- scikit-learn builds on NumPy and SciPy by adding a set of algorithms for common machine learning and data mining tasks, including clustering, regression, and classification. As a library, scikit-learn has a lot going for it. Its tools are well-documented and its contributors include many machine learning experts. What’s more, it’s a very curated library, meaning developers won’t have to choose between different versions of the same algorithm. Its power and ease of use make it popular with a lot of data-heavy startups, including Evernote, OKCupid, Spotify, and Birchbox.
- Theano uses NumPy-like syntax to optimize and evaluate mathematical expressions. What sets Theano apart is that it takes advantage of the computer’s GPU in order to make data-intensive calculations up to 100x faster than the CPU alone. Theano’s speed makes it especially valuable for deep learning and other computationally complex tasks.
- TensorFlow is another high-profile entrant into machine learning, developed by Google as an open-source successor to DistBelief, their previous framework for training neural networks. TensorFlow uses a system of multi-layered nodes that allow you to quickly set up, train, and deploy artificial neural networks with large datasets. It’s what allows Google to identify objects in photos or understand spoken words in its voice-recognition app.
Libraries for Data Mining and Natural Language Processing
What if your business doesn’t have the luxury of accessing massive datasets? For many businesses, the data they need isn’t something that can be passively gathered—it has to be extracted either from documents or webpages. The following tools are designed for a variety of related tasks, from mining valuable information from websites to turning natural language into data you can use.
- Scrapy is an aptly named library for creating spider bots to systematically crawl the web and extract structured data like prices, contact info, and URLs. Originally designed for web scraping, Scrapy can also extract data from APIs.
- NLTK is a set of libraries designed for Natural Language Processing (NLP). NLTK’s basic functions allow you to tag text, identify named entities, and display parse trees, which are like sentence diagrams that reveal parts of speech and dependencies. From there, you can do more complicated things like sentiment analysis and automatic summarization. It also comes with an entire book’s worth of material about analyzing text with NLTK.
- Pattern combines the functionality of Scrapy and NLTK in a massive library designed to serve as an out-of-the-box solution for web mining, NLP, machine learning, and network analysis. Its tools include a web crawler; APIs for Google, Twitter, and Wikipedia; and text-analysis algorithms like parse trees and sentiment analysis that can be performed with just a few lines of code.
Libraries for Plotting and Visualizations
The best and most sophisticated analysis is meaningless if you can’t communicate it to other people. These libraries build on matplotlib to enable you to easily create more visually compelling and sophisticated graphs, charts, and maps, no matter what kind of analysis you’re trying to do.
- Seaborn is a popular visualization library that builds on matplotlib’s foundation. The first thing you’ll notice about Seaborn is that its default styles are much more sophisticated than matplotlib’s. Beyond that, Seaborn is a higher-level library, meaning it’s easier to generate certain kinds of plots, including heat maps, time series, and violin plots.
- Bokeh makes interactive, zoomable plots in modern web browsers using JavaScript widgets. Another nice feature of Bokeh is that it comes with three levels of interface, from high-level abstractions that allow you to quickly generate complex plots, to a low-level view that offers maximum flexibility to app developers.
- Basemap adds support for simple maps to matplotlib by taking matplotlib’s coordinates and applying them to more than 25 different projections. The library Folium further builds on Basemap and allows for the creation of interactive web maps, similar to the JavaScript widgets created by Bokeh.
- NetworkX allows you to create and analyze graphs and networks. It’s designed to work with both standard and nonstandard data formats, which makes it especially efficient and scalable. All this makes NetworkX especially well suited to analyzing complex social networks.
These libraries are just a small sample of the tools available to Python developers. If you’re ready to get your data science initiative up and running, you’re going to need the right team. Find a developer who knows the tools and techniques of statistical analysis, or a data scientist with the development skills to work in a production environment. Explore data scientists on Upwork, or learn more about the basics of Big Data.
1. Zappa
Since the release of AWS Lambda (and others that have followed), all the rage has been about serverless architectures. These allow microservices to be deployed in the cloud, in a fully managed environment where one doesn’t have to care about managing any server, but is assigned stateless, ephemeral computing containers that are fully managed by a provider. With this paradigm, events (such as a traffic spike) can trigger the execution of more of these containers and therefore give the possibility to handle “infinite” horizontal scaling.
Zappa is the serverless framework for Python, although (at least for the moment) it only has support for AWS Lambda and AWS API Gateway. It makes building so-architectured apps very simple, freeing you from most of the tedious setup you would have to do through the AWS Console or API, and has all sort of commands to ease deployment and managing different environments.
2. Sanic + uvloop
Who said Python couldn’t be fast? Apart from competing for the best name of a software library ever, Sanic also competes for the fastest Python web framework ever, and appears to be the winner by a clear margin. It is a Flask-like Python 3.5+ web server that is designed for speed. Another library, uvloop, is an ultra fast drop-in replacement for asyncio’s event loop that uses libuv under the hood. Together, these two things make a great combination!
According to the Sanic author’s benchmark, uvloop could power this beast to handle more than 33k requests/s which is just insane (and faster than node.js). Your code can benefit from the new async/await syntax so it will look neat too; besides we love the Flask-style API. Make sure to give Sanic a try, and if you are using asyncio, you can surely benefit from uvloop with very little change in your code!
