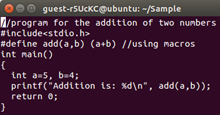
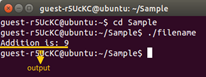
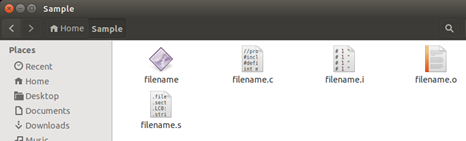
Explanation And Approach:
#include<stdio.h>
#include<stdlib.h>
int main()
{
char str[] = "12abc12";
int alphabet = 0, number = 0, i;
for (i=0; str[i]!= '\0'; i++)
{
if (isalpha(str[i]) != 0)
alphabet++;
else if (isdigit(str[i]) != 0)
number++;
}
printf("Alphabetic_letters = %d, "
"Decimal_digits = %d\n", alphabet, number);
return 0;
}
Output:
Alphabetic_letters = 3, Decimal_digits = 4
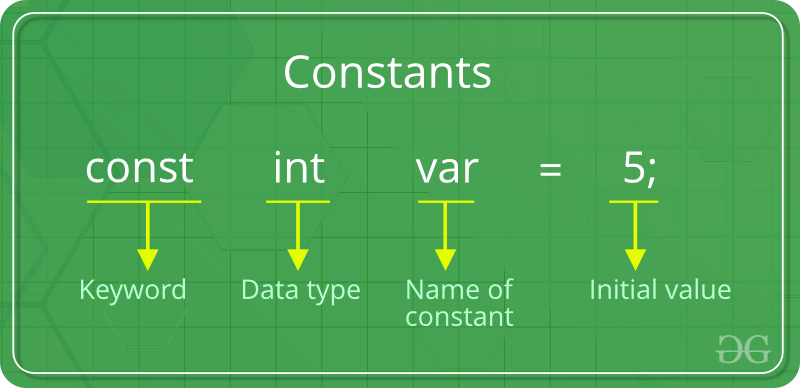
Data type of case labels of switch statement in C++?
In C++ switch statement, the expression of each case label must be an integer constant expression.
For example, the following program fails in compilation.
#include<stdio.h>
int main()
{
int i = 10;
int c = 10;
switch(c)
{
case i:
printf("Value of c = %d", c);
break;
}
return 0;
}
Putting
const before
i makes the above program work.
#include<stdio.h>
int main()
{
const int i = 10;
int c = 10;
switch(c)
{
case i:
printf("Value of c = %d", c);
break;
}
return 0;
}
Note : The above fact is only for C++.
In C, both programs produce an error.
In C, using an integer literal does not cause an error.
Program to find the largest number between two numbers using switch case:
#include<stdio.h>
int main()
{
int n1=10,n2=11;
switch((int)(n1 > n2))
{
case 0:
printf("%d is the largest\n", n2);
break;
default:
printf("%d is the largest\n", n1);
}
switch((int)(n1 < n2))
{
case 0:
printf("%d is the largest\n", n1);
break;
default:
printf("%d is the largest\n", n2);
}
return 0;
}
For Versus While
Question: Is there any example for which the following two loops will not work same way?
for (<init-stmnt>; <boolean-expr>; <incr-stmnt>)
{
<body-statements>
}
<init-stmnt>;
while (<boolean-expr>)
{
<body-statements>
<incr-stmnt>
}
Solution:
If the body-statements contains continue, then the two programs will work in different ways
See the below examples: Program 1 will print “loop” 3 times but Program 2 will go in an infinite loop.
Example for program 1
int main()
{
int i = 0;
for(i = 0; i < 3; i++)
{
printf("loop ");
continue;
}
getchar();
return 0;
}
Example for program 2
int main()
{
int i = 0;
while(i < 3)
{
printf("loop");
continue;
i++;
}
getchar();
return 0;
}
Please write comments if you want to add more solutions for the above question.
A nested loop puzzle
Which of the following two code segments is faster? Assume that compiler makes no optimizations.
for(i=0;i<10;i++)
for(j=0;j<100;j++)
for(i=0;i<100;i++)
for(j=0;j<10;j++)
Both code segments provide same functionality, and the code inside the two for loops would be executed same number of times in both code segments.
If we take a closer look then we can see that the SECOND does more operations than the FIRST.
It executes all three parts (assignment, comparison and increment) of the for loop more times than the corresponding parts of FIRST:
- The SECOND executes assignment operations ( j = 0 or i = 0) 101 times while FIRST executes only 11 times.
- The SECOND does 101 + 1100 comparisons (i < 100 or j < 10) while the FIRST does 11 + 1010 comparisons (i < 10 or j < 100).
- The SECOND executes 1100 increment operations (i++ or j++) while the FIRST executes 1010 increment operation.
Below C++ code counts the number of increment operations executed in FIRST and SECOND, and prints the counts.
#include<iostream>
using namespace std;
int main()
{
int c1 = 0, c2 = 0;
for(int i=0;i<10;i++,c1++)
for(int j=0;j<100;j++, c1++);
for(int i=0; i<100; i++, c2++)
for(int j=0; j<10; j++, c2++);
cout << " Count in FIRST = " <<c1 << endl;
cout << " Count in SECOND = " <<c2 << endl;
getchar();
return 0;
}
Output:
Count in FIRST = 1010
Count in SECOND = 1100
Below C++ code counts the number of comparison operations executed by FIRST and SECOND
#include<iostream>
using namespace std;
int main()
{
int c1 = 0, c2 = 0;
for(int i=0; ++c1&&i<10; i++)
for(int j=0; ++c1&&j<100;j++);
for(int i=0; ++c2&&i<100; i++)
for(int j=0; ++c2&&j<10; j++);
cout << " Count fot FIRST " <<c1 << endl;
cout << " Count fot SECOND " <<c2 << endl;
getchar();
return 0;
}
Output:
Count fot FIRST 1021
Count fot SECOND 1201
Thanks to
Dheeraj for suggesting the solution.
Please write comments if you find any of the answers/codes incorrect, or you want to share more information about the topics discussed above.
Interesting facts about switch statement in C
Prerequisite –
Switch Statement in C
Switch is a control statement that allows a value to change control of execution.
#include <stdio.h>
int main()
{
int x = 2;
switch (x)
{
case 1: printf("Choice is 1");
break;
case 2: printf("Choice is 2");
break;
case 3: printf("Choice is 3");
break;
default: printf("Choice other than 1, 2 and 3");
break;
}
return 0;
}
Output:
Choice is 2
Following are some interesting facts about switch statement.
1) The expression used in switch must be integral type ( int, char and enum). Any other type of expression is not allowed.
#include <stdio.h>
int main()
{
float x = 1.1;
switch (x)
{
case 1.1: printf("Choice is 1");
break;
default: printf("Choice other than 1, 2 and 3");
break;
}
return 0;
}
Output:
Compiler Error: switch quantity not an integer
In Java, String is also allowed in switch (See
this)
2) All the statements following a matching case execute until a break statement is reached.
#include <stdio.h>
int main()
{
int x = 2;
switch (x)
{
case 1: printf("Choice is 1\n");
case 2: printf("Choice is 2\n");
case 3: printf("Choice is 3\n");
default: printf("Choice other than 1, 2 and 3\n");
}
return 0;
}
Output:
Choice is 2
Choice is 3
Choice other than 1, 2 and 3
#include <stdio.h>
int main()
{
int x = 2;
switch (x)
{
case 1: printf("Choice is 1\n");
case 2: printf("Choice is 2\n");
case 3: printf("Choice is 3\n");
case 4: printf("Choice is 4\n");
break;
default: printf("Choice other than 1, 2, 3 and 4\n");
break;
}
printf("After Switch");
return 0;
}
Output:
Choice is 2
Choice is 3
Choice is 4
After Switch
3) The default block can be placed anywhere. The position of default doesn’t matter, it is still executed if no match found.
#include <stdio.h>
int main()
{
int x = 4;
switch (x)
{
default: printf("Choice other than 1 and 2");
break;
case 1: printf("Choice is 1");
break;
case 2: printf("Choice is 2");
break;
}
return 0;
}
Output:
Choice other than 1 and 2
4) The integral expressions used in labels must be a constant expressions
#include <stdio.h>
int main()
{
int x = 2;
int arr[] = {1, 2, 3};
switch (x)
{
case arr[0]: printf("Choice 1\n");
case arr[1]: printf("Choice 2\n");
case arr[2]: printf("Choice 3\n");
}
return 0;
}
Output:
Compiler Error: case label does not reduce to an integer constant
5) The statements written above cases are never executed After the switch statement, the control transfers to the matching case, the statements written before case are not executed.
#include <stdio.h>
int main()
{
int x = 1;
switch (x)
{
x = x + 1;
case 1: printf("Choice is 1");
break;
case 2: printf("Choice is 2");
break;
default: printf("Choice other than 1 and 2");
break;
}
return 0;
}
Output:
Choice is 1
6) Two case labels cannot have same value
#include <stdio.h>
int main()
{
int x = 1;
switch (x)
{
case 2: printf("Choice is 1");
break;
case 1+1: printf("Choice is 2");
break;
}
return 0;
}
Output:
Compiler Error: duplicate case value
Difference between while(1) and while(0) in C language
Prerequisite:
while loop in C/C++
In most computer programming languages, a while loop is a control flow statement that allows code to be executed repeatedly based on a given boolean condition.
The boolean condition is either true or false
while(1)
It is an infinite loop which will run till a break statement is issued explicitly.
Interestingly not while(1) but any integer which is non-zero will give the similar effect as while(1).
Therefore, while(1), while(2) or while(-255), all will give infinite loop only.
while(1) or while(any non-zero integer)
{
// loop runs infinitely
}
A simple usage of while(1) can be in the Client-Server program.
In the program, the server runs in an infinite while loop to receive the packets sent from the clients.
But practically, it is not advisable to use while(1) in real-world because it increases the CPU usage and also blocks the code i.e one cannot come out from the while(1) until the program is closed manually.
while(1) can be used at a place where condition needs to be true always.
C
int main()
{
int i = 0;
while ( 1 )
{
printf( "%d\n", ++i );
if (i == 5)
break;
}
return 0;
}
C++
#include <iostream>
using namespace std;
int main() {
int i = 0;
while ( 1 )
{
cout << ++i << "\n";
if (i == 5)
break;
}
return 0;
}
Output:
1
2
3
4
5
while(0)
It is opposite of while(1).
It means condition will always be false and thus code in while will never get executed.
while(0)
{
// loop does not run
}
C
int main()
{
int i = 0, flag=0;
while ( 0 )
{
printf( "%d\n", ++i );
flag++;
if (i == 5)
break;
}
if (flag==0)
printf ("Didn't execute the loop!");
return 0;
}
C++
#include <iostream>
using namespace std;
int main() {
int i = 0, flag=0;
while ( 0 )
{
cout << ++i << "\n";
flag++;
if (i == 5)
break;
}
if (flag==0)
cout << "Didn't execute the loop!";
return 0;
}
Output:
Didn't execute the loop!
goto statement in C/C++
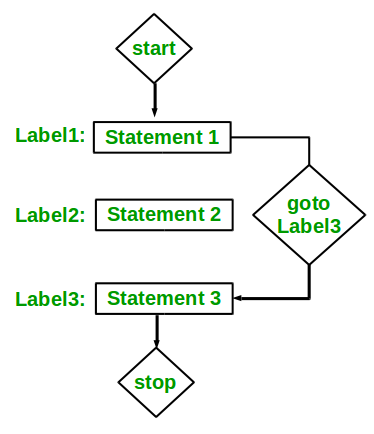
The goto statement is a jump statement which is sometimes also referred to as unconditional jump statement.
The goto statement can be used to jump from anywhere to anywhere within a function.
Syntax:
Syntax1 | Syntax2
----------------------------
goto label; | label:
.
| .
.
| .
.
| .
label: | goto label;
In the above syntax, the first line tells the compiler to go to or jump to the statement marked as a label.
Here label is a user-defined identifier which indicates the target statement.
The statement immediately followed after ‘label:’ is the destination statement.
The ‘label:’ can also appear before the ‘goto label;’ statement in the above syntax.
Below are some examples on how to use goto statement:
Examples:
-
Type 1: In this case, we will see a situation similar to as shown in Syntax1 above.
Suppose we need to write a program where we need to check if a number is even or not and print accordingly using the goto statement.
Below program explains how to do this:
C
#include <stdio.h>
void checkEvenOrNot(int num)
{
if (num % 2 == 0)
goto even;
else
goto odd;
even:
printf("%d is even", num);
return;
odd:
printf("%d is odd", num);
}
int main() {
int num = 26;
checkEvenOrNot(num);
return 0;
}
C++
#include <iostream>
using namespace std;
void checkEvenOrNot(int num)
{
if (num % 2 == 0)
goto even;
else
goto odd;
even:
cout << num << " is even";
return;
odd:
cout << num << " is odd";
}
int main()
{
int num = 26;
checkEvenOrNot(num);
return 0;
}
Output:
26 is even
-
Type 2:: In this case, we will see a situation similar to as shown in Syntax1 above.
Suppose we need to write a program which prints numbers from 1 to 10 using the goto statement.
Below program explains how to do this.
C
#include <stdio.h>
void printNumbers()
{
int n = 1;
label:
printf("%d ",n);
n++;
if (n <= 10)
goto label;
}
int main() {
printNumbers();
return 0;
}
C++
#include <iostream>
using namespace std;
void printNumbers()
{
int n = 1;
label:
cout << n << " ";
n++;
if (n <= 10)
goto label;
}
int main()
{
printNumbers();
return 0;
}
Output:
1 2 3 4 5 6 7 8 9 10
Disadvantages of using goto statement:
- The use of goto statement is highly discouraged as it makes the program logic very complex.
- use of goto makes the task of analyzing and verifying the correctness of programs (particularly those involving loops) very difficult.
- Use of goto can be simply avoided using break and continue statements.
Continue Statement in C/C++
Continue is also a loop control statement just like the
break statement.
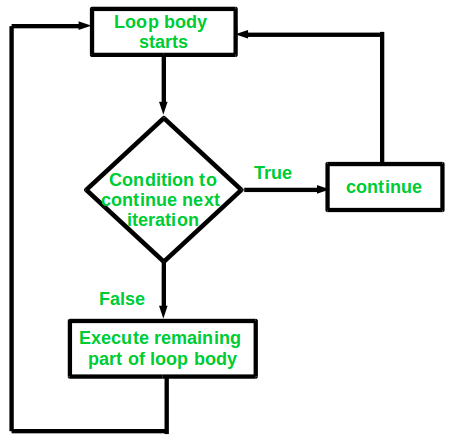
continue statement is opposite to that of break
statement, instead of terminating the loop, it forces to execute the next iteration of the loop.
As the name suggest the continue statement forces the loop to continue or execute the next iteration.
When the continue statement is executed in the loop, the code inside the loop following the continue statement will be skipped and next iteration of the loop will begin.
Syntax:
continue;
 Example
Example:
Consider the situation when you need to write a program which prints number from 1 to 10 and but not 6.
It is specified that you have to do this using loop and only one loop is allowed to use.
Here comes the usage of continue statement.
What we can do here is we can run a loop from 1 to 10 and every time we have to compare the value of iterator with 6.
If it is equal to 6 we will use the
continue statement to continue to next iteration without printing anything otherwise we will print the value.
Below is the implementation of the above idea:
C
#include <stdio.h>
int main() {
for (int i = 1; i <= 10; i++) {
if (i == 6)
continue;
else
printf("%d ", i);
}
return 0;
}
C++
#include <iostream>
using namespace std;
int main()
{
for (int i = 1; i <= 10; i++) {
if (i == 6)
continue;
else
cout << i << " ";
}
return 0;
}
Output:
1 2 3 4 5 7 8 9 10
The
continue statement can be used with any other loop also like while or do while in a similar way as it is used with for loop above.
Exercise Problem:
Given a number n, print triangular pattern.
We are allowed to use only one loop.
Input: 7
Output:
*
* *
* * *
* * * *
* * * * *
* * * * * *
* * * * * * *
Solution :
Print the pattern by using one loop | Set 2 (Using Continue Statement)
Break Statement in C/C++
The break in C or C++ is a loop control statement which is used to terminate the loop.
As soon as the break statement is encountered from within a loop, the loop iterations stops there and control returns from the loop immediately to the first statement after the loop.
Syntax:
break;
Basically break statements are used in the situations when we are not sure about the actual number of iterations for the loop or we want to terminate the loop based on some condition.
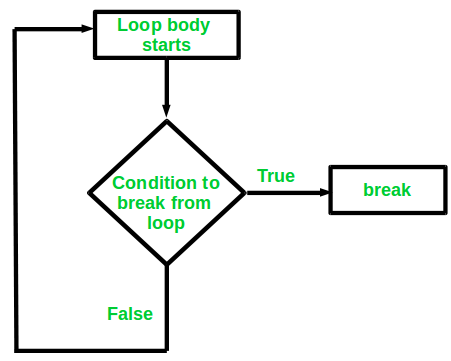 We will see here the usage of break statement with three different types of loops:
We will see here the usage of break statement with three different types of loops:
- Simple loops
- Nested loops
- Infinite loops
Let us now look at the examples for each of the above three types of loops using break statement.
- Simple loops: Consider the situation where we want to search an element in an array.
To do this, use a loop to traverse the array starting from the first index and compare the array elements with the given key.
