
 第一行是rohr.html文件的绝对路径,第二行即我们所需要的_token的加密结果
第一行是rohr.html文件的绝对路径,第二行即我们所需要的_token的加密结果
4 总结
一次js逆向解密,算是完成了吧。但是也留下了一些问题: (1)使用chrome断点调试时,js脚本都是压缩混淆之后的,通过chrome的pretty print功能(也就是说那对花括号)可以格式美化,但是,有的时候却会失败,就像下图,格式化后,还是一团糟:
这个问题耽搁了我很长时间,没法调试啊!
js逆向解析技巧--selenium
由于工作后期偏向架构方向,很久没做单独的爬取操作,居然有点忘记js的逆向过程了,研究了一晚上终于有了点头绪,记录下来免得以后忘记。
下面内容以对美团店铺抓取时需要破解的_token加密为准。
1. chrome浏览器的使用--js断点调试
以美团为例,点进美团的美食页面,使用f12打开开发者工具。清空当前产生的各种请求,然后点击下一页,会发现重新生成大量的请求。切换到xhr页面观察是否通过ajax进行的请求,我们发现getPoiList开头的请求返回了我们需要的结果。2. python实现js代码的调用
通常来讲,使用execjs或者pyV8是比较主流的python调用js模块,但因为我两者都安装失败了,暂时没法使用,因此使用selenium的execute_script方法进行js调用。首先,我们将其改造成一个html文件rohr.html,并且为其添加一个可被外界调用的返回函数ssss,如下:<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<title>Checkbox</title>
<script type="text/javascript">
var Rohr_Opt = new Object;
Rohr_Opt.Flag = 100007;
Rohr_Opt.LogVal = "rohrdata";
(function() { var _$_543c = ["\x75\x6E\x64\x65\x66\x69\x6E\x65\x64",
.................
])})();
function ssss(url){
return Rohr_Opt.reload(url);
}
</script>
</head>
<body></body>
</html>复制代码
使用python对其进行调用:
from selenium import webdriver
import os
file_path = 'file:///' + os.path.abspath('rohr.html')
print(file_path)
browser = webdriver.Chrome()
browser.get(url=file_path)
jv = "https://bj.meituan.com/meishi/api/poi/getPoiList?cityName=北京&cateId=0&areaId=0&sort=&dinnerCountAttrId=&page=3&userId=&uuid=7dc6d913fda1472c8d42.1552289338.1.0.0&platform=1&partner=126&originUrl=https://bj.meituan.com/meishi/pn3/&riskLevel=1&optimusCode=1"
data = browser.execute_script('return ssss()', jv)# 这里使用execute_script调用了ssss函数,并传入参数jv
print(data) # data即我们加密后的_token
browser.close()复制代码