3. asyncpg
In line with recent developments for the asyncio framework, the folks from MagicStack bring us this efficient asynchronous (currently CPython 3.5 only) database interface library designed specifically for PostgreSQL. It has zero dependencies, meaning there is no need to have libpq installed. In contrast with psycopg2 (the most popular PostgreSQL adapter for Python) which exchanges data with the database server in text format, asyncpg implements PostgreSQL binary I/O protocol, which not only allows support for generic types but also comes with numerous performance benefits.
The benchmarks are clear: asyncpg is on average, at least 3x faster than psycopg2 (or aiopg), and faster than the node.js and Go implementations.
4. boto3
If you have your infrastructure on AWS or otherwise make use of their services (such as S3), you should be very happy that boto, the Python interface for AWS API, got a completely rewrite from the ground up. The great thing is that you don’t need to migrate your app all at once: you can use boto3 and boto (2) at the same time; for example using boto3 only for new parts of your application.
The new implementation is much more consistent between different services, and since it uses a data-driven approach to generate classes at runtime from JSON description files, it will always get fast updates. No more lagging behind new Amazon API features, move to boto3!
5. TensorFlow
Do we even need an introduction here? Since it was released by Google in November 2015, this library has gained a huge momentum and has become the #1 trendiest GitHub Python repository. In case you have been living under a rock for the past year, TensorFlow is a library for numerical computation using data flow graphs, which can run over GPU or CPU.
We have quickly witnessed it become a trend in the Machine Learning community (especially Deep Learning, see our post on 10 main takeaways from MLconf), not only growing its uses in research but also being widely used in production applications. If you are doing Deep Learning and want to use it through a higher level interface, you can try using it as a backend for Keras (which made it to last years post) or the newer TensorFlow-Slim.
6. gym + universe
If you are into AI, you surely have heard about the OpenAI non-profit artificial intelligence research company (backed by Elon Musk et al.). The researchers have open sourced some Python code this year! Gym is a toolkit for developing and comparing reinforcement learning algorithms. It consists of an open-source library with a collection of test problems (environments) that can be used to test reinforcement learning algorithms, and a site and API that allows to compare the performance of trained algorithms (agents). Since it doesn’t care about the implementation of the agent, you can build them with the computation library of your choice: bare numpy, TensorFlow, Theano, etc.
We also have the recently released universe, a software platform for researching into general intelligence across games, websites and other applications. This fits perfectly with gym, since it allows any real-world application to be turned into a gym environment. Researchers hope that this limitless possibility will accelerate research into smarter agents that can solve general purpose tasks.
7. Bokeh
You may be familiar with some of the libraries Python has to offer for data visualization; the most popular of which are matplotlib and seaborn. Bokeh, however, is created for interactive visualization, and targets modern web browsers for the presentation. This means Bokeh can create a plot which lets you explore the data from a web browser. The great thing is that it integrates tightly with Jupyter Notebooks, so you can use it with your probably go-to tool for your research. There is also an optional server component, bokeh-server, with many powerful capabilities like server-side downsampling of large dataset (no more slow network tranfers/browser!), streaming data, transformations, etc.
Make sure to check the gallery for examples of what you can create. They look awesome!
8. Blaze
Sometimes, you want to run analytics over a dataset too big to fit your computer’s RAM. If you cannot rely on numpy or Pandas, you usually turn to other tools like PostgreSQL, MongoDB, Hadoop, Spark, or many others. Depending on the use case, one or more of these tools can make sense, each with their own strengths and weaknesses. The problem? There is a big overhead here because you need to learn how each of these systems work and how to insert data in the proper form.
Blaze provides a uniform interface that abstracts you away from several database technologies. At the core, the library provides a way to express computations. Blaze itself doesn’t actually do any computation: it just knows how to instruct a specific backend who will be in charge of performing it. There is so much more to Blaze (thus the ecosystem), as libraries that have come out of its development. For example, Dask implements a drop-in replacement for NumPy array that can handle content larger than memory and leverage multiple cores, and also comes with dynamic task scheduling. Interesting stuff.
9. arrow
There is a famous saying that there are only two hard problems in Computer Science: cache invalidation and naming things. I think the saying is clearly missing one thing: managing datetimes. If you have ever tried to do that in Python, you will know that the standard library has a gazillion modules and types: datetime, date, calendar, tzinfo, timedelta, relativedelta, pytz, etc. Worse, it is timezone naive by default.
Arrow is “datetime for humans”, offering a sensible approach to creating, manipulating, formatting and converting dates, times, and timestamps. It is a replacement for the datetime type that supports Python 2 or 3, and provides a much nicer interface as well as filling the gaps with new functionality (such as humanize). Even if you don’t really need arrow, using it can greatly reduce the boilerplate in your code.
10. hug
Expose your internal API externally, drastically simplifying Python API development. Hug is a next-generation Python 3 (only) library that will provide you with the cleanest way to create HTTP REST APIs in Python. It is not a web framework per se (although that is a function it performs exceptionally well), but only focuses on exposing idiomatically correct and standard internal Python APIs externally. The idea is simple: you define logic and structure once, and you can expose your API through multiple means. Currently, it supports exposing REST API or command line interface.