Below is the implementation of this idea:
C
#include <stdio.h>
void findElement(int arr[], int size, int key)
{
for (int i = 0; i < size; i++) {
if (arr[i] == key) {
printf("Element found at position: %d", (i + 1));
}
}
}
int main() {
int arr[] = { 1, 2, 3, 4, 5, 6 };
int n = 6;
int key = 3;
findElement(arr, n, key);
return 0;
}
C++
#include <iostream>
using namespace std;
void findElement(int arr[], int size, int key)
{
for (int i = 0; i < size; i++) {
if (arr[i] == key) {
cout << "Element found at position: " << (i + 1);
}
}
}
int main()
{
int arr[] = { 1, 2, 3, 4, 5, 6 };
int n = 6;
int key = 3;
findElement(arr, n, key);
return 0;
}
Output:
Element found at index: 3
The above code runs fine with no errors.
But the above code is not efficient.
The above code completes all the iterations even after the element is found.
Suppose there are 1000 elements in the array and the key to be searched is present at 1st position so the above approach will execute 999 iterations which are of no purpose and are useless.
To avoid these useless iterations, we can use the break statement in our program.
Once the break statement is encountered the control from the loop will return immediately after the condition gets satisfied.
So will use the break statement with the if condition which compares the key with array elements as shown below:
C
#include <stdio.h>
void findElement(int arr[], int size, int key)
{
for (int i = 0; i < size; i++) {
if (arr[i] == key) {
printf("Element found at position: %d", (i + 1));
break;
}
}
}
int main() {
int arr[] = { 1, 2, 3, 4, 5, 6 };
int n = 6;
int key = 3;
findElement(arr, n, key);
return 0;
}
C++
#include <iostream>
using namespace std;
void findElement(int arr[], int size, int key)
{
for (int i = 0; i < size; i++) {
if (arr[i] == key) {
cout << "Element found at position: " << (i + 1);
break;
}
}
}
int main()
{
int arr[] = { 1, 2, 3, 4, 5, 6 };
int n = 6;
int key = 3;
findElement(arr, n, key);
return 0;
}
Output:
Element found at position: 3
- Nested Loops: We can also use break statement while working with nested loops.
If the break statement is used in the innermost loop.
The control will come out only from the innermost loop.
Below is the example of using break with nested loops:
C
#include <stdio.h>
int main() {
for (int i = 0; i < 5; i++) {
for (int j = 1; j <= 10; j++) {
if (j > 3)
break;
else
printf("*");
}
printf("\n");
}
return 0;
}
C++
#include <iostream>
using namespace std;
int main()
{
for (int i = 0; i < 5; i++) {
for (int j = 1; j <= 10; j++) {
if (j > 3)
break;
else
cout << "*";
}
cout << endl;
}
return 0;
}
Output:
***
***
***
***
***
In the above code we can clearly see that the inner loop is programmed to execute for 10 iterations.
But as soon as the value of j becomes greater than 3 the inner loop stops executing which restricts the number of iteration of the inner loop to 3 iterations only.
However the iteration of outer loop remains unaffected.
Therefore, break applies to only the loop within which it is present.
-
Infinite Loops: break statement can be included in an infinite loop with a condition in order to terminate the execution of the infinite loop.
Consider the below infinite loop:
C
#include <stdio.h>
int main() {
int i = 0;
while (1) {
printf("%d ", i);
i++;
}
return 0;
}
C++
#include <iostream>
using namespace std;
int main()
{
int i = 0;
while (1) {
cout << i << " ";
i++;
}
return 0;
}
Note: Please donot run the above program in your compiler as it is an infinite loop so you may have to forcefully exit the compiler to terminate the program.
In the above program, the loop condition based on which the loop terminates is always true.
So, the loop executes infinite number of times.
We can correct this by using the break statement as shown below:
C
#include <stdio.h>
int main() {
int i = 1;
while (1) {
if (i > 10)
break;
printf("%d ", i);
i++;
}
return 0;
}
C++
#include <iostream>
using namespace std;
int main()
{
int i = 1;
while (1) {
if (i > 10)
break;
cout << i << " ";
i++;
}
return 0;
}
Output:
1 2 3 4 5 6 7 8 9 10
The above code restricts the number of loop iterations to 10.
Apart from this, break can be used in Switch case statements too.
Using range in switch case in C/C++
You all are familiar with
switch case in C/C++, but did you know
you can use range of numbers instead of a single number or character in case statement.
#include <stdio.h>
int main()
{
int arr[] = { 1, 5, 15, 20 };
for (int i = 0; i < 4; i++)
{
switch (arr[i])
{
case 1 ...
6:
printf("%d in range 1 to 6\n", arr[i]);
break;
case 19 ...
20:
printf("%d in range 19 to 20\n", arr[i]);
break;
default:
printf("%d not in range\n", arr[i]);
break;
}
}
return 0;
}
Output:
1 in range 1 to 6
5 in range 1 to 6
15 not in range
20 in range 19 to 20
Exercise : You can try above program for char array by modifying char array and case statement.
Error conditions:
- low > high : The compiler gives with an error message.
- Overlapping case values : If the value of a case label is within a case range that has already been used in the switch statement, the compiler gives an error message.
Functions in C/C++
A function is a set of statements that take inputs, do some specific computation and produces output.
The idea is to put some commonly or repeatedly done task together and make a function so that instead of writing the same code again and again for different inputs, we can call the function.
Example:
Below is a simple C/C++ program to demonstrate functions.
C
#include <stdio.h>
int max(int x, int y)
{
if (x > y)
return x;
else
return y;
}
int main(void)
{
int a = 10, b = 20;
int m = max(a, b);
printf("m is %d", m);
return 0;
}
C++
#include <iostream>
using namespace std;
int max(int x, int y)
{
if (x > y)
return x;
else
return y;
}
int main() {
int a = 10, b = 20;
int m = max(a, b);
cout << "m is " << m;
return 0;
}
Output:
m is 20
Why do we need functions?
- Functions help us in reducing code redundancy.
If functionality is performed at multiple places in software, then rather than writing the same code, again and again, we create a function and call it everywhere.
This also helps in maintenance as we have to change at one place if we make future changes to the functionality.
- Functions make code modular.
Consider a big file having many lines of codes.
It becomes really simple to read and use the code if the code is divided into functions.
- Functions provide abstraction.
For example, we can use library functions without worrying about their internal working.
Function Declaration
A function declaration tells the compiler about the number of parameters function takes, data-types of parameters and return type of function.
Putting parameter names in function declaration is optional in the function declaration, but it is necessary to put them in the definition.
Below are an example of function declarations.
(parameter names are not there in below declarations)
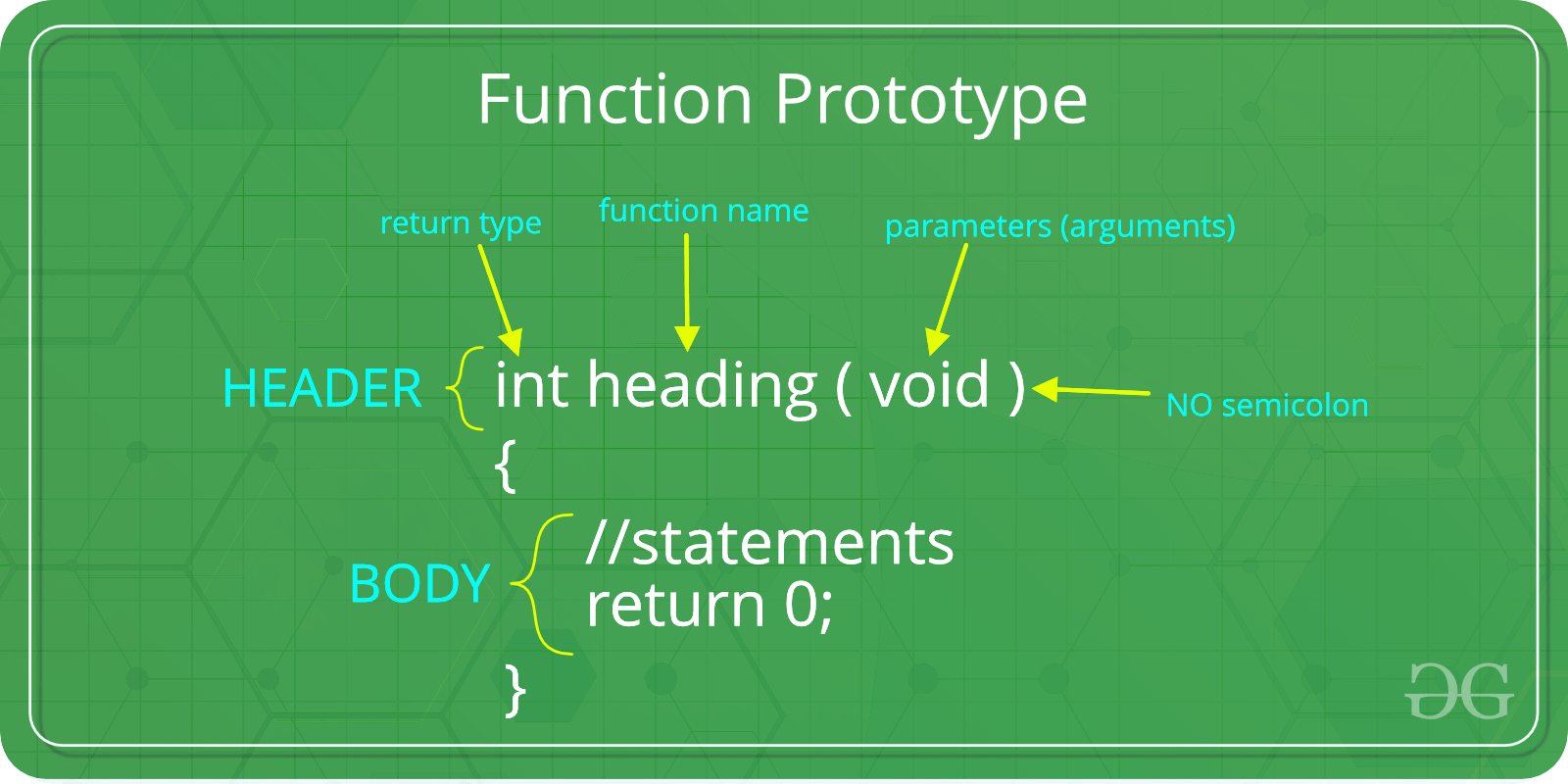
int max(int, int);
int *swap(int*,int);
char *call(char b);
int fun(char, int);
It is always recommended to declare a function before it is used (See
this,
this and
this for details)
In C, we can do both declaration and definition at the same place, like done in the above example program.
C also allows to declare and define functions separately, this is especially needed in case of library functions.
The library functions are declared in header files and defined in library files.
Below is an example declaration.
Parameter Passing to functions
The parameters passed to function are called
actual parameters.
For example, in the above program 10 and 20 are actual parameters.
The parameters received by function are called
formal parameters.
For example, in the above program x and y are formal parameters.
There are two most popular ways to pass parameters.
Pass by Value: In this parameter passing method, values of actual parameters are copied to function’s formal parameters and the two types of parameters are stored in different memory locations.
So any changes made inside functions are not reflected in actual parameters of caller.
Pass by Reference Both actual and formal parameters refer to same locations, so any changes made inside the function are actually reflected in actual parameters of caller.
In C, parameters are always passed by value.
Parameters are always passed by value in C.
For example.
in the below code, value of x is not modified using the function fun().
C
#include <stdio.h>
void fun(int x)
{
x = 30;
}
int main(void)
{
int x = 20;
fun(x);
printf("x = %d", x);
return 0;
}
C++
#include <iostream>
using namespace std;
void fun(int x) {
x = 30;
}
int main() {
int x = 20;
fun(x);
cout << "x = " << x;
return 0;
}
Output:
x = 20
However, in C, we can use pointers to get the effect of pass by reference.
For example, consider the below program.
The function fun() expects a pointer ptr to an integer (or an address of an integer).
It modifies the value at the address ptr.
The dereference operator * is used to access the value at an address.
In the statement ‘*ptr = 30’, value at address ptr is changed to 30.
The address operator & is used to get the address of a variable of any data type.
In the function call statement ‘fun(&x)’, the address of x is passed so that x can be modified using its address.
C
# include <stdio.h>
void fun(int *ptr)
{
*ptr = 30;
}
int main()
{
int x = 20;
fun(&x);
printf("x = %d", x);
return 0;
}
C++
#include <iostream>
using namespace std;
void fun(int *ptr)
{
*ptr = 30;
}
int main() {
int x = 20;
fun(&x);
cout << "x = " << x;
return 0;
}
Output:
x = 30
Following are some important points about functions in C.
1) Every C program has a function called main() that is called by operating system when a user runs the program.
2) Every function has a return type.
If a function doesn’t return any value, then void is used as return type.
Moreover, if the return type of the function is void, we still can use return statement in the body of function definition by not specifying any constant, variable, etc.
with it, by only mentioning the ‘return;’ statement which would symbolise the termination of the function as shown below:
void function name(int a)
{
.......
return;
}
3) In C, functions can return any type except arrays and functions.
We can get around this limitation by returning pointer to array or pointer to function.
4) Empty parameter list in C mean that the parameter list is not specified and function can be called with any parameters.
In C, it is not a good idea to declare a function like fun().
To declare a function that can only be called without any parameter, we should use “void fun(void)”.
As a side note, in C++, empty list means function can only be called without any parameter.
In C++, both void fun() and void fun(void) are same.
5)If in a C program, a function is called before its declaration then the C compiler automatically assumes the declaration of that function in the following way:
int function name();
And in that case if the return type of that function is different than INT ,compiler would show an error.
More on Functions in C/C++:
Importance of function prototype in C
Function prototype tells compiler about number of parameters function takes, data-types of parameters and return type of function.
By using this information, compiler cross checks function parameters and their data-type with function definition and function call.
If we ignore function prototype, program may compile with warning, and may work properly.
But some times, it will give strange output and it is very hard to find such programming mistakes.
Let us see with examples
#include <errno.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
FILE *fp;
fp = fopen(argv[1], "r");
if (fp == NULL) {
fprintf(stderr, "%s\n", strerror(errno));
return errno;
}
printf("file exist\n");
fclose(fp);
return 0;
}
Above program checks existence of file, provided from command line, if given file is exist, then the program prints “file exist”, otherwise it prints appropriate error message.
Let us provide a filename, which does not exist in file system, and check the output of program on x86_64 architecture.
[narendra@/media/partition/GFG]$ ./file_existence hello.c
Segmentation fault (core dumped)
Why this program crashed, instead it should show appropriate error message.
This program will work fine on x86 architecture, but will crash on x86_64 architecture.
Let us see what was wrong with code.
Carefully go through the program, deliberately I haven’t included prototype of “strerror()” function.
This function returns “pointer to character”, which will print error message which depends on errno passed to this function.
Note that x86 architecture is ILP-32 model, means integer, pointers and long are 32-bit wide, that’s why program will work correctly on this architecture.
But x86_64 is LP-64 model, means long and pointers are 64 bit wide.
In C language, when we don’t provide prototype of function, the compiler assumes that function returns an integer.
In our example, we haven’t included “string.h” header file (strerror’s prototype is declared in this file), that’s why compiler assumed that function returns integer.
But its return type is pointer to character.
In x86_64, pointers are 64-bit wide and integers are 32-bits wide, that’s why while returning from function, the returned address gets truncated (i.e.
32-bit wide address, which is size of integer on x86_64) which is invalid and when we try to dereference this address, the result is segmentation fault.
Now include the “string.h” header file and check the output, the program will work correctly.
[narendra@/media/partition/GFG]$ ./file_existence hello.c
No such file or directory
Consider one more example.
#include <stdio.h>
int main(void)
{
int *p = malloc(sizeof(int));
if (p == NULL) {
perror("malloc()");
return -1;
}
*p = 10;
free(p);
return 0;
}
Above code will work fine on IA-32 model, but will fail on IA-64 model.
Reason for failure of this code is we haven’t included prototype of malloc() function and returned value is truncated in IA-64 model.
Functions that are executed before and after main() in C
With GCC family of C compilers, we can mark some functions to execute before and after main().
So some startup code can be executed before main() starts, and some cleanup code can be executed after main() ends.
For example, in the following program, myStartupFun() is called before main() and myCleanupFun() is called after main().
#include<stdio.h>
void myStartupFun (void) __attribute__ ((constructor));
void myCleanupFun (void) __attribute__ ((destructor));
void myStartupFun (void)
{
printf ("startup code before main()\n");
}
void myCleanupFun (void)
{
printf ("cleanup code after main()\n");
}
int main (void)
{
printf ("hello\n");
return 0;
}
Output:
startup code before main()
hello
cleanup code after main()
Like the above feature, GCC has added many other interesting features to standard C language.
See
this for more details.
Related Article :
Executing main() in C – behind the scene
return statement vs exit() in main()
In C++, what is the difference between
exit(0) and
return 0 ?
When
exit(0) is used to exit from program, destructors for locally scoped non-static objects are not called.
But destructors are called if return 0 is used.