You can use type annotations that let hug not only generate documentation for your API but also provide with validation and clean error messages that will make your life (and your API user’s) a lot easier. Hug is built on Falcon’s high performance HTTP library, which means you can deploy this to production using any wsgi-compatible server such as gunicorn.
Core Libraries.
1. NumPy (Commits: 15980, Contributors: 522)
When starting to deal with the scientific task in Python, one inevitably comes for help to Python’s SciPy Stack, which is a collection of software specifically designed for scientific computing in Python (do not confuse with SciPy library, which is part of this stack, and the community around this stack). This way we want to start with a look at it. However, the stack is pretty vast, there is more than a dozen of libraries in it, and we want to put a focal point on the core packages (particularly the most essential ones).
The most fundamental package, around which the scientific computation stack is built, is NumPy (stands for Numerical Python). It provides an abundance of useful features for operations on n-arrays and matrices in Python. The library provides vectorization of mathematical operations on the NumPy array type, which ameliorates performance and accordingly speeds up the execution.
2. SciPy (Commits: 17213, Contributors: 489)
SciPy is a library of software for engineering and science. Again you need to understand the difference between SciPy Stack and SciPy Library. SciPy contains modules for linear algebra, optimization, integration, and statistics. The main functionality of SciPy library is built upon NumPy, and its arrays thus make substantial use of NumPy. It provides efficient numerical routines as numerical integration, optimization, and many others via its specific submodules. The functions in all submodules of SciPy are well documented — another coin in its pot.
3. Pandas (Commits: 15089, Contributors: 762)
Pandas is a Python package designed to do work with “labeled” and “relational” data simple and intuitive. Pandas is a perfect tool for data wrangling. It designed for quick and easy data manipulation, aggregation, and visualization.
There are two main data structures in the library:
“Series” — one-dimensional
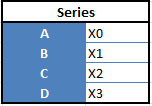
“Data Frames”, two-dimensional
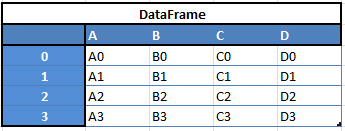
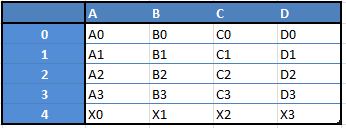
For example, when you want to receive a new Dataframe from these two types of structures, as a result you will receive such DF by appending a single row to a DataFrame by passing a Series:
Here is just a small list of things that you can do with Pandas:
- Easily delete and add columns from DataFrame
- Convert data structures to DataFrame objects
- Handle missing data, represents as NaNs
- Powerful grouping by functionality
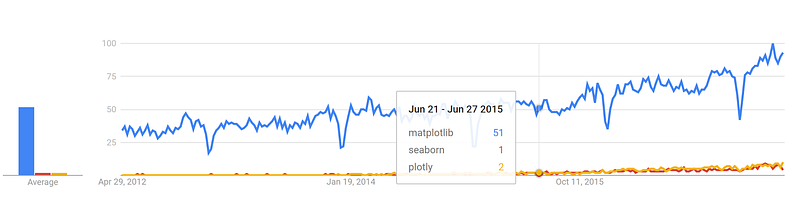
Google Trends history
trends.google.com
GitHub pull requests history
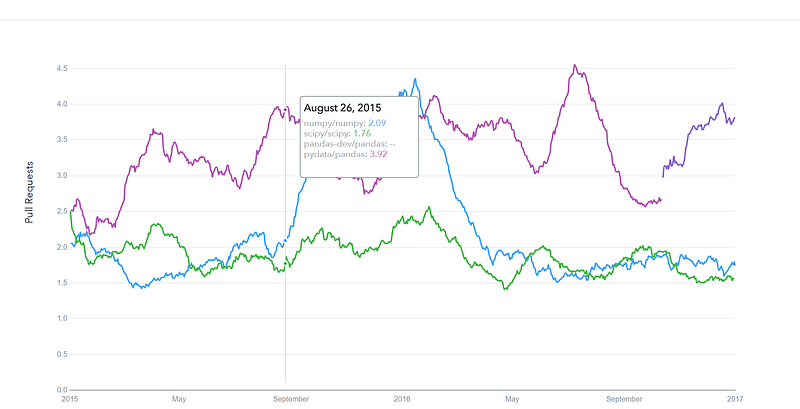
datascience.com/trends
Visualization.
4.Matplotlib (Commits: 21754, Contributors: 588)
Another SciPy Stack core package and another Python Library that is tailored for the generation of simple and powerful visualizations with ease is Matplotlib. It is a top-notch piece of software which is making Python (with some help of NumPy, SciPy, and Pandas) a cognizant competitor to such scientific tools as MatLab or Mathematica.
However, the library is pretty low-level, meaning that you will need to write more code to reach the advanced levels of visualizations and you will generally put more effort, than if using more high-level tools, but the overall effort is worth a shot.
With a bit of effort you can make just about any visualizations:
- Line plots;
- Scatter plots;
- Bar charts and Histograms;
- Pie charts;
- Stem plots;
- Contour plots;
- Quiver plots;
- Spectrograms.
There are also facilities for creating labels, grids, legends, and many other formatting entities with Matplotlib. Basically, everything is customizable.
The library is supported by different platforms and makes use of different GUI kits for the depiction of resulting visualizations. Varying IDEs (like IPython) support functionality of Matplotlib.
There are also some additional libraries that can make visualization even easier.
5. Seaborn (Commits: 1699, Contributors: 71)
Seaborn is mostly focused on the visualization of statistical models; such visualizations include heat maps, those that summarize the data but still depict the overall distributions. Seaborn is based on Matplotlib and highly dependent on that.
6. Bokeh (Commits: 15724, Contributors: 223)
Another great visualization library is Bokeh, which is aimed at interactive visualizations. In contrast to the previous library, this one is independent of Matplotlib. The main focus of Bokeh, as we already mentioned, is interactivity and it makes its presentation via modern browsers in the style of Data-Driven Documents (d3.js).
7. Plotly (Commits: 2486, Contributors: 33)
Finally, a word about Plotly. It is rather a web-based toolbox for building visualizations, exposing APIs to some programming languages (Python among them). There is a number of robust, out-of-box graphics on the plot.ly website. In order to use Plotly, you will need to set up your API key. The graphics will be processed server side and will be posted on the internet, but there is a way to avoid it.
Google Trends history
trends.google.com
GitHub pull requests history
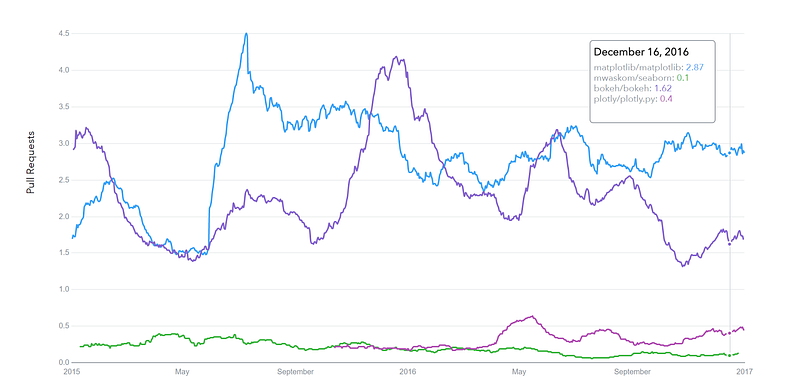
datascience.com/trends
Machine Learning.
8. SciKit-Learn (Commits: 21793, Contributors: 842)
Scikits are additional packages of SciPy Stack designed for specific functionalities like image processing and machine learning facilitation. In the regard of the latter, one of the most prominent of these packages is scikit-learn. The package is built on the top of SciPy and makes heavy use of its math operations.
The scikit-learn exposes a concise and consistent interface to the common machine learning algorithms, making it simple to bring ML into production systems. The library combines quality code and good documentation, ease of use and high performance and is de-facto industry standard for machine learning with Python.
Deep Learning — Keras / TensorFlow / Theano
In the regard of Deep Learning, one of the most prominent and convenient libraries for Python in this field is Keras, which can function either on top of TensorFlow or Theano. Let’s reveal some details about all of them.
9.Theano. (Commits: 25870, Contributors: 300)
Firstly, let’s talk about Theano.
Theano is a Python package that defines multi-dimensional arrays similar to NumPy, along with math operations and expressions. The library is compiled, making it run efficiently on all architectures. Originally developed by the Machine Learning group of Université de Montréal, it is primarily used for the needs of Machine Learning.
The important thing to note is that Theano tightly integrates with NumPy on low-level of its operations. The library also optimizes the use of GPU and CPU, making the performance of data-intensive computation even faster.
Efficiency and stability tweaks allow for much more precise results with even very small values, for example, computation of log(1+x) will give cognizant results for even smallest values of x.
10. TensorFlow. (Commits: 16785, Contributors: 795)

Coming from developers at Google, it is an open-source library of data flow graphs computations, which are sharpened for Machine Learning. It was designed to meet the high-demand requirements of Google environment for training Neural Networks and is a successor of DistBelief, a Machine Learning system, based on Neural Networks. However, TensorFlow isn’t strictly for scientific use in border’s of Google — it is general enough to use it in a variety of real-world application.
The key feature of TensorFlow is their multi-layered nodes system that enables quick training of artificial neural networks on large datasets. This powers Google’s voice recognition and object identification from pictures.
11. Keras. (Commits: 3519, Contributors: 428)
And finally, let’s look at the Keras. It is an open-source library for building Neural Networks at a high-level of the interface, and it is written in Python. It is minimalistic and straightforward with high-level of extensibility. It uses Theano or TensorFlow as its backends, but Microsoft makes its efforts now to integrate CNTK (Microsoft’s Cognitive Toolkit) as a new back-end.
The minimalistic approach in design aimed at fast and easy experimentation through the building of compact systems.