Program 1 – – uses exit(0) to exit
#include<iostream>
#include<stdio.h>
#include<stdlib.h>
using namespace std;
class Test {
public:
Test() {
printf("Inside Test's Constructor\n");
}
~Test(){
printf("Inside Test's Destructor");
getchar();
}
};
int main() {
Test t1;
exit(0);
}
Output:
Inside Test’s Constructor
Program 2 – uses return 0 to exit
#include<iostream>
#include<stdio.h>
#include<stdlib.h>
using namespace std;
class Test {
public:
Test() {
printf("Inside Test's Constructor\n");
}
~Test(){
printf("Inside Test's Destructor");
}
};
int main() {
Test t1;
return 0;
}
Output:
Inside Test’s Constructor
Inside Test’s Destructor
Calling destructors is sometimes important, for example, if destructor has code to release resources like closing files.
Note that static objects will be cleaned up even if we call exit().
For example, see following program.
#include<iostream>
#include<stdio.h>
#include<stdlib.h>
using namespace std;
class Test {
public:
Test() {
printf("Inside Test's Constructor\n");
}
~Test(){
printf("Inside Test's Destructor");
getchar();
}
};
int main() {
static Test t1;
exit(0);
}
Output:
Inside Test’s Constructor
Inside Test’s Destructor
How to Count Variable Numbers of Arguments in C?
C supports variable numbers of arguments.
But there is no language provided way for finding out total number of arguments passed.
User has to handle this in one of the following ways:
1) By passing first argument as count of arguments.
2) By passing last argument as NULL (or 0).
3) Using some printf (or scanf) like mechanism where first argument has placeholders for rest of the arguments.
Following is an example that uses first argument
arg_count to hold count of other arguments.
#include <stdarg.h>
#include <stdio.h>
int min(int arg_count, ...)
{
int i;
int min, a;
va_list ap;
va_start(ap, arg_count);
min = va_arg(ap, int);
for(i = 2; i <= arg_count; i++) {
if((a = va_arg(ap, int)) < min)
min = a;
}
va_end(ap);
return min;
}
int main()
{
int count = 5;
printf("Minimum value is %d", min(count, 12, 67, 6, 7, 100));
getchar();
return 0;
}
Output:
Minimum value is 6
What is evaluation order of function parameters in C?
It is compiler dependent in C.
It is never safe to depend on the order of evaluation of side effects.
For example, a function call like below may very well behave differently from one compiler to another:
void func (int, int);
int i = 2;
func (i++, i++);
There is no guarantee (in either the C or the C++ standard language definitions) that the increments will be evaluated in any particular order.
Either increment might happen first.
func might get the arguments `2, 3′, or it might get `3, 2′, or even `2, 2′.
Source:
http://gcc.gnu.org/onlinedocs/gcc/Non_002dbugs.html
Does C support function overloading?
First of all, what is function overloading? Function overloading is a feature of a programming language that allows one to have many functions with same name but with different signatures.
This feature is present in most of the Object Oriented Languages such as C++ and Java.
But C (not Object Oriented Language) doesn’t support this feature.
However, one can achieve the similar functionality in C indirectly.
One of the approach is as follows.
Have a void * type of pointer as an argument to the function.
And another argument telling the actual data type of the first argument that is being passed.
int foo(void * arg1, int arg2);
Suppose, arg2 can be interpreted as follows.
0 = Struct1 type variable, 1 = Struct2 type variable etc.
Here Struct1 and Struct2 are user defined struct types.
While calling the function foo at different places…
foo(arg1, 0); /*Here, arg1 is pointer to struct type Struct1 variable*/
foo(arg1, 1); /*Here, arg1 is pointer to struct type Struct2 variable*/
Since the second argument of the foo keeps track the data type of the first type, inside the function foo, one can get the actual data type of the first argument by typecast accordingly.
i.e.
inside the foo function
if(arg2 == 0)
{
struct1PtrVar = (Struct1 *)arg1;
}
else if(arg2 == 1)
{
struct2PtrVar = (Struct2 *)arg1;
}
else
{
}
There can be several other ways of implementing function overloading in C.
But all of them will have to use pointers – the most powerful feature of C.
In fact, it is said that without using the pointers, one can’t use C efficiently & effectively in a real world program!
How can I return multiple values from a function?
We all know that a function in C can return only one value.
So how do we achieve the purpose of returning multiple values.
Well, first take a look at the declaration of a function.
int foo(int arg1, int arg2);
So we can notice here that our interface to the function is through arguments and return value only.
(Unless we talk about modifying the globals inside the function)
Let us take a deeper look…Even though a function can return only one value but that value can be of pointer type.
That’s correct, now you’re speculating right!
We can declare the function such that, it returns a structure type user defined variable or a pointer to it .
And by the property of a structure, we know that a structure in C can hold multiple values of asymmetrical types (i.e.
one int variable, four char variables, two float variables and so on…)
If we want the function to return multiple values of same data types, we could return the pointer to array of that data types.
We can also make the function return multiple values by using the arguments of the function.
How? By providing the pointers as arguments.
Usually, when a function needs to return several values, we use one pointer in return instead of several pointers as arguments.
Please see
How to return multiple values from a function in C or C++? for more details.
What is the purpose of a function prototype?
The Function prototype serves the following purposes –
1) It tells the return type of the data that the function will return.
2) It tells the number of arguments passed to the function.
3) It tells the data types of the each of the passed arguments.
4) Also it tells the order in which the arguments are passed to the function.
Therefore essentially, function prototype specifies the input/output interlace to the function i.e.
what to give to the function and what to expect from the function.
Prototype of a function is also called signature of the function.
What if one doesn’t specify the function prototype?
Output of below kind of programs is generally asked at many places.
int main()
{
foo();
getchar();
return 0;
}
void foo()
{
printf("foo called");
}
If one doesn’t specify the function prototype, the behavior is specific to C standard (either C90 or C99) that the compilers implement.
Up to C90 standard, C compilers assumed the return type of the omitted function prototype as int.
And this assumption at compiler side may lead to unspecified program behavior.
Later C99 standard specified that compilers can no longer assume return type as int.
Therefore, C99 became more restrict in type checking of function prototype.
But to make C99 standard backward compatible, in practice, compilers throw the warning saying that the return type is assumed as int.
But they go ahead with compilation.
Thus, it becomes the responsibility of programmers to make sure that the assumed function prototype and the actual function type matches.
To avoid all this implementation specifics of C standards, it is best to have function prototype.
Static functions in C
Prerequisite :
Static variables in C
In C, functions are global by default.
The “
static” keyword before a function name makes it static.
For example, below function
fun() is static.
static int fun(void)
{
printf("I am a static function ");
}
Unlike global functions in C, access to static functions is restricted to the file where they are declared.
Therefore, when we want to restrict access to functions, we make them static.
Another reason for making functions static can be reuse of the same function name in other files.
For example, if we store following program in one file
file1.c
static void fun1(void)
{
puts("fun1 called");
}
And store following program in another file
file2.c
int main(void)
{
fun1();
getchar();
return 0;
}
Now, if we compile the above code with command “
gcc file2.c file1.c”, we get the error
“undefined reference to `fun1’” .
This is because
fun1() is declared
static in
file1.c and cannot be used in
file2.c.
exit(), abort() and assert()
exit()
void exit ( int status );
exit() terminates the process normally.
status: Status value returned to the parent process.
Generally, a status value of 0 or EXIT_SUCCESS indicates success, and any other value or the constant EXIT_FAILURE is used to indicate an error.
exit() performs following operations.
* Flushes unwritten buffered data.
* Closes all open files.
* Removes temporary files.
* Returns an integer exit status to the operating system.
The C standard
atexit() function can be used to customize exit() to perform additional actions at program termination.
Example use of exit.
#include <stdio.h>
#include <stdlib.h>
int main ()
{
FILE * pFile;
pFile = fopen ("myfile.txt", "r");
if (pFile == NULL)
{
printf ("Error opening file");
exit (1);
}
else
{
}
return 0;
}
When exit() is called, any open file descriptors belonging to the process are closed and any children of the process are inherited by process 1, init, and the process parent is sent a SIGCHLD signal.
The mystery behind exit() is that it takes only integer args in the range 0 – 255 .
Out of range exit values can result in unexpected exit codes.
An exit value greater than 255 returns an exit code modulo 256.
For example, exit 9999 gives an exit code of 15 i.e.
(9999 % 256 = 15).
Below is the C implementation to illustrate the above fact:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main(void)
{
pid_t pid = fork();
if ( pid == 0 )
{
exit(9999);
}
int status;
waitpid(pid, &status, 0);
if ( WIFEXITED(status) )
{
int exit_status = WEXITSTATUS(status);
printf("Exit code: %d\n", exit_status);
}
return 0;
}
Output:
Exit code: 15
Note that the above code may not work with online compiler as fork() is disabled.
Explanation: It is effect of 8-bit integer overflow.
After 255 (all 8 bits set) comes 0.
So the output is “exit code modulo 256”.
The output above is actually the modulo of the value 9999 and 256 i.e.
15.
abort()
void abort ( void );
Unlike exit() function, abort() may not close files that are open.
It may also not delete temporary files and may not flush stream buffer.
Also, it does not call functions registered with
atexit().
This function actually terminates the process by raising a SIGABRT signal, and your program can include a handler to intercept this signal (see
this).
So programs like below might not write “Geeks for Geeks” to “tempfile.txt”
#include<stdio.h>
#include<stdlib.h>
int main()
{
FILE *fp = fopen("C:\\myfile.txt", "w");
if(fp == NULL)
{
printf("\n could not open file ");
getchar();
exit(1);
}
fprintf(fp, "%s", "Geeks for Geeks");
abort();
getchar();
return 0;
}
If we want to make sure that data is written to files and/or buffers are flushed then we should either use exit() or include a signal handler for SIGABRT.
assert()
void assert( int expression );
If expression evaluates to 0 (false), then the expression, sourcecode filename, and line number are sent to the standard error, and then abort() function is called.
If the identifier NDEBUG (“no debug”) is defined with #define NDEBUG then the macro assert does nothing.
Common error outputting is in the form:
Assertion failed: expression, file filename, line line-number
#include<assert.h>
void open_record(char *record_name)
{
assert(record_name != NULL);
}
int main(void)
{
open_record(NULL);
}
Related Article :
exit() vs _Exit() in C and C++
Implicit return type int in C
Predict the output of following C program.
#include <stdio.h>
fun(int x)
{
return x*x;
}
int main(void)
{
printf("%d", fun(10));
return 0;
}
Output: 100
The important thing to note is, there is no return type for fun(), the program still compiles and runs fine in most of the C compilers.
In C, if we do not specify a return type, compiler assumes an implicit return type as int.
However, C99 standard doesn’t allow return type to be omitted even if return type is int.
This was allowed in older C standard C89.
In C++, the above program is not valid except few old C++ compilers like Turbo C++.
Every function should specify the return type in C++.
What happens when a function is called before its declaration in C?
In C, if a function is called before its declaration, the
compiler assumes return type of the function as int.
For example, the following program fails in compilation.
#include <stdio.h>
int main(void)
{
printf("%d\n", fun());
return 0;
}
char fun()
{
return 'G';
}
if the function
char fun() in above code is defined before main() then it will compile and run perfectly.
for example, the following program will run properly.
#include <stdio.h>
char fun()
{
return 'G';
}
int main(void)
{
printf("%d\n", fun());
return 0;
}
The following program compiles and run fine because function is defined before main().
#include <stdio.h>
int fun()
{
return 10;
}
int main(void)
{
printf("%d\n", fun());
return 0;
}
What about parameters? compiler assumes nothing about parameters.
Therefore, the compiler will not be able to perform compile-time checking of argument types and arity when the function is applied to some arguments.
This can cause problems.
For example, the following program compiled fine in GCC and produced garbage value as output.
#include <stdio.h>
int main (void)
{
printf("%d", sum(10, 5));
return 0;
}
int sum (int b, int c, int a)
{
return (a+b+c);
}
There is this misconception that the compiler assumes input parameters also int.
Had compiler assumed input parameters int, the above program would have failed in compilation.
It is always recommended to declare a function before its use so that we don’t see any surprises when the program is run (See
this for more details).
Source:
http://en.wikipedia.org/wiki/Function_prototype#Uses
_Noreturn function specifier in C
After the removal of “noreturn” keyword, C11 standard (known as final draft) of C programming language introduce a new “_Noreturn” function specifier that specify that the function does not return to the function that it was called from.
If the programmer try to return any value from that function which is declared as _Noreturn type, then the compiler automatically generates a compile time error.
#include <stdio.h>
#include <stdlib.h>
_Noreturn void view()
{
return 10;
}
int main(void)
{
printf("Ready to begin...\n");
view();
printf("NOT over till now\n");
return 0;
}
Output:
Ready to begin...
After that abnormal termination of program.
compiler error:[Warning] function declared 'noreturn' has a 'return' statement
#include <stdio.h>
#include <stdlib.h>
_Noreturn void show()
{
printf("BYE BYE");
}
int main(void)
{
printf("Ready to begin...\n");
show();
printf("NOT over till now\n");
return 0;
}
Output:
Ready to begin...
BYE BYE
Reference:
http://en.cppreference.com/w/c/language/_Noreturn
exit() vs _Exit() in C and C++
In C,
exit() terminates the calling process without executing the rest code which is after the exit() function.
Example:-
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
printf("START");
exit(0);
printf("End of program");
}
Output:
START
Now the question is that if we have exit() function then why C11 standard introduced _Exit()? Actually exit() function performs some cleaning before termination of the program like connection termination, buffer flushes etc.
The _Exit() function in C/C++ gives normal termination of a program without performing any cleanup tasks.
For example it does not execute functions registered with atexit.
Syntax:
// Here the exit_code represent the exit status
// of the program which can be 0 or non-zero.
// The _Exit() function returns nothing.
void _Exit(int exit_code);
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int exit_code = 10;
printf("Termination using _Exit");
_Exit(exit_code);
}
Output:
Showing difference through programs:
#include<bits/stdc++.h>
using namespace std;
void fun(void)
{
cout << "Exiting";
}
int main()
{
atexit(fun);
exit(10);
}
Output
Exiting
If we replace exit with _Exit(), then nothing is printed.
#include<bits/stdc++.h>
using namespace std;
void fun(void)
{
cout << "Exiting";
}
int main()
{
atexit(fun);
_Exit(10);
}
Output
Predefined Identifier __func__ in C
Before we start discussing about
__func__, let us write some code snippet and anticipate the output:
#include “studio.h”
int main()
{
printf(“%s”,__func__);
return 0;
}
Will it compile error due to not defining variable
__func__ ? Well, as you would have guessed so far, it won’t give any compile error and it’d print
main!
C language standard (i.e.
C99 and C11) defines a predefined identifier as follows in clause 6.4.2.2:
“
The identifier __func__ shall be implicitly declared by the translator as if, immediately following the opening brace of each function definition, the declaration
static const char __func__[] = “function-name”;
appeared, where function-name is the name of the lexically-enclosing function.”
It means that C compiler implicitly adds
__func__ in every function so that it can be used in that function to get the function name.
To understand it better, let us write this code:
#include “stdio.h”
void foo(void)
{
printf(“%s”,__func__);
}
void bar(void)
{
printf(“%s”,__func__);
}
int main()
{
foo();
bar();
return 0;
}
And it’ll give output as
foobar.
A use case of this predefined identifier could be logging the output of a big program where a programmer can use
__func__ to get the current function instead of mentioning the complete function name explicitly.
Now what happens if we define one more variable of name
__func__
#include “stdio.h”
int __func__ = 10;
int main()
{
printf(“%d”,__func__);
return 0;
}
Since C standard says compiler implicitly defines
__func__ for each function as the function-name, we should not defined
__func__ at the first place.
You might get error but C standard says “undefined behaviour” if someone explicitly defines
__func__ .
Just to finish the discussion on Predefined Identifier
__func__, let us mention Predefined Macros as well (such as __FILE__ and __LINE__ etc.) Basically, C standard clause 6.10.8 mentions several predefined macros out of which
__FILE__ and
__LINE__ are of relevance here.
It’s worthwhile to see the output of the following code snippet:
#include "stdio.h"
int main()
{
printf("In file:%s, function:%s() and line:%d",__FILE__,__func__,__LINE__);
return 0;
}
Instead of explaining the output, we will leave this to you to guess and understand the role of
__FILE__ and
__LINE__!
Please do Like/Tweet/G+1 if you find the above useful.
Also, please do leave us comment for further clarification or info.
We would love to help and learn 🙂
Callbacks in C
A callback is any executable code that is passed as an argument to other code, which is expected to call back (execute) the argument at a given time [Source :
Wiki].
In simple language, If a reference of a function is passed to another function as an argument to call it, then it will be called as a Callback function.
In C, a callback function is a function that is called through a
function pointer.
Below is a simple example in C to illustrate the above definition to make it more clear:
#include<stdio.h>
void A()
{
printf("I am function A\n");
}
void B(void (*ptr)())
{
(*ptr) ();
}
int main()
{
void (*ptr)() = &A;
B(ptr);
return 0;
}
I am function A
In C++ STL,
functors are also used for this purpose.
Nested functions in C
Some programmer thinks that defining a function inside an another function is known as “nested function”.
But the reality is that it is not a nested function, it is treated as lexical scoping.
Lexical scoping is not valid in C because the compiler cant reach/find the correct memory location of the inner function.
Nested function
is not supported by C because we cannot define a function within another function in C.
We can declare a function inside a function, but it’s not a nested function.
Because nested functions definitions can not
access local variables of the surrounding blocks, they can access only global variables of the containing module.
This is done so that lookup of global variables doesn’t have to go through the directory.
As in C, there are two nested scopes: local and global (and beyond this, built-ins).
Therefore, nested functions have only a limited use.
If we try to approach nested function in C, then we will get compile time error.
#include <stdio.h>
int main(void)
{
printf("Main");
int fun()
{
printf("fun");
int view()
{
printf("view");
}
return 1;
}
view();
}
Output:
Compile time error: undefined reference to `view'
An extension of the GNU C Compiler allows the declarations of nested functions.
The declarations of nested functions under GCC’s extension need to be prefix/start with the
auto keyword.
#include <stdio.h>
int main(void)
{
auto int view();
view();
printf("Main\n");
int view()
{
printf("View\n");
return 1;
}
printf("GEEKS");
return 0;
}
Output:
view
Main
GEEKS
Parameter Passing Techniques in C/C++
There are different ways in which parameter data can be passed into and out of methods and functions.
Let us assume that a function
B() is called from another function
A().
In this case
A is called the
“caller function” and
B is called the
“called function or callee function”.
Also, the arguments which
A sends to
B are called
actual arguments and the parameters of
B are called
formal arguments.
Terminology
- Formal Parameter : A variable and its type as they appear in the prototype of the function or method.
- Actual Parameter : The variable or expression corresponding to a formal parameter that appears in the function or method call in the calling environment.
- Modes:
- IN: Passes info from caller to calle.
- OUT: Callee writes values in caller.
- IN/OUT: Caller tells callee value of variable, which may be updated by callee.
Important methods of Parameter Passing
- Pass By Value : This method uses in-mode semantics.
Changes made to formal parameter do not get transmitted back to the caller.
Any modifications to the formal parameter variable inside the called function or method affect only the separate storage location and will not be reflected in the actual parameter in the calling environment.
This method is also called as call by value.
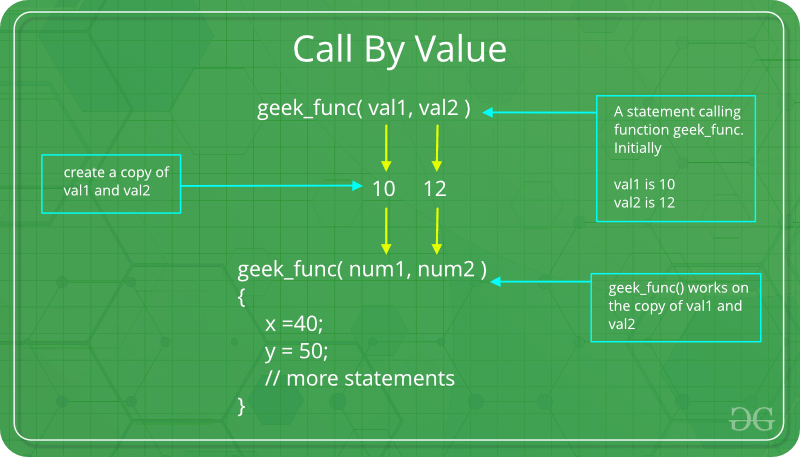
#include <stdio.h>
void func(int a, int b)
{
a += b;
printf("In func, a = %d b = %d\n", a, b);
}
int main(void)
{
int x = 5, y = 7;
func(x, y);
printf("In main, x = %d y = %d\n", x, y);
return 0;
}
Output:
In func, a = 12 b = 7
In main, x = 5 y = 7
Languages like C, C++, Java support this type of parameter passing.
Java in fact is strictly call by value.
Shortcomings:
- Inefficiency in storage allocation
- For objects and arrays, the copy semantics are costly
- Pass by reference(aliasing) : This technique uses in/out-mode semantics.
Changes made to formal parameter do get transmitted back to the caller through parameter passing.
Any changes to the formal parameter are reflected in the actual parameter in the calling environment as formal parameter receives a reference (or pointer) to the actual data.
This method is also called as <em>call by reference.
This method is efficient in both time and space.
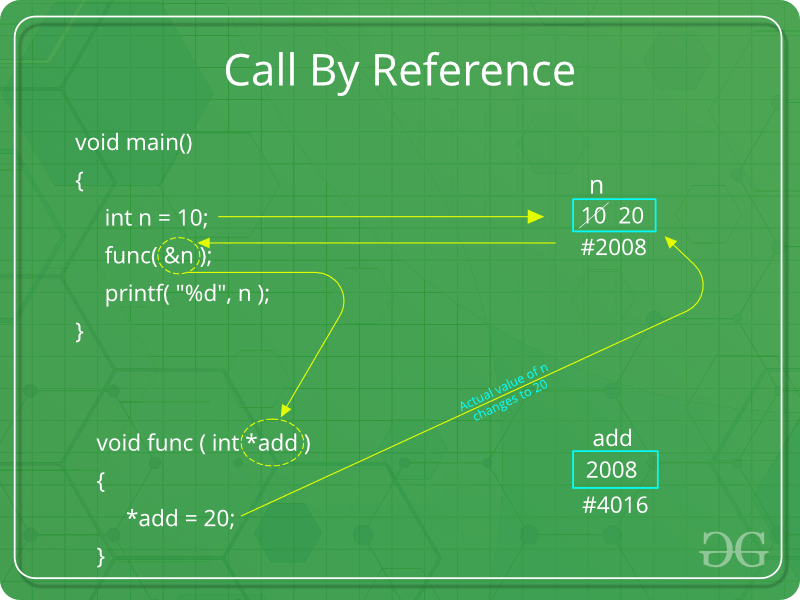
#include <stdio.h>
void swapnum(int* i, int* j)
{
int temp = *i;
*i = *j;
*j = temp;
}
int main(void)
{
int a = 10, b = 20;
swapnum(&a, &b);
printf("a is %d and b is %d\n", a, b);
return 0;
}
Output:
a is 20 and b is 10
C and C++ both support call by value as well as call by reference whereas Java does’nt support call by reference.
Shortcomings:
- Many potential scenarios can occur
- Programs are difficult to understand sometimes
Other methods of Parameter Passing
These techniques are older and were used in earlier programming languages like Pascal, Algol and Fortran.
These techniques are not applicable in high level languages.
- Pass by Result : This method uses out-mode semantics.
Just before control is transfered back to the caller, the value of the formal parameter is transmitted back to the actual parameter.T his method is sometimes called call by result.
In general, pass by result technique is implemented by copy.
- Pass by Value-Result : This method uses in/out-mode semantics.
It is a combination of Pass-by-Value and Pass-by-result.
Just before the control is transferred back to the caller, the value of the formal parameter is transmitted back to the actual parameter.
This method is sometimes called as call by value-result
- Pass by name : This technique is used in programming language such as Algol.
In this technique, symbolic “name” of a variable is passed, which allows it both to be accessed and update.
Example:
To double the value of C[j], you can pass its name (not its value) into the following procedure.
procedure double(x);
real x;
begin
x:=x*2
end;
In general, the effect of pass-by-name is to textually substitute the argument in a procedure call for the corresponding parameter in the body of the procedure.
Implications of Pass-by-Name mechanism:
- The argument expression is re-evaluated each time the formal parameter is passed.
- The procedure can change the values of variables used in the argument expression and hence change the expression’s value.
Power Function in C/C++
Given two numbers base and exponent, pow() function finds x raised to the power of y i.e.
x
y.
Basically in C exponent value is calculated using the pow() function.
Example:
Input: 2.0, 5.0
Output: 32
Explanation:
pow(2.0, 5.0) executes 2.0 raised to
the power 5.0, which equals 32
Input: 5.0, 2.0
Output: 25
Explanation:
pow(5.0, 2.0) executes 5.0 raised to
the power 2.0, which equals 25
Syntax:
double pow(double x, double y);
Parameters: The method takes two arguments:
- x : floating point base value
- y : floating point power value
Program:
C
#include <math.h>
#include <stdio.h>
int main()
{
double x = 6.1, y = 4.8;
double result = pow(x, y);
printf("%.2lf", result);
return 0;
}
C++
#include <bits/stdc++.h>
using namespace std;
int main()
{
double x = 6.1, y = 4.8;
double result = pow(x, y);
cout << fixed << setprecision(2) << result << endl;
return 0;
}
Output:
5882.79
Working of pow() function with integers
The pow() function takes ‘double’ as the arguments and returns a ‘double’ value.
This function does not always work for integers.
One such example is pow(5, 2).
When assigned to an integer, it outputs 24 on some compilers and works fine for some other compilers.
But pow(5, 2) without any assignment to an integer outputs 25.
- This is because 52 (i.e.
25) might be stored as 24.9999999 or 25.0000000001 because the return type is double.
When assigned to int, 25.0000000001 becomes 25 but 24.9999999 will give output 24.
- To overcome this and output the accurate answer in integer format, we can add 0.5 to the result and typecast it to int e.g (int)(pow(5, 2)+0.5) will give the correct answer(25, in above example), irrespective of the compiler.
C
#include <math.h>
#include <stdio.h>
int main()
{
int a;
a = (int)(pow(5, 2) + 0.5);
printf("%d", a);
return 0;
}
C++
#include <bits/stdc++.h>
using namespace std;
int main()
{
int a;
a = (int)(pow(5, 2) + 0.5);
cout << a;
return 0;
}
Output:
25
tolower() function in C
The
tolower() function is defined in the
ctype.h header file.
If the character passed is a uppercase alphabet then the tolower() function converts a uppercase alphabet to an lowercase alphabet.
Syntax:
int tolower(int ch);
Parameter: This method takes a mandatory parameter
ch which is the character to be converted to lowercase.
Return Value: This function returns the
lowercase character corresponding to the ch.
Below programs illustrate the tolower() function in C:
Example 1:-
#include <ctype.h>
#include <stdio.h>
int main()
{
char ch = 'G';
printf("%c in lowercase is represented as = %c", ch, tolower(ch));
return 0;
}
Output:
G in lowercase is represented as = g
Example 2:-
#include <ctype.h>
#include <stdio.h>
int main()
{
int j = 0;
char str[] = "GEEKSFORGEEKS\n";
char ch = 'G';
char ch;
while (str[j]) {
ch = str[j];
putchar(tolower(ch));
j++;
}
return 0;
}
Output:
geeksforgeeks
time() function in C
The time() function is defined in time.h (ctime in C++) header file.
This function returns the time since 00:00:00 UTC, January 1, 1970 (Unix timestamp) in seconds.
If second is not a null pointer, the returned value is also stored in the object pointed to by second.
Syntax:
time_t time( time_t *second )
Parameter: This function accepts single parameter
second.
This parameter is used to set the time_t object which store the time.
Return Value: This function returns current calender time as a object of type time_t.
Program 1:
#include <stdio.h>
#include <time.h>
int main ()
{
time_t seconds;
seconds = time(NULL);
printf("Seconds since January 1, 1970 = %ld\n", seconds);
return(0);
}
Output:
Seconds since January 1, 1970 = 1538123990
Example 2:
#include <stdio.h>
#include <time.h>
int main()
{
time_t seconds;
time(&seconds);
printf("Seconds since January 1, 1970 = %ld\n", seconds);
return 0;
}
Output:
Seconds since January 1, 1970 = 1538123990
Pointers in C and C++ | Set 1 (Introduction, Arithmetic and Array)
Pointers store address of variables or a memory location.
// General syntax
datatype *var_name;
// An example pointer "ptr" that holds
// address of an integer variable or holds
// address of a memory whose value(s) can
// be accessed as integer values through "ptr"
int *ptr;
Using a Pointer:

To use pointers in C, we must understand below two operators.
- To access address of a variable to a pointer, we use the unary operator & (ampersand) that returns the address of that variable.
For example &x gives us address of variable x.
#include <stdio.h>
int main()
{
int x;
printf("%p", &x);
return 0;
}
- One more operator is unary * (Asterisk) which is used for two things :
Pointer Expressions and Pointer Arithmetic
A limited set of arithmetic operations can be performed on pointers.
A pointer may be:
- incremented ( ++ )
- decremented ( — )
- an integer may be added to a pointer ( + or += )
- an integer may be subtracted from a pointer ( – or -= )
Pointer arithmetic is meaningless unless performed on an array.
Note : Pointers contain addresses.
Adding two addresses makes no sense, because there is no idea what it would point to.
Subtracting two addresses lets you compute the offset between these two addresses.
#include <bits/stdc++.h>
int main()
{
int v[3] = {10, 100, 200};
int *ptr;
ptr = v;
for (int i = 0; i < 3; i++)
{
printf("Value of *ptr = %d\n", *ptr);
printf("Value of ptr = %p\n\n", ptr);
ptr++;
}
}
Output:Value of *ptr = 10
Value of ptr = 0x7ffcae30c710
Value of *ptr = 100
Value of ptr = 0x7ffcae30c714
Value of *ptr = 200
Value of ptr = 0x7ffcae30c718
 Array Name as Pointers
Array Name as Pointers
An array name acts like a pointer constant.
The value of this pointer constant is the address of the first element.
For example, if we have an array named val then
val and
&val[0] can be used interchangeably.
#include <bits/stdc++.h>
using namespace std;
void geeks()
{
int val[3] = { 5, 10, 15};
int *ptr;
ptr = val ;
cout << "Elements of the array are: ";
cout << ptr[0] << " " << ptr[1] << " " << ptr[2];
return;
}
int main()
{
geeks();
return 0;
}
Output:
Elements of the array are: 5 10 15

Now if this ptr is sent to a function as an argument then the array val can be accessed in a similar fashion.
Pointers and Multidimensional Arrays
Consider pointer notation for the two-dimensional numeric arrays.
consider the following declaration
int nums[2][3] = { {16, 18, 20}, {25, 26, 27} };
In general, nums[i][j] is equivalent to *(*(nums+i)+j)
| Pointer Notation |
Array Notation |
Value |
| *(*nums) |
nums[0][0] |
16 |
| *(*nums + 1) |
nums[0][1] |
18 |
| *(*nums + 2) |
nums[0][2] |
20 |
| *(*(nums + 1)) |
nums[1][0] |
25 |
| *(*(nums + 1) + 1) |
nums[1][1] |
26 |
| *(*(nums + 1) + 2) |
nums[1][2] |
27 |
Related Articles:
Applications of pointers in C/C++.
Quizzes –
Quiz on Pointer Basics ,
Quiz on Advanced Pointer
Reference:
https://www.ntu.edu.sg/home/ehchua/programming/cpp/cp4_PointerReference.html
Double Pointer (Pointer to Pointer) in C
Prerequisite :
Pointers in C and C++
We already know that a pointer points to a location in memory and thus used to store the address of variables.
So, when we define a pointer to pointer.
The first pointer is used to store the address of the variable.
And the second pointer is used to store the address of the first pointer.
That is why they are also known as double pointers.
How to declare a pointer to pointer in C?
Declaring Pointer to Pointer is similar to declaring pointer in C.
The difference is we have to place an additional ‘*’ before the name of pointer.
Syntax:
int **ptr; // declaring double pointers
Below diagram explains the concept of Double Pointers:

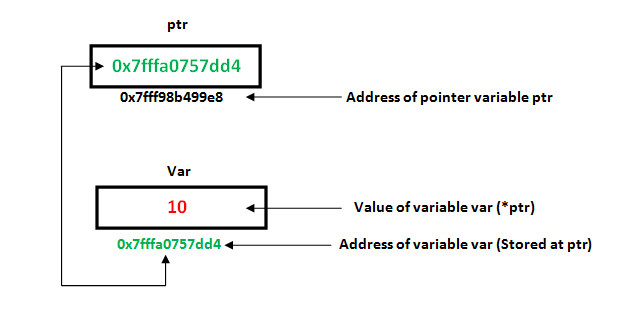
The above diagram shows the memory representation of a pointer to pointer.
The first pointer ptr1 stores the address of the variable and the second pointer ptr2 stores the address of the first pointer.
Let us understand this more clearly with the help of the below program:
#include <stdio.h>
int main()
{
int var = 789;
int *ptr2;
int **ptr1;
ptr2 = &var;
ptr1 = &ptr2;
printf("Value of var = %d\n", var );
printf("Value of var using single pointer = %d\n", *ptr2 );
printf("Value of var using double pointer = %d\n", **ptr1);
return 0;
}
Output:
Value of var = 789
Value of var using single pointer = 789
Value of var using double pointer = 789
Related Post :
Function Pointer in C
Why C treats array parameters as pointers?
In C, array parameters are treated as pointers.
The following two definitions of foo() look different, but to the compiler they mean exactly the same thing.
It’s preferable to use whichever syntax is more accurate for readability.
If the pointer coming in really is the base address of a whole array, then we should use [ ].
void foo(int arr_param[])
{
arr_param = NULL;
}
void foo(int *arr_param)
{
arr_param = NULL;
}
Array parameters treated as pointers because of efficiency.
It is inefficient to copy the array data in terms of both memory and time; and most of the times, when we pass an array our intention is to just tell the array we interested in, not to create a copy of the array.
Asked by Shobhit
Output of the program | Dereference, Reference, Dereference, Reference….
Predict the output of below program
#include<stdio.h>
int main()
{
char *ptr = "geeksforgeeks";
printf("%c\n", *&*&*ptr);
getchar();
return 0;
}
Output: g
Explanation: The operator * is used for dereferencing and the operator & is used to get the address.
These operators cancel effect of each other when used one after another.
We can apply them alternatively any no.
of times.
For example *ptr gives us g, &*ptr gives address of g, *&*ptr again g, &*&*ptr address of g, and finally *&*&*ptr gives ‘g’
Now try below
#include<stdio.h>
int main()
{
char *ptr = "geeksforgeeks";
printf("%s\n", *&*&ptr);
getchar();
return 0;
}
Dangling, Void , Null and Wild Pointers
Dangling pointer
A pointer pointing to a memory location that has been deleted (or freed) is called dangling pointer.