Keras is really eased to get started with and keep going with quick prototyping. It is written in pure Python and high-level in its nature. It is highly modular and extendable. Notwithstanding its ease, simplicity, and high-level orientation, Keras is still deep and powerful enough for serious modeling.
The general idea of Keras is based on layers, and everything else is built around them. Data is prepared in tensors, the first layer is responsible for input of tensors, the last layer is responsible for output, and the model is built in between.
Google Trends history
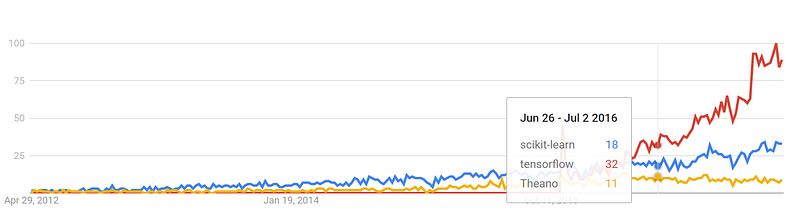
trends.google.com
GitHub pull requests history
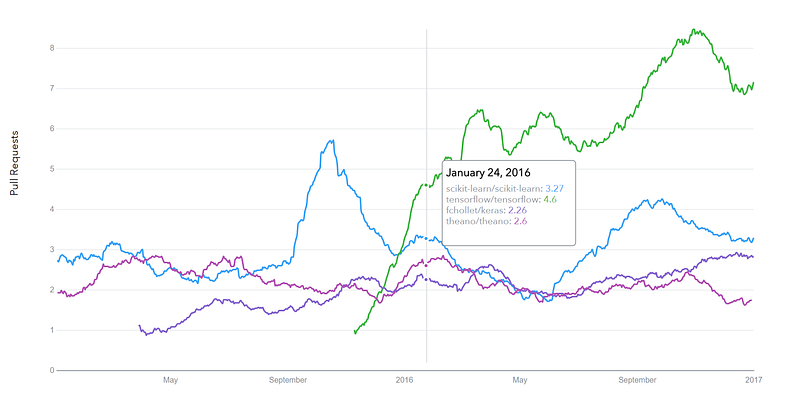
datascience.com/trends
Natural Language Processing.
12. NLTK (Commits: 12449, Contributors: 196)
The name of this suite of libraries stands for Natural Language Toolkit and, as the name implies, it used for common tasks of symbolic and statistical Natural Language Processing. NLTK was intended to facilitate teaching and research of NLP and the related fields (Linguistics, Cognitive Science Artificial Intelligence, etc.) and it is being used with a focus on this today.
The functionality of NLTK allows a lot of operations such as text tagging, classification, and tokenizing, name entities identification, building corpus tree that reveals inter and intra-sentence dependencies, stemming, semantic reasoning. All of the building blocks allow for building complex research systems for different tasks, for example, sentiment analytics, automatic summarization.
13. Gensim (Commits: 2878, Contributors: 179)
It is an open-source library for Python that implements tools for work with vector space modeling and topic modeling. The library designed to be efficient with large texts, not only in-memory processing is possible. The efficiency is achieved by the using of NumPy data structures and SciPy operations extensively. It is both efficient and easy to use.
Gensim is intended for use with raw and unstructured digital texts. Gensim implements algorithms such as hierarchical Dirichlet processes (HDP), latent semantic analysis (LSA) and latent Dirichlet allocation (LDA), as well as tf-idf, random projections, word2vec and document2vec facilitate examination of texts for recurring patterns of words in the set of documents (often referred as a corpus). All of the algorithms are unsupervised — no need for any arguments, the only input is corpus.
Data Mining. Statistics.
14. Scrapy (Commits: 6325, Contributors: 243)
Scrapy is a library for making crawling programs, also known as spider bots, for retrieval of the structured data, such as contact info or URLs, from the web.
It is open-source and written in Python. It was originally designed strictly for scraping, as its name indicate, but it has evolved in the full-fledged framework with the ability to gather data from APIs and act as general-purpose crawlers.
The library follows famous Don’t Repeat Yourself in the interface design — it prompts its users to write the general, universal code that is going to be reusable, thus making building and scaling large crawlers.
The architecture of Scrapy is built around Spider class, which encapsulates the set of instruction that is followed by the crawler.
15. Statsmodels (Commits: 8960, Contributors: 119)
As you have probably guessed from the name, statsmodels is a library for Python that enables its users to conduct data exploration via the use of various methods of estimation of statistical models and performing statistical assertions and analysis.
Among many useful features are descriptive and result statistics via the use of linear regression models, generalized linear models, discrete choice models, robust linear models, time series analysis models, various estimators.
The library also provides extensive plotting functions that are designed specifically for the use in statistical analysis and tweaked for good performance with big data sets of statistical data.
Conclusions.
These are the libraries that are considered to be the top of the list by many data scientists and engineers and worth looking at them as well as at least familiarizing yourself with them.