There are three different ways where Pointer acts as dangling pointer
- De-allocation of memory
#include <stdlib.h>
#include <stdio.h>
int main()
{
int *ptr = (int *)malloc(sizeof(int));
free(ptr);
ptr = NULL;
}
- Function Call
#include<stdio.h>
int *fun()
{
int x = 5;
return &x;
}
int main()
{
int *p = fun();
fflush(stdin);
printf("%d", *p);
return 0;
}
Output:
A garbage Address
The above problem doesn’t appear (or p doesn’t become dangling) if x is a static variable.
#include<stdio.h>
int *fun()
{
static int x = 5;
return &x;
}
int main()
{
int *p = fun();
fflush(stdin);
printf("%d",*p);
}
Output:
5
- Variable goes out of scope
void main()
{
int *ptr;
.....
.....
{
int ch;
ptr = &ch;
}
.....
// Here ptr is dangling pointer
}
Void pointer
Void pointer is a specific pointer type – void * – a pointer that points to some data location in storage, which doesn’t have any specific type.
Void refers to the type.
Basically the type of data that it points to is can be any.
If we assign address of char data type to void pointer it will become char Pointer, if int data type then int pointer and so on.
Any pointer type is convertible to a void pointer hence it can point to any value.
Important Points
- void pointers cannot be dereferenced.
It can however be done using typecasting the void pointer
- Pointer arithmetic is not possible on pointers of void due to lack of concrete value and thus size.
Example:
#include<stdlib.h>
int main()
{
int x = 4;
float y = 5.5;
void *ptr;
ptr = &x;
printf("Integer variable is = %d", *( (int*) ptr) );
ptr = &y;
printf("\nFloat variable is= %f", *( (float*) ptr) );
return 0;
}
Output:
Integer variable is = 4
Float variable is= 5.500000
Refer
void pointer article for details.
NULL Pointer
NULL Pointer is a pointer which is pointing to nothing.
In case, if we don’t have address to be assigned to a pointer, then we can simply use NULL.
#include <stdio.h>
int main()
{
int *ptr = NULL;
printf("The value of ptr is %p", ptr);
return 0;
}
Output :
The value of ptr is (nil)
Important Points
- NULL vs Uninitialized pointer – An uninitialized pointer stores an undefined value.
A null pointer stores a defined value, but one that is defined by the environment to not be a valid address for any member or object.
- NULL vs Void Pointer – Null pointer is a value, while void pointer is a type
Wild pointer
A pointer which has not been initialized to anything (not even NULL) is known as wild pointer.
The pointer may be initialized to a non-NULL garbage value that may not be a valid address.
int main()
{
int *p;
int x = 10;
p = &x;
return 0;
}
An Uncommon representation of array elements
Consider the below program.
int main( )
{
int arr[2] = {0,1};
printf("First Element = %d\n",arr[0]);
getchar();
return 0;
}
Pretty Simple program..
huh… Output will be 0.
Now if you replace
arr[0] with
0[arr], the output would be same.
Because compiler converts the array operation in pointers before accessing the array elements.
e.g.
arr[0] would be
*(arr + 0) and therefore 0[arr] would be
*(0 + arr) and you know that both
*(arr + 0) and
*(0 + arr) are same.
How to declare a pointer to a function?
Well, we assume that you know what does it mean by pointer in C.
So how do we create a pointer to an integer in C?
Huh..it is pretty simple..
int * ptrInteger; /*We have put a * operator between int
and ptrInteger to create a pointer.*/
Here ptrInteger is a pointer to integer.
If you understand this, then logically we should not have any problem in declaring a pointer to a function 🙂
So let us first see ..how do we declare a function? For example,
int foo(int);
Here foo is a function that returns int and takes one argument of int type.
So as a logical guy will think, by putting a * operator between int and foo(int) should create a pointer to a function i.e.
int * foo(int);
But Oops..C operator precedence also plays role here ..so in this case, operator () will take priority over operator *.
And the above declaration will mean – a function foo with one argument of int type and return value of int * i.e.
integer pointer.
So it did something that we didn’t want to do.
🙁
So as a next logical step, we have to bind operator * with foo somehow.
And for this, we would change the default precedence of C operators using () operator.
int (*foo)(int);
That’s it.
Here * operator is with foo which is a function name.
And it did the same that we wanted to do.
So that wasn’t as difficult as we thought earlier!
Pointer vs Array in C
Most of the time, pointer and array accesses can be treated as acting the same, the major exceptions being:
1) the sizeof operator
o sizeof(array) returns the amount of memory used by all elements in array
o sizeof(pointer) only returns the amount of memory used by the pointer variable itself
2) the & operator
o &array is an alias for &array[0] and returns the address of the first element in array
o &pointer returns the address of pointer
3) a string literal initialization of a character array
o char array[] = “abc” sets the first four elements in array to ‘a’, ‘b’, ‘c’, and ‘\0’
o char *pointer = “abc” sets pointer to the address of the “abc” string (which may be stored in read-only memory and thus unchangeable)
4) Pointer variable can be assigned a value whereas array variable cannot be.
int a[10];
int *p;
p=a; /*legal*/
a=p; /*illegal*/
5) Arithmetic on pointer variable is allowed.
p++; /*Legal*/
a++; /*illegal*/
Please refer Difference between pointer and array in C? for more details.
void pointer in C / C++
A void pointer is a pointer that has no associated data type with it.
A void pointer can hold address of any type and can be typcasted to any type.
int a = 10;
char b = 'x';
void *p = &a;
p = &b;
Advantages of void pointers:
1) malloc() and calloc() return void * type and this allows these functions to be used to allocate memory of any data type (just because of void *)
edit
link
int main(void)
{
// Note that malloc() returns void * which can be
// typecasted to any type like int *, char *, ..
int *x = malloc(sizeof(int) * n);
}
Note that the above program compiles in C, but doesn’t compile in C++.
In C++, we must explicitly typecast return value of malloc to (int *).
2) void pointers in C are used to implement generic functions in C.
For example
compare function which is used in qsort().
Some Interesting Facts:
1) void pointers cannot be dereferenced.
For example the following program doesn’t compile.
#include<stdio.h>
int main()
{
int a = 10;
void *ptr = &a;
printf("%d", *ptr);
return 0;
}
Output:
Compiler Error: 'void*' is not a pointer-to-object type
The following program compiles and runs fine.
#include<stdio.h>
int main()
{
int a = 10;
void *ptr = &a;
printf("%d", *(int *)ptr);
return 0;
}
Output:
10
2) The
C standard doesn’t allow pointer arithmetic with void pointers.
However, in GNU C it is allowed by considering the size of void is 1.
For example the following program compiles and runs fine in gcc.
#include<stdio.h>
int main()
{
int a[2] = {1, 2};
void *ptr = &a;
ptr = ptr + sizeof(int);
printf("%d", *(int *)ptr);
return 0;
}
Output:
2
Note that the above program may not work in other compilers.
NULL pointer in C
At the very high level, we can think of NULL as a null pointer which is used in C for various purposes.
Some of the most common use cases for NULL are
a) To initialize a pointer variable when that pointer variable isn’t assigned any valid memory address yet.
b) To check for a null pointer before accessing any pointer variable.
By doing so, we can perform error handling in pointer related code e.g.
dereference pointer variable only if it’s not NULL.
c) To pass a null pointer to a function argument when we don’t want to pass any valid memory address.
The example of a is
int * pInt = NULL;
The example of b is
if(pInt != NULL)
{ }
else
{ }
The example of c is
int fun(int *ptr)
{
return 10;
}
fun(NULL);
It should be noted that NULL pointer is different from an uninitialized and dangling pointer.
In a specific program context, all uninitialized or dangling or NULL pointers are invalid but NULL is a specific invalid pointer which is mentioned in C standard and has specific purposes.
What we mean is that uninitialized and dangling pointers are invalid but they can point to some memory address that may be accessible through the memory access is unintended.
#include <stdio.h>
int main()
{
int *i, *j;
int *ii = NULL, *jj = NULL;
if(i == j)
{
printf("This might get printed if both i and j are same by chance.");
}
if(ii == jj)
{
printf("This is always printed coz ii and jj are same.");
}
return 0;
}
By specifically mentioning NULL pointer, C standard gives mechanism using which a C programmer can use and check whether a given pointer is legitimate or not. But what exactly is NULL and how it’s defined? Strictly speaking, NULL expands to an implementation-defined null pointer constant which is defined in many header files such as “stdio.h”, “stddef.h”, “stdlib.h” etc.
Let us see what C standards say about null pointer.
From C11 standard clause 6.3.2.3,
“An integer constant expression with the value 0, or such an expression cast to type void *, is called a null pointer constant.
If a null pointer constant is converted to a pointer type, the resulting pointer, called a null pointer, is guaranteed to compare unequal to a pointer to any object or function.”
Before we proceed further on this NULL discussion :), let’s mention few lines about C standard just in case you wants to refer it for further study.
Please note that ISO/IEC 9899:2011 is the C language’s latest standard which was published in Dec 2011.
This is also called the C11 standard.
For completeness, let us mention that previous standards for C were C99, C90 (also known as ISO C) and C89 (also known as ANSI C).
Though the actual C11 standard can be purchased from ISO, there’s a draft document which is available in public domain for free.
Coming to our discussion, NULL macro is defined as ((void *)0) in header files of most of the C compiler implementations.
But C standard is saying that 0 is also a null pointer constant.
It means that the following is also perfectly legal as per standard.
int * ptr = 0;
Please note that 0 in the above C statement is used in pointer-context and it’s different from 0 as integer.
This is one of the reasons why the usage of NULL is preferred because it makes it explicit in code that programmer is using null pointer, not integer 0.
Another important concept about NULL is that “NULL expands to an implementation-defined null pointer constant”.
This statement is also from C11 clause 7.19.
It means that internal representation of the null pointer could be non-zero bit pattern to convey NULL pointer.
That’s why NULL always needn’t be internally represented as all zeros bit pattern.
A compiler implementation can choose to represent “null pointer constant” as a bit pattern for all 1s or anything else.
But again, as a C programmer, we needn’t worry much on the internal value of the null pointer unless we are involved in Compiler coding or even below the level of coding.
Having said so, typically NULL is represented as all bits set to 0 only.
To know this on a specific platform, one can use the following
#include<stdio.h>
int main()
{
printf("%d",NULL);
return 0;
}
Most likely, it’s printing 0 which is the typical internal null pointer value but again it can vary depending on the C compiler/platform.
You can try few other things in above program such as printf(“‘%c“,NULL) or printf(“%s”,NULL) and even printf(“%f”,NULL).
The outputs of these are going to be different depending on the platform used but it’d be interesting especially usage of %f with NULL!
Can we use sizeof() operator on NULL in C? Well, usage of sizeof(NULL) is allowed but the exact size would depend on platform.
#include<stdio.h>
int main()
{
printf("%lu",sizeof(NULL));
return 0;
}
Since NULL is defined as ((void*)0), we can think of NULL as a special pointer and its size would be equal to any pointer.
If the pointer size of a platform is 4 bytes, the output of the above program would be 4.
But if pointer size on a platform is 8 bytes, the output of the above program would be 8.
What about dereferencing of NULL? What’s going to happen if we use the following C code
#include<stdio.h>
int main()
{
int * ptr = NULL;
printf("%d",*ptr);
return 0;
}
On some machines, the above would compile successfully but crashes when the program is run through it needn’t show the same behaviour across all the machines.
Again it depends on a lot of factors.
But the idea of mentioning the above snippet is that we should always check for NULL before accessing it.
Since NULL is typically defined as ((void*)0), let us discuss a little bit about void type as well.
As per C11 standard clause 6.2.5, “The void type comprises an empty set of values; it is an incomplete object type that cannot be completed”. Even C11 clause 6.5.3.4 mentions that “The sizeof operator shall not be applied to an expression that has function type or an incomplete type, to the parenthesized name of such a type, or to an expression that designates a bit-field member.” Basically, it means that void is an incomplete type whose size doesn’t make any sense in C programs but implementations (such as gcc) can choose sizeof(void) as 1 so that the flat memory pointed by void pointer can be viewed as untyped memory i.e.
a sequence of bytes.
But the output of the following needn’t to same on all platforms.
#include<stdio.h>
int main()
{
printf("%lu",sizeof(void));
return 0;
}
On gcc, the above would output 1.
What about sizeof(void *)? Here C11 has mentioned guidelines.
From clause 6.2.5, “A pointer to void shall have the same representation and alignment requirements as a pointer to a character type”.
That’s why the output of the following would be same as any pointer size on a machine.
#include<stdio.h>
int main()
{
printf("%lu",sizeof(void *));
return 0;
}
Inspite of mentioning machine dependent stuff as above, we as C programmers should always strive to make our code as portable as possible.
So we can conclude on NULL as follows:
1.
Always initialize pointer variables as NULL.
2.
Always perform a NULL check before accessing any pointer.
Please do Like/Tweet/G+1 if you find the above useful.
Also, please do leave us to comment for further clarification or info.
We would love to help and learn 🙂
Function Pointer in C
In C, like
normal data pointers (int *, char *, etc), we can have pointers to functions.
Following is a simple example that shows declaration and function call using function pointer.
#include <stdio.h>
void fun(int a)
{
printf("Value of a is %d\n", a);
}
int main()
{
void (*fun_ptr)(int) = &fun;
(*fun_ptr)(10);
return 0;
}
Output:
Value of a is 10
Why do we need an extra bracket around function pointers like fun_ptr in above example?
If we remove bracket, then the expression “void (*fun_ptr)(int)” becomes “void *fun_ptr(int)” which is declaration of a function that returns void pointer.
See following post for details.
How to declare a pointer to a function?
Following are some interesting facts about function pointers.
1) Unlike normal pointers, a function pointer points to code, not data.
Typically a function pointer stores the start of executable code.
2) Unlike normal pointers, we do not allocate de-allocate memory using function pointers.
3) A function’s name can also be used to get functions’ address.
For example, in the below program, we have removed address operator ‘&’ in assignment.
We have also changed function call by removing *, the program still works.
#include <stdio.h>
void fun(int a)
{
printf("Value of a is %d\n", a);
}
int main()
{
void (*fun_ptr)(int) = fun;
fun_ptr(10);
return 0;
}
Output:
Value of a is 10
4) Like normal pointers, we can have an array of function pointers.
Below example in point 5 shows syntax for array of pointers.
5) Function pointer can be used in place of switch case.
For example, in below program, user is asked for a choice between 0 and 2 to do different tasks.
#include <stdio.h>
void add(int a, int b)
{
printf("Addition is %d\n", a+b);
}
void subtract(int a, int b)
{
printf("Subtraction is %d\n", a-b);
}
void multiply(int a, int b)
{
printf("Multiplication is %d\n", a*b);
}
int main()
{
void (*fun_ptr_arr[])(int, int) = {add, subtract, multiply};
unsigned int ch, a = 15, b = 10;
printf("Enter Choice: 0 for add, 1 for subtract and 2 "
"for multiply\n");
scanf("%d", &ch);
if (ch > 2) return 0;
(*fun_ptr_arr[ch])(a, b);
return 0;
}
Enter Choice: 0 for add, 1 for subtract and 2 for multiply
2
Multiplication is 150
6) Like normal data pointers, a function pointer can be passed as an argument and can also be returned from a function.
For example, consider the following C program where wrapper() receives a void fun() as parameter and calls the passed function.
#include <stdio.h>
void fun1() { printf("Fun1\n"); }
void fun2() { printf("Fun2\n"); }
void wrapper(void (*fun)())
{
fun();
}
int main()
{
wrapper(fun1);
wrapper(fun2);
return 0;
}
This point in particular is very useful in C.
In C, we can use function pointers to avoid code redundancy.
For example a simple
qsort() function can be used to sort arrays in ascending order or descending or by any other order in case of array of structures.
Not only this, with function pointers and void pointers, it is possible to use qsort for any data type.
#include <stdio.h>
#include <stdlib.h>
int compare (const void * a, const void * b)
{
return ( *(int*)a - *(int*)b );
}
int main ()
{
int arr[] = {10, 5, 15, 12, 90, 80};
int n = sizeof(arr)/sizeof(arr[0]), i;
qsort (arr, n, sizeof(int), compare);
for (i=0; i<n; i++)
printf ("%d ", arr[i]);
return 0;
}
Output:
5 10 12 15 80 90
Similar to qsort(), we can write our own functions that can be used for any data type and can do different tasks without code redundancy.
Below is an example search function that can be used for any data type.
In fact we can use this search function to find close elements (below a threshold) by writing a customized compare function.
#include <stdio.h>
#include <stdbool.h>
bool compare (const void * a, const void * b)
{
return ( *(int*)a == *(int*)b );
}
int search(void *arr, int arr_size, int ele_size, void *x,
bool compare (const void * , const void *))
{
char *ptr = (char *)arr;
int i;
for (i=0; i<arr_size; i++)
if (compare(ptr + i*ele_size, x))
return i;
return -1;
}
int main()
{
int arr[] = {2, 5, 7, 90, 70};
int n = sizeof(arr)/sizeof(arr[0]);
int x = 7;
printf ("Returned index is %d ", search(arr, n,
sizeof(int), &x, compare));
return 0;
}
Output:
Returned index is 2
The above search function can be used for any data type by writing a separate customized compare().
7) Many object oriented features in C++ are implemented using function pointers in C.
For example
virtual functions.
Class methods are another example implemented using function pointers.
Refer
this book for more details.
Related Article:Pointers in C and C++ | Set 1 (Introduction, Arithmetic and Array)
What are near, far and huge pointers?
These are some old concepts used in 16 bit intel architectures in the days of MS DOS, not much useful anymore.
Near pointer is used to store 16 bit addresses means within current segment on a 16 bit machine.
The limitation is that we can only access 64kb of data at a time.
A far pointer is typically 32 bit that can access memory outside current segment. To use this, compiler allocates a segment register to store segment address, then another register to store offset within current segment.
Like far pointer,
huge pointer is also typically 32 bit and can access outside segment.
In case of far pointers, a segment is fixed. In far pointer, the segment part cannot be modified, but in Huge it can be
See below links for more details.
http://www.answers.com/Q/What_are_near_far_and_huge_pointers_in_C
https://www.quora.com/What-is-the-difference-between-near-far-huge-pointers-in-C-C++
http://stackoverflow.com/questions/8727122/explain-the-difference-between-near-far-and-huge-pointers-in-c
Generic Linked List in C
Unlike
C++ and
Java,
C doesn’t support generics.
How to create a linked list in C that can be used for any data type? In C, we can use
void pointer and function pointer to implement the same functionality.
The great thing about void pointer is it can be used to point to any data type.
Also, size of all types of pointers is always is same, so we can always allocate a linked list node.
Function pointer is needed process actual content stored at address pointed by void pointer.
Following is a sample C code to demonstrate working of generic linked list.
#include<stdio.h>
#include<stdlib.h>
struct Node
{
void *data;
struct Node *next;
};
void push(struct Node** head_ref, void *new_data, size_t data_size)
{
struct Node* new_node = (struct Node*)malloc(sizeof(struct Node));
new_node->data = malloc(data_size);
new_node->next = (*head_ref);
int i;
for (i=0; i<data_size; i++)
*(char *)(new_node->data + i) = *(char *)(new_data + i);
(*head_ref) = new_node;
}
void printList(struct Node *node, void (*fptr)(void *))
{
while (node != NULL)
{
(*fptr)(node->data);
node = node->next;
}
}
void printInt(void *n)
{
printf(" %d", *(int *)n);
}
void printFloat(void *f)
{
printf(" %f", *(float *)f);
}
int main()
{
struct Node *start = NULL;
unsigned int_size = sizeof(int);
int arr[] = {10, 20, 30, 40, 50}, i;
for (i=4; i>=0; i--)
push(&start, &arr[i], int_size);
printf("Created integer linked list is \n");
printList(start, printInt);
unsigned float_size = sizeof(float);
start = NULL;
float arr2[] = {10.1, 20.2, 30.3, 40.4, 50.5};
for (i=4; i>=0; i--)
push(&start, &arr2[i], float_size);
printf("\n\nCreated float linked list is \n");
printList(start, printFloat);
return 0;
}
Output:
Created integer linked list is
10 20 30 40 50
Created float linked list is
10.100000 20.200001 30.299999 40.400002 50.500000
restrict keyword in C
In the
C programming language (after 99 standard), a new keyword is introduced known as restrict.
- restrict keyword is mainly used in pointer declarations as a type qualifier for pointers.
- It doesn’t add any new functionality.
It is only a way for programmer to inform about an optimizations that compiler can make.
- When we use restrict with a pointer ptr, it tells the compiler that ptr is the only way to access the object pointed by it and compiler doesn’t need to add any additional checks.
- If a programmer uses restrict keyword and violate the above condition, result is undefined behavior.
- restrict is not supported by C++.
It is a C only keyword.
#include <stdio.h>
void use(int* a, int* b, int* restrict c)
{
*a += *c;
*b += *c;
}
int main(void)
{
int a = 50, b = 60, c = 70;
use(&a, &b, &c);
printf("%d %d %d", a, b, c);
return 0;
}
Output:
120 130 70
Difference between const char *p, char * const p and const char * const p
Prerequisite:
Pointers
There is a lot of confusion when char, const, *, p are all used in different permutaions and meanings change according to which is placed where.
Following article focus on differentiation and usage of all of these.
The qualifier
const can be applied to the declaration of any variable to specify that its value will not be changed.
const keyword applies to whatever is immediately to its left.
If there is nothing to its left, it applies to whatever is immediately to its right.
- const char *ptr : This is a pointer to a constant character. You cannot change the value pointed by ptr, but you can change the pointer itself.
“const char *” is a (non-const) pointer to a const char.
#include<stdio.h>
#include<stdlib.h>
int main()
{
char a ='A', b ='B';
const char *ptr = &a;
printf( "value pointed to by ptr: %c\n", *ptr);
ptr = &b;
printf( "value pointed to by ptr: %c\n", *ptr);
}
Output:
value pointed to by ptr:A
value pointed to by ptr:B
NOTE: There is no difference between const char *p and char const *p as both are pointer to a const char and position of ‘*'(asterik) is also same.
- char *const ptr : This is a constant pointer to non-constant character.
You cannot change the pointer p, but can change the value pointed by ptr.
#include<stdio.h>
#include<stdlib.h>
int main()
{
char a ='A', b ='B';
char *const ptr = &a;
printf( "Value pointed to by ptr: %c\n", *ptr);
printf( "Address ptr is pointing to: %d\n\n", ptr);
*ptr = b;
printf( "Value pointed to by ptr: %c\n", *ptr);
printf( "Address ptr is pointing to: %d\n", ptr);
}
Output:
Value pointed to by ptr: A
Address ptr is pointing to: -1443150762
Value pointed to by ptr: B
Address ptr is pointing to: -1443150762
NOTE: Pointer always points to same address, only the value at the location is changed.
-
const char * const ptr : This is a constant pointer to constant character.
You can neither change the value pointed by ptr nor the pointer ptr.
#include<stdio.h>
#include<stdlib.h>
int main()
{
char a ='A', b ='B';
const char *const ptr = &a;
printf( "Value pointed to by ptr: %c\n", *ptr);
printf( "Address ptr is pointing to: %d\n\n", ptr);
}
Output:
Value pointed to by ptr: A
Address ptr is pointing to: -255095482
NOTE: char const * const ptr is same as const char *const ptr.
Quiz on const keyword
Pointer to an Array | Array Pointer
Prerequisite:
Pointers Introduction
Pointer to Array
Consider the following program:
#include<stdio.h>
int main()
{
int arr[5] = { 1, 2, 3, 4, 5 };
int *ptr = arr;
printf("%p\n", ptr);
return 0;
}
In this program, we have a pointer ptr that points to the 0th element of the array.
Similarly, we can also declare a pointer that can point to whole array instead of only one element of the array.
This pointer is useful when talking about multidimensional arrays.
Syntax:
data_type (*var_name)[size_of_array];
Example:
int (*ptr)[10];
Here
ptr is pointer that can point to an array of 10 integers.
Since subscript have higher precedence than indirection, it is necessary to enclose the indirection operator and pointer name inside parentheses.
Here the type of ptr is ‘pointer to an array of 10 integers’.
Note : The pointer that points to the 0
th element of array and the pointer that points to the whole array are totally different.
The following program shows this:
#include<stdio.h>
int main()
{
int *p;
int (*ptr)[5];
int arr[5];
p = arr;
ptr = &arr;
printf("p = %p, ptr = %p\n", p, ptr);
p++;
ptr++;
printf("p = %p, ptr = %p\n", p, ptr);
return 0;
}
Output:
p = 0x7fff4f32fd50, ptr = 0x7fff4f32fd50
p = 0x7fff4f32fd54, ptr = 0x7fff4f32fd64
p: is pointer to 0
th element of the array
arr, while
ptr is a pointer that points to the whole array
arr.
- The base type of p is int while base type of ptr is ‘an array of 5 integers’.
- We know that the pointer arithmetic is performed relative to the base size, so if we write ptr++, then the pointer ptr will be shifted forward by 20 bytes.
The following figure shows the pointer p and ptr.
Darker arrow denotes pointer to an array.
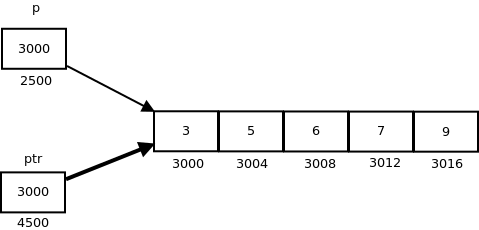
On dereferencing a pointer expression we get a value pointed to by that pointer expression.
Pointer to an array points to an array, so on dereferencing it, we should get the array, and the name of array denotes the base address.
So whenever a pointer to an array is dereferenced, we get the base address of the array to which it points.
#include<stdio.h>
int main()
{
int arr[] = { 3, 5, 6, 7, 9 };
int *p = arr;
int (*ptr)[5] = &arr;
printf("p = %p, ptr = %p\n", p, ptr);
printf("*p = %d, *ptr = %p\n", *p, *ptr);
printf("sizeof(p) = %lu, sizeof(*p) = %lu\n",
sizeof(p), sizeof(*p));
printf("sizeof(ptr) = %lu, sizeof(*ptr) = %lu\n",
sizeof(ptr), sizeof(*ptr));
return 0;
}
Output:
p = 0x7ffde1ee5010, ptr = 0x7ffde1ee5010
*p = 3, *ptr = 0x7ffde1ee5010
sizeof(p) = 8, sizeof(*p) = 4
sizeof(ptr) = 8, sizeof(*ptr) = 20
Pointer to Multidimensional Arrays
- Pointers and two dimensional Arrays:
In a two dimensional array, we can access each element by using two subscripts, where first subscript represents the row number and second subscript represents the column number.
The elements of 2-D array can be accessed with the help of pointer notation also.
Suppose arr is a 2-D array, we can access any element arr[i][j] of the array using the pointer expression *(*(arr + i) + j).
Now we’ll see how this expression can be derived.
Let us take a two dimensional array arr[3][4]:
int arr[3][4] = { {1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12} };

Since memory in a computer is organized linearly it is not possible to store the 2-D array in rows and columns.
The concept of rows and columns is only theoretical, actually, a 2-D array is stored in row-major order i.e rows are placed next to each other.
The following figure shows how the above 2-D array will be stored in memory.

Each row can be considered as a 1-D array, so a two-dimensional array can be considered as a collection of one-dimensional arrays that are placed one after another.
In other words, we can say that 2-D dimensional arrays that are placed one after another.
So here
arr is an array of 3 elements where each element is a 1-D array of 4 integers.
We know that the name of an array is a constant pointer that points to 0
th 1-D array and contains address 5000.
Since
arr is a ‘pointer to an array of 4 integers’, according to pointer arithmetic the expression arr + 1 will represent the address 5016 and expression arr + 2 will represent address 5032.
So we can say that
arr points to the 0
th 1-D array,
arr + 1 points to the 1
st 1-D array and
arr + 2 points to the 2
nd 1-D array.
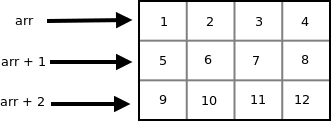

In general we can write:
arr + i Points to ith element of arr ->
Points to ith 1-D array
- Since arr + i points to ith element of arr, on dereferencing it will get ith element of arr which is of course a 1-D array.
Thus the expression *(arr + i) gives us the base address of ith 1-D array.
- We know, the pointer expression *(arr + i) is equivalent to the subscript expression arr[i].
So *(arr + i) which is same as arr[i] gives us the base address of ith 1-D array.
 In general we can write:
In general we can write:
*(arr + i) - arr[i] - Base address of ith 1-D array -> Points to 0th element of ith 1-D array
Note: Both the expressions
(arr + i) and
*(arr + i) are pointers, but their base type are different.
The base type of
(arr + i) is ‘an array of 4 units’ while the base type of *(arr + i) or arr[i] is int.
- To access an individual element of our 2-D array, we should be able to access any jth element of ith 1-D array.
- Since the base type of *(arr + i) is int and it contains the address of 0th element of ith 1-D array, we can get the addresses of subsequent elements in the ith 1-D array by adding integer values to *(arr + i).
- For example *(arr + i) + 1 will represent the address of 1st element of 1stelement of ith 1-D array and *(arr+i)+2 will represent the address of 2nd element of ith 1-D array.
- Similarly *(arr + i) + j will represent the address of jth element of ith 1-D array.
On dereferencing this expression we can get the jth element of the ith 1-D array.

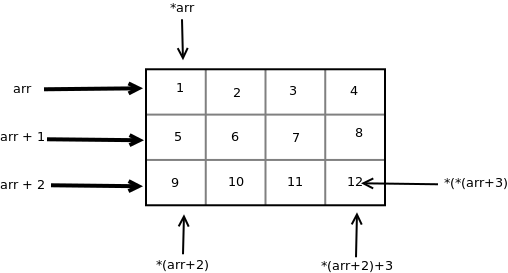
#include<stdio.h>
int main()
{
int arr[3][4] = {
{ 10, 11, 12, 13 },
{ 20, 21, 22, 23 },
{ 30, 31, 32, 33 }
};
int i, j;
for (i = 0; i < 3; i++)
{
printf("Address of %dth array = %p %p\n",
i, arr[i], *(arr + i));
for (j = 0; j < 4; j++)
printf("%d %d ", arr[i][j], *(*(arr + i) + j));
printf("\n");
}
return 0;
}
Output:
Address of 0th array = 0x7ffe50edd580 0x7ffe50edd580
10 10 11 11 12 12 13 13
Address of 1th array = 0x7ffe50edd590 0x7ffe50edd590
20 20 21 21 22 22 23 23
Address of 2th array = 0x7ffe50edd5a0 0x7ffe50edd5a0
30 30 31 31 32 32 33 33
Pointers and Three Dimensional Arrays
In a three dimensional array we can access each element by using three subscripts.
Let us take a 3-D array-
int arr[2][3][2] = { {{5, 10}, {6, 11}, {7, 12}}, {{20, 30}, {21, 31}, {22, 32}} };
We can consider a three dimensional array to be an array of 2-D array i.e each element of a 3-D array is considered to be a 2-D array.
The 3-D array arr can be considered as an array consisting of two elements where each element is a 2-D array.
The name of the array arr is a pointer to the 0th 2-D array.

Thus the pointer expression *(*(*(arr + i ) + j ) + k) is equivalent to the subscript expression arr[i][j][k].
We know the expression *(arr + i) is equivalent to arr[i] and the expression *(*(arr + i) + j) is equivalent arr[i][j].
So we can say that arr[i] represents the base address of ith 2-D array and arr[i][j] represents the base address of the jth 1-D array.
#include<stdio.h>
int main()
{
int arr[2][3][2] = {
{
{5, 10},
{6, 11},
{7, 12},
},
{
{20, 30},
{21, 31},
{22, 32},
}
};
int i, j, k;
for (i = 0; i < 2; i++)
{
for (j = 0; j < 3; j++)
{
for (k = 0; k < 2; k++)
printf("%d\t", *(*(*(arr + i) + j) +k));
printf("\n");
}
}
return 0;
}
Output:
5 10
6 11
7 12
20 30
21 31
22 32
The following figure shows how the 3-D array used in the above program is stored in memory.

Subscripting Pointer to an Array
Suppose arr is a 2-D array with 3 rows and 4 columns and ptr is a pointer to an array of 4 integers, and ptr contains the base address of array arr.
int arr[3][4] = {{10, 11, 12, 13}, {20, 21, 22, 23}, {30, 31, 32, 33}};
int (*ptr)[4];
ptr = arr;

Since
ptr is a pointer to an array of 4 integers,
ptr + i will point to i
th row.
On dereferencing
ptr + i, we get base address of i
th row.
To access the address of j
th element of i
th row we can add j to the pointer expression
*(ptr + i).
So the pointer expression
*(ptr + i) + j gives the address of j
th element of i
th row and the pointer expression
*(*(ptr + i)+j) gives the value of the j
th element of i
th row.
We know that the pointer expression *(*(ptr + i) + j) is equivalent to subscript expression ptr[i][j].
So if we have a pointer variable containing the base address of 2-D array, then we can access the elements of array by double subscripting that pointer variable.
#include<stdio.h>
int main()
{
int arr[3][4] = {
{10, 11, 12, 13},
{20, 21, 22, 23},
{30, 31, 32, 33}
};
int (*ptr)[4];
ptr = arr;
printf("%p %p %p\n", ptr, ptr + 1, ptr + 2);
printf("%p %p %p\n", *ptr, *(ptr + 1), *(ptr + 2));
printf("%d %d %d\n", **ptr, *(*(ptr + 1) + 2), *(*(ptr + 2) + 3));
printf("%d %d %d\n", ptr[0][0], ptr[1][2], ptr[2][3]);
return 0;
}
Output:
0x7ffead967560 0x7ffead967570 0x7ffead967580
0x7ffead967560 0x7ffead967570 0x7ffead967580
10 22 33
10 22 33
Enumeration (or enum) in C
Enumeration (or enum) is a user defined data type in C.
It is mainly used to assign names to integral constants, the names make a program easy to read and maintain.
enum State {Working = 1, Failed = 0};
The keyword ‘enum’ is used to declare new enumeration types in C and C++.
Following is an example of enum declaration.
// The name of enumeration is "flag" and the constant
// are the values of the flag.
By default, the values
// of the constants are as follows:
// constant1 = 0, constant2 = 1, constant3 = 2 and
// so on.
enum flag{constant1, constant2, constant3, .......