And here are the detailed stats of Github activities for each of those libraries:

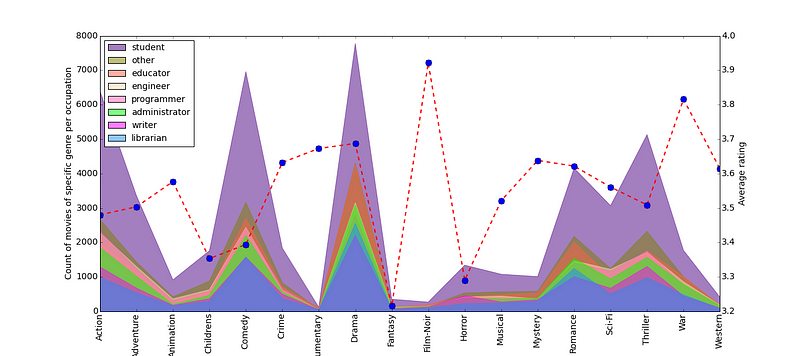
Of course, this is not the fully exhaustive list and there are many other libraries and frameworks that are also worthy and deserve proper attention for particular tasks. A great example is different packages of SciKit that focus on specific domains, like SciKit-Image for working with images.
So, if you have another useful library in mind, please let our readers know in the comments section.
The Python Standard Library
While The Python Language Reference describes the exact syntax and semantics of the Python language, this library reference manual describes the standard library that is distributed with Python. It also describes some of the optional components that are commonly included in Python distributions.
Python’s standard library is very extensive, offering a wide range of facilities as indicated by the long table of contents listed below. The library contains built-in modules (written in C) that provide access to system functionality such as file I/O that would otherwise be inaccessible to Python programmers, as well as modules written in Python that provide standardized solutions for many problems that occur in everyday programming. Some of these modules are explicitly designed to encourage and enhance the portability of Python programs by abstracting away platform-specifics into platform-neutral APIs.
The Python installers for the Windows platform usually include the entire standard library and often also include many additional components. For Unix-like operating systems Python is normally provided as a collection of packages, so it may be necessary to use the packaging tools provided with the operating system to obtain some or all of the optional components.
In addition to the standard library, there is a growing collection of several thousand components (from individual programs and modules to packages and entire application development frameworks), available from the Python Package Index.
- 1. Introduction
- 2. Built-in Functions
- 3. Built-in Constants
- 4. Built-in Types
- 4.1. Truth Value Testing
- 4.2. Boolean Operations —
and,or,not - 4.3. Comparisons
- 4.4. Numeric Types —
int,float,complex - 4.5. Iterator Types
- 4.6. Sequence Types —
list,tuple,range - 4.7. Text Sequence Type —
str - 4.8. Binary Sequence Types —
bytes,bytearray,memoryview - 4.9. Set Types —
set,frozenset - 4.10. Mapping Types —
dict - 4.11. Context Manager Types
- 4.12. Other Built-in Types
- 4.13. Special Attributes
- 5. Built-in Exceptions
- 6. Text Processing Services
- 6.1.
string— Common string operations - 6.2.
re— Regular expression operations - 6.3.
difflib— Helpers for computing deltas - 6.4.
textwrap— Text wrapping and filling - 6.5.
unicodedata— Unicode Database - 6.6.
stringprep— Internet String Preparation - 6.7.
readline— GNU readline interface - 6.8.
rlcompleter— Completion function for GNU readline
- 6.1.
- 7. Binary Data Services
- 8. Data Types
- 8.1.
datetime— Basic date and time types - 8.2.
calendar— General calendar-related functions - 8.3.
collections— Container datatypes - 8.4.
collections.abc— Abstract Base Classes for Containers - 8.5.
heapq— Heap queue algorithm - 8.6.
bisect— Array bisection algorithm - 8.7.
array— Efficient arrays of numeric values - 8.8.
weakref— Weak references - 8.9.
types— Dynamic type creation and names for built-in types - 8.10.
copy— Shallow and deep copy operations - 8.11.
pprint— Data pretty printer - 8.12.
reprlib— Alternaterepr()implementation - 8.13.
enum— Support for enumerations
- 8.1.
- 9. Numeric and Mathematical Modules
- 9.1.
numbers— Numeric abstract base classes - 9.2.
math— Mathematical functions - 9.3.
cmath— Mathematical functions for complex numbers - 9.4.
decimal— Decimal fixed point and floating point arithmetic - 9.5.
fractions— Rational numbers - 9.6.
random— Generate pseudo-random numbers - 9.7.
statistics— Mathematical statistics functions
- 9.1.
- 10. Functional Programming Modules
- 11. File and Directory Access
- 11.1.
pathlib— Object-oriented filesystem paths - 11.2.
os.path— Common pathname manipulations - 11.3.
fileinput— Iterate over lines from multiple input streams - 11.4.
stat— Interpretingstat()results - 11.5.
filecmp— File and Directory Comparisons - 11.6.
tempfile— Generate temporary files and directories - 11.7.
glob— Unix style pathname pattern expansion - 11.8.
fnmatch— Unix filename pattern matching - 11.9.
linecache— Random access to text lines - 11.10.
shutil— High-level file operations - 11.11.
macpath— Mac OS 9 path manipulation functions
- 11.1.
- 12. Data Persistence
- 13. Data Compression and Archiving
- 14. File Formats
- 15. Cryptographic Services
- 16. Generic Operating System Services
- 16.1.
os— Miscellaneous operating system interfaces - 16.2.
io— Core tools for working with streams - 16.3.
time— Time access and conversions - 16.4.
argparse— Parser for command-line options, arguments and sub-commands - 16.5.
getopt— C-style parser for command line options - 16.6.
logging— Logging facility for Python - 16.7.
logging.config— Logging configuration - 16.8.
logging.handlers— Logging handlers - 16.9.
getpass— Portable password input - 16.10.
curses— Terminal handling for character-cell displays - 16.11.
curses.textpad— Text input widget for curses programs - 16.12.
curses.ascii— Utilities for ASCII characters - 16.13.
curses.panel— A panel stack extension for curses - 16.14.
platform— Access to underlying platform’s identifying data - 16.15.
errno— Standard errno system symbols - 16.16.
ctypes— A foreign function library for Python
- 16.1.
- 17. Concurrent Execution
- 17.1.
threading— Thread-based parallelism - 17.2.
multiprocessing— Process-based parallelism - 17.3. The
concurrentpackage - 17.4.
concurrent.futures— Launching parallel tasks - 17.5.
subprocess— Subprocess management - 17.6.
sched— Event scheduler - 17.7.
queue— A synchronized queue class - 17.8.
dummy_threading— Drop-in replacement for thethreadingmodule - 17.9.
_thread— Low-level threading API - 17.10.
_dummy_thread— Drop-in replacement for the_threadmodule
- 17.1.
- 18. Interprocess Communication and Networking
- 18.1.
socket— Low-level networking interface - 18.2.
ssl— TLS/SSL wrapper for socket objects - 18.3.
select— Waiting for I/O completion - 18.4.
selectors— High-level I/O multiplexing - 18.5.
asyncio— Asynchronous I/O, event loop, coroutines and tasks - 18.6.
asyncore— Asynchronous socket handler - 18.7.
asynchat— Asynchronous socket command/response handler - 18.8.
signal— Set handlers for asynchronous events - 18.9.
mmap— Memory-mapped file support
- 18.1.
- 19. Internet Data Handling
- 19.1.
email— An email and MIME handling package - 19.2.
json— JSON encoder and decoder - 19.3.
mailcap— Mailcap file handling - 19.4.
mailbox— Manipulate mailboxes in various formats - 19.5.
mimetypes— Map filenames to MIME types - 19.6.
base64— Base16, Base32, Base64, Base85 Data Encodings - 19.7.
binhex— Encode and decode binhex4 files - 19.8.
binascii— Convert between binary and ASCII - 19.9.
quopri— Encode and decode MIME quoted-printable data - 19.10.
uu— Encode and decode uuencode files
- 19.1.
- 20. Structured Markup Processing Tools
- 20.1.
html— HyperText Markup Language support - 20.2.
html.parser— Simple HTML and XHTML parser - 20.3.
html.entities— Definitions of HTML general entities - 20.4. XML Processing Modules
- 20.5.
xml.etree.ElementTree— The ElementTree XML API - 20.6.
xml.dom— The Document Object Model API - 20.7.
xml.dom.minidom— Minimal DOM implementation - 20.8.
xml.dom.pulldom— Support for building partial DOM trees - 20.9.
xml.sax— Support for SAX2 parsers - 20.10.
xml.sax.handler— Base classes for SAX handlers - 20.11.
xml.sax.saxutils— SAX Utilities - 20.12.
xml.sax.xmlreader— Interface for XML parsers - 20.13.
xml.parsers.expat— Fast XML parsing using Expat
- 20.1.
- 21. Internet Protocols and Support
- 21.1.
webbrowser— Convenient Web-browser controller - 21.2.
cgi— Common Gateway Interface support - 21.3.
cgitb— Traceback manager for CGI scripts - 21.4.
wsgiref— WSGI Utilities and Reference Implementation - 21.5.
urllib— URL handling modules - 21.6.
urllib.request— Extensible library for opening URLs - 21.7.
urllib.response— Response classes used by urllib - 21.8.
urllib.parse— Parse URLs into components - 21.9.
urllib.error— Exception classes raised by urllib.request - 21.10.
urllib.robotparser— Parser for robots.txt - 21.11.
http— HTTP modules - 21.12.
http.client— HTTP protocol client - 21.13.
ftplib— FTP protocol client - 21.14.
poplib— POP3 protocol client - 21.15.
imaplib— IMAP4 protocol client - 21.16.
nntplib— NNTP protocol client - 21.17.
smtplib— SMTP protocol client - 21.18.
smtpd— SMTP Server - 21.19.
telnetlib— Telnet client - 21.20.
uuid— UUID objects according to RFC 4122 - 21.21.
socketserver— A framework for network servers - 21.22.
http.server— HTTP servers - 21.23.
http.cookies— HTTP state management - 21.24.
http.cookiejar— Cookie handling for HTTP clients - 21.25.
xmlrpc— XMLRPC server and client modules - 21.26.
xmlrpc.client— XML-RPC client access - 21.27.
xmlrpc.server— Basic XML-RPC servers - 21.28.
ipaddress— IPv4/IPv6 manipulation library
- 21.1.