};
Variables of type enum can also be defined.
They can be defined in two ways:
// In both of the below cases, "day" is
// defined as the variable of type week.
enum week{Mon, Tue, Wed};
enum week day;
// Or
enum week{Mon, Tue, Wed}day;
#include<stdio.h>
enum week{Mon, Tue, Wed, Thur, Fri, Sat, Sun};
int main()
{
enum week day;
day = Wed;
printf("%d",day);
return 0;
}
Output:
2
In the above example, we declared “day” as the variable and the value of “Wed” is allocated to day, which is 2.
So as a result, 2 is printed.
Another example of enumeration is:
#include<stdio.h>
enum year{Jan, Feb, Mar, Apr, May, Jun, Jul,
Aug, Sep, Oct, Nov, Dec};
int main()
{
int i;
for (i=Jan; i<=Dec; i++)
printf("%d ", i);
return 0;
}
Output:
0 1 2 3 4 5 6 7 8 9 10 11
In this example, the for loop will run from i = 0 to i = 11, as initially the value of i is Jan which is 0 and the value of Dec is 11.
Interesting facts about initialization of enum.
1. Two enum names can have same value.
For example, in the following C program both ‘Failed’ and ‘Freezed’ have same value 0.
#include <stdio.h>
enum State {Working = 1, Failed = 0, Freezed = 0};
int main()
{
printf("%d, %d, %d", Working, Failed, Freezed);
return 0;
}
Output:
1, 0, 0
2. If we do not explicitly assign values to enum names, the compiler by default assigns values starting from 0.
For example, in the following C program, sunday gets value 0, monday gets 1, and so on.
#include <stdio.h>
enum day {sunday, monday, tuesday, wednesday, thursday, friday, saturday};
int main()
{
enum day d = thursday;
printf("The day number stored in d is %d", d);
return 0;
}
Output:
The day number stored in d is 4
3. We can assign values to some name in any order.
All unassigned names get value as value of previous name plus one.
#include <stdio.h>
enum day {sunday = 1, monday, tuesday = 5,
wednesday, thursday = 10, friday, saturday};
int main()
{
printf("%d %d %d %d %d %d %d", sunday, monday, tuesday,
wednesday, thursday, friday, saturday);
return 0;
}
Output:
1 2 5 6 10 11 12
4. The value assigned to enum names must be some integeral constant, i.e., the value must be in range from minimum possible integer value to maximum possible integer value.
5. All enum constants must be unique in their scope.
For example, the following program fails in compilation.
enum state {working, failed};
enum result {failed, passed};
int main() { return 0; }
Output:
Compile Error: 'failed' has a previous declaration as 'state failed'
Exercise:
Predict the output of following C programs
Program 1:
#include <stdio.h>
enum day {sunday = 1, tuesday, wednesday, thursday, friday, saturday};
int main()
{
enum day d = thursday;
printf("The day number stored in d is %d", d);
return 0;
}
Program 2:
#include <stdio.h>
enum State {WORKING = 0, FAILED, FREEZED};
enum State currState = 2;
enum State FindState() {
return currState;
}
int main() {
(FindState() == WORKING)? printf("WORKING"): printf("NOT WORKING");
return 0;
}
Enum vs Macro
We can also use macros to define names constants.
For example we can define ‘Working’ and ‘Failed’ using following macro.
#define Working 0
#define Failed 1
#define Freezed 2
There are multiple advantages of using enum over macro when many related named constants have integral values.
a) Enums follow scope rules.
b) Enum variables are automatically assigned values.
Following is simpler
enum state {Working, Failed, Freezed};
Structures in C
What is a structure?
A structure is a user defined data type in C/C++.
A structure creates a data type that can be used to group items of possibly different types into a single type.
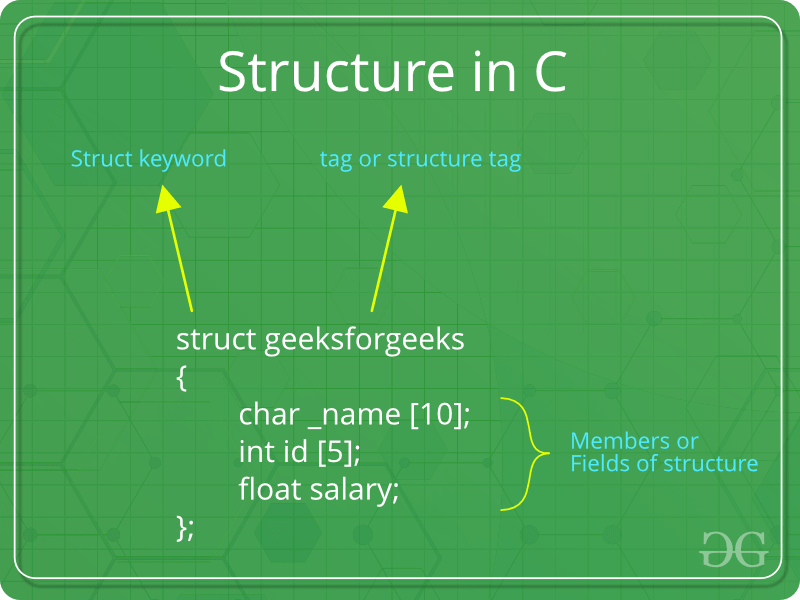 How to create a structure?
How to create a structure?
‘struct’ keyword is used to create a structure.
Following is an example.
struct address
{
char name[50];
char street[100];
char city[50];
char state[20];
int pin;
};
How to declare structure variables?
A structure variable can either be declared with structure declaration or as a separate declaration like basic types.
struct Point
{
int x, y;
} p1;
struct Point
{
int x, y;
};
int main()
{
struct Point p1;
}
Note: In C++, the struct keyword is optional before in declaration of a variable.
In C, it is mandatory.
How to initialize structure members?
Structure members
cannot be initialized with declaration.
For example the following C program fails in compilation.
struct Point
{
int x = 0;
int y = 0;
};
The reason for above error is simple, when a datatype is declared, no memory is allocated for it.
Memory is allocated only when variables are created.
Structure members
can be initialized using curly braces ‘{}’.
For example, following is a valid initialization.
struct Point
{
int x, y;
};
int main()
{
struct Point p1 = {0, 1};
}
How to access structure elements?
Structure members are accessed using dot (.) operator.
#include<stdio.h>
struct Point
{
int x, y;
};
int main()
{
struct Point p1 = {0, 1};
p1.x = 20;
printf ("x = %d, y = %d", p1.x, p1.y);
return 0;
}
Output:
x = 20, y = 1
What is designated Initialization?
Designated Initialization allows structure members to be initialized in any order.
This feature has been added in
C99 standard.
#include<stdio.h>
struct Point
{
int x, y, z;
};
int main()
{
struct Point p1 = {.y = 0, .z = 1, .x = 2};
struct Point p2 = {.x = 20};
printf ("x = %d, y = %d, z = %d\n", p1.x, p1.y, p1.z);
printf ("x = %d", p2.x);
return 0;
}
Output:
x = 2, y = 0, z = 1
x = 20
This feature is not available in C++ and works only in C.
What is an array of structures?
Like other primitive data types, we can create an array of structures.
#include<stdio.h>
struct Point
{
int x, y;
};
int main()
{
struct Point arr[10];
arr[0].x = 10;
arr[0].y = 20;
printf("%d %d", arr[0].x, arr[0].y);
return 0;
}
Output:
10 20
What is a structure pointer?
Like primitive types, we can have pointer to a structure.
If we have a pointer to structure, members are accessed using arrow ( -> ) operator.
#include<stdio.h>
struct Point
{
int x, y;
};
int main()
{
struct Point p1 = {1, 2};
struct Point *p2 = &p1;
printf("%d %d", p2->x, p2->y);
return 0;
}
Output:
1 2
What is structure member alignment?
See
https://www.geeksforgeeks.org/structure-member-alignment-padding-and-data-packing/
Limitations of C Structures
In C language, Structures provide a method for packing together data of different types.
A Structure is a helpful tool to handle a group of logically related data items.
However, C structures have some limitations.
The C structure does not allow the struct data type to be treated like built-in data types:
We cannot use operators like +,- etc.
on Structure variables.
For example, consider the following code:
struct number
{
float x;
};
int main()
{
struct number n1,n2,n3;
n1.x=4;
n2.x=3;
n3=n1+n2;
return 0;
}
No Data Hiding: C Structures do not permit data hiding.
Structure members can be accessed by any function, anywhere in the scope of the Structure.
Functions inside Structure: C structures do not permit functions inside Structure
Static Members: C Structures cannot have static members inside their body
Access Modifiers: C Programming language do not support access modifiers.
So they cannot be used in C Structures.
Construction creation in Structure: Structures in C cannot have constructor inside Structures.
Related Article : C Structures vs C++ Structures
Union in C
Like
Structures, union is a user defined data type.
In union, all members share the same memory location.
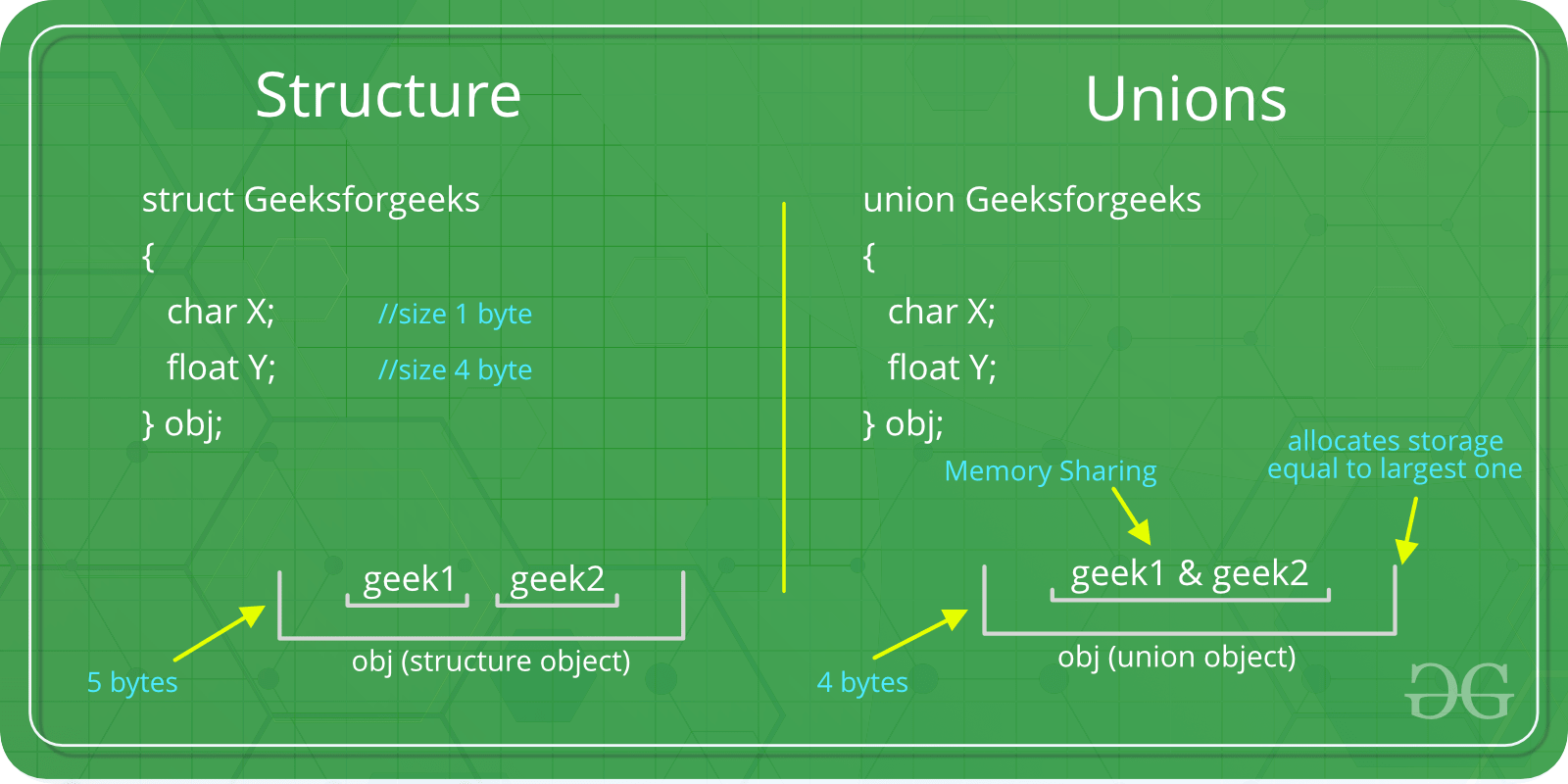
For example in the following C program, both x and y share the same location. If we change x, we can see the changes being reflected in y.
#include <stdio.h>
union test {
int x, y;
};
int main()
{
union test t;
t.x = 2;
printf("After making x = 2:\n x = %d, y = %d\n\n",
t.x, t.y);
t.y = 10;
printf("After making y = 10:\n x = %d, y = %d\n\n",
t.x, t.y);
return 0;
}
Output:
After making x = 2:
x = 2, y = 2
After making y = 10:
x = 10, y = 10
How is the size of union decided by compiler?
Size of a union is taken according the size of largest member in union.
#include <stdio.h>
union test1 {
int x;
int y;
} Test1;
union test2 {
int x;
char y;
} Test2;
union test3 {
int arr[10];
char y;
} Test3;
int main()
{
printf("sizeof(test1) = %lu, sizeof(test2) = %lu, "
"sizeof(test3) = %lu",
sizeof(Test1),
sizeof(Test2), sizeof(Test3));
return 0;
}
Output:
sizeof(test1) = 4, sizeof(test2) = 4, sizeof(test3) = 40
Pointers to unions?
Like structures, we can have pointers to unions and can access members using the arrow operator (->).
The following example demonstrates the same.
#include <stdio.h>
union test {
int x;
char y;
};
int main()
{
union test p1;
p1.x = 65;
union test* p2 = &p1;
printf("%d %c", p2->x, p2->y);
return 0;
}
Output:
65 A
What are applications of union?
Unions can be useful in many situations where we want to use the same memory for two or more members.
For example, suppose we want to implement a binary tree data structure where each leaf node has a double data value, while each internal node has pointers to two children, but no data.
If we declare this as:
struct NODE {
struct NODE* left;
struct NODE* right;
double data;
};
then every node requires 16 bytes, with half the bytes wasted for each type of node.
On the other hand, if we declare a node as following, then we can save space.
struct NODE {
bool is_leaf;
union {
struct
{
struct NODE* left;
struct NODE* right;
} internal;
double data;
} info;
};
The above example is taken from
Computer Systems : A Programmer’s Perspective (English) 2nd Edition book.
Struct Hack
What will be the size of following structure?
struct employee
{
int emp_id;
int name_len;
char name[0];
};
4 + 4 + 0 = 8 bytes.
And what about size of “name[0]”.
In gcc, when we create an array of zero length, it is considered as array of incomplete type that’s why gcc reports its size as “0” bytes.
This technique is known as “Stuct Hack”.
When we create array of zero length inside structure, it must be (and only) last member of structure.
Shortly we will see how to use it.
“Struct Hack” technique is used to create variable length member in a structure.
In the above structure, string length of “name” is not fixed, so we can use “name” as variable length array.
Let us see below memory allocation.
struct employee *e = malloc(sizeof(*e) + sizeof(char) * 128);
is equivalent to
struct employee
{
int emp_id;
int name_len;
char name[128];
};
And below memory allocation
struct employee *e = malloc(sizeof(*e) + sizeof(char) * 1024);
is equivalent to
struct employee
{
int emp_id;
int name_len;
char name[1024];
};
Note: since name is character array, in malloc instead of “sizeof(char) * 128”, we can use “128” directly.
sizeof is used to avoid confusion.
Now we can use “name” same as pointer.
e.g.
e->emp_id = 100;
e->name_len = strlen("Geeks For Geeks");
strncpy(e->name, "Geeks For Geeks", e->name_len);
When we allocate memory as given above, compiler will allocate memory to store “emp_id” and “name_len” plus contiguous memory to store “name”.
When we use this technique, gcc guaranties that, “name” will get contiguous memory.
Obviously there are other ways to solve problem, one is we can use character pointer.
But there is no guarantee that character pointer will get contiguous memory, and we can take advantage of this contiguous memory.
For example, by using this technique, we can allocate and deallocate memory by using single malloc and free call (because memory is contagious).
Other advantage of this is, suppose if we want to write data, we can write whole data by using single “write()” call.
e.g.
write(fd, e, sizeof(*e) + name_len); /* write emp_id + name_len + name */
If we use character pointer, then we need 2 write calls to write data.
e.g.
write(fd, e, sizeof(*e)); /* write emp_id + name_len */
write(fd, e->name, e->name_len); /* write name */
Note: In C99, there is feature called “flexible array members”, which works same as “Struct Hack”
Structure Member Alignment, Padding and Data Packing
What do we mean by data alignment, structure packing and padding?
Predict the output of following program.
#include <stdio.h>
typedef struct structa_tag
{
char c;
short int s;
} structa_t;
typedef struct structb_tag
{
short int s;
char c;
int i;
} structb_t;
typedef struct structc_tag
{
char c;
double d;
int s;
} structc_t;
typedef struct structd_tag
{
double d;
int s;
char c;
} structd_t;
int main()
{
printf("sizeof(structa_t) = %d\n", sizeof(structa_t));
printf("sizeof(structb_t) = %d\n", sizeof(structb_t));
printf("sizeof(structc_t) = %d\n", sizeof(structc_t));
printf("sizeof(structd_t) = %d\n", sizeof(structd_t));
return 0;
}
Before moving further, write down your answer on a paper, and read on.