- 22. Multimedia Services
- 22.1.
audioop— Manipulate raw audio data - 22.2.
aifc— Read and write AIFF and AIFC files - 22.3.
sunau— Read and write Sun AU files - 22.4.
wave— Read and write WAV files - 22.5.
chunk— Read IFF chunked data - 22.6.
colorsys— Conversions between color systems - 22.7.
imghdr— Determine the type of an image - 22.8.
sndhdr— Determine type of sound file - 22.9.
ossaudiodev— Access to OSS-compatible audio devices
- 22.1.
- 23. Internationalization
- 24. Program Frameworks
- 25. Graphical User Interfaces with Tk
- 26. Development Tools
- 26.1.
typing— Support for type hints - 26.2.
pydoc— Documentation generator and online help system - 26.3.
doctest— Test interactive Python examples - 26.4.
unittest— Unit testing framework - 26.5.
unittest.mock— mock object library - 26.6.
unittest.mock— getting started - 26.7. 2to3 - Automated Python 2 to 3 code translation
- 26.8.
test— Regression tests package for Python - 26.9.
test.support— Utilities for the Python test suite
- 26.1.
- 27. Debugging and Profiling
- 28. Software Packaging and Distribution
- 29. Python Runtime Services
- 29.1.
sys— System-specific parameters and functions - 29.2.
sysconfig— Provide access to Python’s configuration information - 29.3.
builtins— Built-in objects - 29.4.
__main__— Top-level script environment - 29.5.
warnings— Warning control - 29.6.
contextlib— Utilities forwith-statement contexts - 29.7.
abc— Abstract Base Classes - 29.8.
atexit— Exit handlers - 29.9.
traceback— Print or retrieve a stack traceback - 29.10.
__future__— Future statement definitions - 29.11.
gc— Garbage Collector interface - 29.12.
inspect— Inspect live objects - 29.13.
site— Site-specific configuration hook - 29.14.
fpectl— Floating point exception control
- 29.1.
- 30. Custom Python Interpreters
- 31. Importing Modules
- 32. Python Language Services
- 32.1.
parser— Access Python parse trees - 32.2.
ast— Abstract Syntax Trees - 32.3.
symtable— Access to the compiler’s symbol tables - 32.4.
symbol— Constants used with Python parse trees - 32.5.
token— Constants used with Python parse trees - 32.6.
keyword— Testing for Python keywords - 32.7.
tokenize— Tokenizer for Python source - 32.8.
tabnanny— Detection of ambiguous indentation - 32.9.
pyclbr— Python class browser support - 32.10.
py_compile— Compile Python source files - 32.11.
compileall— Byte-compile Python libraries - 32.12.
dis— Disassembler for Python bytecode - 32.13.
pickletools— Tools for pickle developers
- 32.1.
- 33. Miscellaneous Services
- 34. MS Windows Specific Services
- 35. Unix Specific Services
- 35.1.
posix— The most common POSIX system calls - 35.2.
pwd— The password database - 35.3.
spwd— The shadow password database - 35.4.
grp— The group database - 35.5.
crypt— Function to check Unix passwords - 35.6.
termios— POSIX style tty control - 35.7.
tty— Terminal control functions - 35.8.
pty— Pseudo-terminal utilities - 35.9.
fcntl— Thefcntlandioctlsystem calls - 35.10.
pipes— Interface to shell pipelines - 35.11.
resource— Resource usage information - 35.12.
nis— Interface to Sun’s NIS (Yellow Pages) - 35.13.
syslog— Unix syslog library routines
- 35.1.
- 36. Superseded Modules
- 37. Undocumented Modules
Misc Python packages and modules
I created these modules when I could not find existing ones with the same
functionality (but I can be wrong) or when it didn't match my needs.
They might be useful to other Pythoners.
Warning (March 2006): these modules are now pretty much outdated. glock.py and getargs.py might still be of some interest, though.
| Package | Description |
|---|---|
| rgutils | Misc utilities modules (also detailed below) |
| scf | Simple Corba Framework. |
The following modules are bundled in the package rgutils, but also available separately :
| Module | Description |
|---|---|
| async.py | Asynchronous function calls utility (so far, only a timed out function call). |
| getargs.py | (Yet Another getopt) Parse command line arguments (updated March 2006) |
| process.py | Simple process management. Allows to launch, kill and see the status of a process independently from the platform (at least on Win32 and Unix). |
| dataxfer.py | Functions for transfering arbitrary sized data in a distributed (client/server) environment via a FTP server. |
| glock.py | Global (inter-process) mutex on Windows and Unix. |
| pool.py | Resource pool management. |
| message.py | Representation of an e-mail.
Used by imap.py and pop3.py. |
| imap.py | Utilities for reading IMAP mail. |
| pop3.py | Utilities for reading POP3 mail. |
| fwdmail.py | Script for forwarding IMAP or POP mail. |
| platform.py | Platform information.
This one was written by Marc-Andre Lemburg
(mal@lemburg.com), I have included it
here because it is used by some of my modules. NB: this module is now part of Python 2.3+ std distribution. |