If you urge to see explanation, you may miss to understand any lacuna in your analogy.
Data Alignment:
Every data type in C/C++ will have alignment requirement (infact it is mandated by processor architecture, not by language). A processor will have processing word length as that of data bus size.
On a 32 bit machine, the processing word size will be 4 bytes.
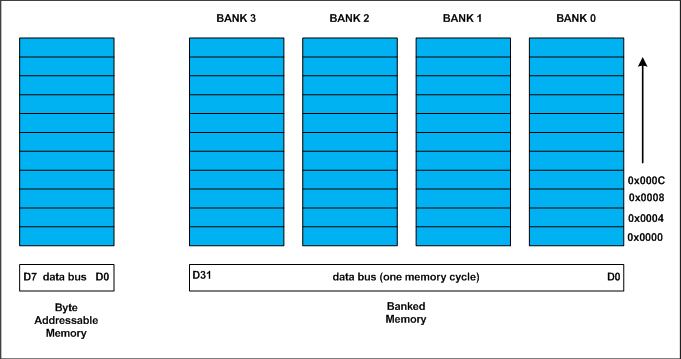
Historically memory is byte addressable and arranged sequentially.
If the memory is arranged as single bank of one byte width, the processor needs to issue 4 memory read cycles to fetch an integer.
It is more economical to read all 4 bytes of integer in one memory cycle.
To take such advantage, the memory will be arranged as group of 4 banks as shown in the above figure.
The memory addressing still be sequential.
If bank 0 occupies an address X, bank 1, bank 2 and bank 3 will be at (X + 1), (X + 2) and (X + 3) addresses.
If an integer of 4 bytes is allocated on X address (X is multiple of 4), the processor needs only one memory cycle to read entire integer.
Where as, if the integer is allocated at an address other than multiple of 4, it spans across two rows of the banks as shown in the below figure.
Such an integer requires two memory read cycle to fetch the data.
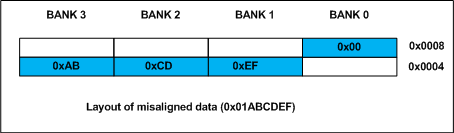
A variable’s
data alignment deals with the way the data stored in these banks.
For example, the natural alignment of
int on 32-bit machine is 4 bytes.
When a data type is naturally aligned, the CPU fetches it in minimum read cycles.
Similarly, the natural alignment of
short int is 2 bytes.
It means, a
short int can be stored in bank 0 – bank 1 pair or bank 2 – bank 3 pair.
A
double requires 8 bytes, and occupies two rows in the memory banks.
Any misalignment of
double will force more than two read cycles to fetch
double data.
Note that a
double variable will be allocated on 8 byte boundary on 32 bit machine and requires two memory read cycles.
On a 64 bit machine, based on number of banks,
double variable will be allocated on 8 byte boundary and requires only one memory read cycle.
Structure Padding:
In C/C++ a structures are used as data pack.
It doesn’t provide any data encapsulation or data hiding features (C++ case is an exception due to its semantic similarity with classes).
Because of the alignment requirements of various data types, every member of structure should be naturally aligned.
The members of structure allocated sequentially increasing order.
Let us analyze each struct declared in the above program.
Output of Above Program:
For the sake of convenience, assume every structure type variable is allocated on 4 byte boundary (say 0x0000), i.e.
the base address of structure is multiple of 4 (need not necessary always, see explanation of structc_t).
structure A
The structa_t first element is char which is one byte aligned, followed by short int.
short int is 2 byte aligned.
If the the short int element is immediately allocated after the char element, it will start at an odd address boundary.
The compiler will insert a padding byte after the char to ensure short int will have an address multiple of 2 (i.e.
2 byte aligned).
The total size of structa_t will be sizeof(char) + 1 (padding) + sizeof(short), 1 + 1 + 2 = 4 bytes.
structure B
The first member of structb_t is short int followed by char.
Since char can be on any byte boundary no padding required in between short int and char, on total they occupy 3 bytes.
The next member is int.
If the int is allocated immediately, it will start at an odd byte boundary.
We need 1 byte padding after the char member to make the address of next int member is 4 byte aligned.
On total, the structb_t requires 2 + 1 + 1 (padding) + 4 = 8 bytes.
structure C – Every structure will also have alignment requirements
Applying same analysis, structc_t needs sizeof(char) + 7 byte padding + sizeof(double) + sizeof(int) = 1 + 7 + 8 + 4 = 20 bytes.
However, the sizeof(structc_t) will be 24 bytes.
It is because, along with structure members, structure type variables will also have natural alignment.
Let us understand it by an example.
Say, we declared an array of structc_t as shown below
structc_t structc_array[3];
Assume, the base address of structc_array is 0x0000 for easy calculations.
If the structc_t occupies 20 (0x14) bytes as we calculated, the second structc_t array element (indexed at 1) will be at 0x0000 + 0x0014 = 0x0014.
It is the start address of index 1 element of array.
The double member of this structc_t will be allocated on 0x0014 + 0x1 + 0x7 = 0x001C (decimal 28) which is not multiple of 8 and conflicting with the alignment requirements of double.
As we mentioned on the top, the alignment requirement of double is 8 bytes.
Inorder to avoid such misalignment, compiler will introduce alignment requirement to every structure.
It will be as that of the largest member of the structure.
In our case alignment of structa_t is 2, structb_t is 4 and structc_t is 8.
If we need nested structures, the size of largest inner structure will be the alignment of immediate larger structure.
In structc_t of the above program, there will be padding of 4 bytes after int member to make the structure size multiple of its alignment.
Thus the sizeof (structc_t) is 24 bytes. It guarantees correct alignment even in arrays.
You can cross check.
structure D – How to Reduce Padding?
By now, it may be clear that padding is unavoidable.
There is a way to minimize padding.
The programmer should declare the structure members in their increasing/decreasing order of size.
An example is structd_t given in our code, whose size is 16 bytes in lieu of 24 bytes of structc_t.
What is structure packing?
Some times it is mandatory to avoid padded bytes among the members of structure.
For example, reading contents of ELF file header or BMP or JPEG file header.
We need to define a structure similar to that of the header layout and map it.
However, care should be exercised in accessing such members.
Typically reading byte by byte is an option to avoid misaligned exceptions.
There will be hit on performance.
Most of the compilers provide non standard extensions to switch off the default padding like pragmas or command line switches.
Consult the documentation of respective compiler for more details.
Pointer Mishaps:
There is possibility of potential error while dealing with pointer arithmetic.
For example, dereferencing a generic pointer (void *) as shown below can cause misaligned exception,
// Deferencing a generic pointer (not safe)
// There is no guarantee that pGeneric is integer aligned
*(int *)pGeneric;
It is possible above type of code in programming.
If the pointer
pGeneric is not aligned as per the requirements of casted data type, there is possibility to get misaligned exception.
Infact few processors will not have the last two bits of address decoding, and there is no way to access
misaligned address.
The processor generates misaligned exception, if the programmer tries to access such address.
A note on malloc() returned pointer
The pointer returned by malloc() is
void *.
It can be converted to any data type as per the need of programmer.
The implementer of malloc() should return a pointer that is aligned to maximum size of primitive data types (those defined by compiler).
It is usually aligned to 8 byte boundary on 32 bit machines.
Object File Alignment, Section Alignment, Page Alignment
These are specific to operating system implementer, compiler writers and are beyond the scope of this article.
Infact, I don’t have much information.
General Questions:
1.
Is alignment applied for stack?
Yes.
The stack is also memory.
The system programmer should load the stack pointer with a memory address that is properly aligned.
Generally, the processor won’t check stack alignment, it is the programmer’s responsibility to ensure proper alignment of stack memory.
Any misalignment will cause run time surprises.
For example, if the processor word length is 32 bit, stack pointer also should be aligned to be multiple of 4 bytes.
2.
If char data is placed in a bank other bank 0, it will be placed on wrong data lines during memory read.
How the processor handles char type?
Usually, the processor will recognize the data type based on instruction (e.g.
LDRB on ARM processor).
Depending on the bank it is stored, the processor shifts the byte onto least significant data lines.
3.
When arguments passed on stack, are they subjected to alignment?
Yes.
The compiler helps programmer in making proper alignment.
For example, if a 16-bit value is pushed onto a 32-bit wide stack, the value is automatically padded with zeros out to 32 bits. Consider the following program.
void argument_alignment_check( char c1, char c2 )
{
printf("Displacement %d\n", (int)&c2 - (int)&c1);
}
The output will be 4 on a 32 bit machine.
It is because each character occupies 4 bytes due to alignment requirements.
4.
What will happen if we try to access a misaligned data?
It depends on processor architecture.
If the access is misaligned, the processor automatically issues sufficient memory read cycles and packs the data properly onto the data bus.
The penalty is on performance.
Where as few processors will not have last two address lines, which means there is no-way to access odd byte boundary.
Every data access must be aligned (4 bytes) properly.
A misaligned access is critical exception on such processors.
If the exception is ignored, read data will be incorrect and hence the results.
5.
Is there any way to query alignment requirements of a data type.
Yes.
Compilers provide non standard extensions for such needs.
For example, __alignof() in Visual Studio helps in getting the alignment requirements of data type.
Read MSDN for details.
6.
When memory reading is efficient in reading 4 bytes at a time on 32 bit machine, why should a double type be aligned on 8 byte boundary?
It is important to note that most of the processors will have math co-processor, called Floating Point Unit (FPU).
Any floating point operation in the code will be translated into FPU instructions.
The main processor is nothing to do with floating point execution.
All this will be done behind the scenes.
As per standard, double type will occupy 8 bytes.
And, every floating point operation performed in FPU will be of 64 bit length.
Even float types will be promoted to 64 bit prior to execution.
The 64 bit length of FPU registers forces double type to be allocated on 8 byte boundary.
I am assuming (I don’t have concrete information) in case of FPU operations, data fetch might be different, I mean the data bus, since it goes to FPU.
Hence, the address decoding will be different for double types (which is expected to be on 8 byte boundary).
It means,
the address decoding circuits of floating point unit will not have last 3 pins.
Answers:
sizeof(structa_t) = 4
sizeof(structb_t) = 8
sizeof(structc_t) = 24
sizeof(structd_t) = 16
Update: 1-May-2013
It is observed that on latest processors we are getting size of struct_c as 16 bytes.
I yet to read relevant documentation.
I will update once I got proper information (written to few experts in hardware).
On older processors (AMD Athlon X2) using same set of tools (GCC 4.7) I got struct_c size as 24 bytes.
The size depends on how memory banking organized at the hardware level.
Operations on struct variables in C
In C, the only operation that can be applied to
struct variables is assignment.
Any other operation (e.g.
equality check) is not allowed on
struct variables.
For example, program 1 works without any error and program 2 fails in compilation.
Program 1
#include <stdio.h>
struct Point {
int x;
int y;
};
int main()
{
struct Point p1 = {10, 20};
struct Point p2 = p1;
printf(" p2.x = %d, p2.y = %d", p2.x, p2.y);
getchar();
return 0;
}
Program 2
#include <stdio.h>
struct Point {
int x;
int y;
};
int main()
{
struct Point p1 = {10, 20};
struct Point p2 = p1;
if (p1 == p2)
{
printf("p1 and p2 are same ");
}
getchar();
return 0;
}
Bit Fields in C
In C, we can specify size (in bits) of structure and union members.
The idea is to use memory efficiently when we know that the value of a field or group of fields will never exceed a limit or is withing a small range.
For example, consider the following declaration of date without the use of bit fields.
#include <stdio.h>
struct date {
unsigned int d;
unsigned int m;
unsigned int y;
};
int main()
{
printf("Size of date is %lu bytes\n",
sizeof(struct date));
struct date dt = { 31, 12, 2014 };
printf("Date is %d/%d/%d", dt.d, dt.m, dt.y);
}
Output:
Size of date is 12 bytes
Date is 31/12/2014
The above representation of ‘date’ takes 12 bytes on a compiler where an unsigned int takes 4 bytes.
Since we know that the value of d is always from 1 to 31, the value of m is from 1 to 12, we can optimize the space using bit fields.
#include <stdio.h>
struct date {
unsigned int d : 5;
unsigned int m : 4;
unsigned int y;
};
int main()
{
printf("Size of date is %lu bytes\n", sizeof(struct date));
struct date dt = { 31, 12, 2014 };
printf("Date is %d/%d/%d", dt.d, dt.m, dt.y);
return 0;
}
Output:
Size of date is 8 bytes
Date is 31/12/2014
However if the same code is written using signed int and the value of the fields goes beyond the bits allocated to the variable and something interesting can happen.
For example consider the same code but with signed integers:
#include <stdio.h>
struct date {
int d : 5;
int m : 4;
int y;
};
int main()
{
printf("Size of date is %lu bytes\n",
sizeof(struct date));
struct date dt = { 31, 12, 2014 };
printf("Date is %d/%d/%d", dt.d, dt.m, dt.y);
return 0;
}
Output:
Size of date is 8 bytes
Date is -1/-4/2014
The output comes out to be negative.
What happened behind is that the value 31 was stored in 5 bit signed integer which is equal to 11111.
The MSB is a 1, so it’s a negative number and you need to calculate the 2’s complement of the binary number to get its actual value which is what is done internally.
By calculating 2’s complement you will arrive at the value 00001 which is equivalent to decimal number 1 and since it was a negative number you get a -1.
A similar thing happens to 12 in which case you get 4-bit representation as 1100 which on calculating 2’s complement you get the value of -4.
Following are some interesting facts about bit fields in C.
1) A special unnamed bit field of size 0 is used to force alignment on next boundary.
For example consider the following program.
#include <stdio.h>
struct test1 {
unsigned int x : 5;
unsigned int y : 8;
};
struct test2 {
unsigned int x : 5;
unsigned int : 0;
unsigned int y : 8;
};
int main()
{
printf("Size of test1 is %lu bytes\n",
sizeof(struct test1));
printf("Size of test2 is %lu bytes\n",
sizeof(struct test2));
return 0;
}
Output:
Size of test1 is 4 bytes
Size of test2 is 8 bytes
2) We cannot have pointers to bit field members as they may not start at a byte boundary.
#include <stdio.h>
struct test {
unsigned int x : 5;
unsigned int y : 5;
unsigned int z;
};
int main()
{
struct test t;
printf("Address of t.x is %p", &t.x);
printf("Address of t.z is %p", &t.z);
return 0;
}
Output:
prog.c: In function 'main':
prog.c:14:1: error: cannot take address of bit-field 'x'
printf("Address of t.x is %p", &t.x);
^
3) It is implementation defined to assign an out-of-range value to a bit field member.
#include <stdio.h>
struct test {
unsigned int x : 2;
unsigned int y : 2;
unsigned int z : 2;
};
int main()
{
struct test t;
t.x = 5;
printf("%d", t.x);
return 0;
}
Output:
Implementation-Dependent
4) In C++, we can have static members in a structure/class, but bit fields cannot be static.
struct test1 {
static unsigned int x;
};
int main() {}
Output:
struct test1 {
static unsigned int x : 5;
};
int main() {}
Output:
prog.cpp:5:29: error: static member 'x' cannot be a bit-field
static unsigned int x : 5;
^
5) Array of bit fields is not allowed.
For example, the below program fails in the compilation.
struct test {
unsigned int x[10] : 5;
};
int main()
{
}
Output:
prog.c:3:1: error: bit-field 'x' has invalid type
unsigned int x[10]: 5;
^
Exercise:
Predict the output of following programs.
Assume that unsigned int takes 4 bytes and long int takes 8 bytes.
1)
#include <stdio.h>
struct test {
unsigned int x;
unsigned int y : 33;
unsigned int z;
};
int main()
{
printf("%lu", sizeof(struct test));
return 0;
}
2)
#include <stdio.h>
struct test {
unsigned int x;
long int y : 33;
unsigned int z;
};
int main()
{
struct test t;
unsigned int* ptr1 = &t.x;
unsigned int* ptr2 = &t.z;
printf("%d", ptr2 - ptr1);
return 0;
}
3)
union test {
unsigned int x : 3;
unsigned int y : 3;
int z;
};
int main()
{
union test t;
t.x = 5;
t.y = 4;
t.z = 1;
printf("t.x = %d, t.y = %d, t.z = %d",
t.x, t.y, t.z);
return 0;
}
4) Use bit fields in C to figure out a way whether a machine is little-endian or big-endian.
Structure Sorting (By Multiple Rules) in C++
Prerequisite :
Structures in C
Name and marks in different subjects (physics, chemistry and maths) are given for all students.
The task is to compute total marks and ranks of all students.
And finally display all students sorted by rank.
Rank of student is computed using below rules.
- If total marks are different, then students with higher marks gets better rank.
- If total marks are same, then students with higher marks in Maths gets better rank.
- If total marks are same and marks in Maths are also same, then students with better marks in Physics gets better rank.
- If all marks (total, Maths, Physics and Chemistry) are same, then any student can be assigned bedtter rank.
We use below structure to store details of students.
struct Student
{
string name; // Given
int math; // Marks in math (Given)
int phy; // Marks in Physics (Given)
int che; // Marks in Chemistry (Given)
int total; // Total marks (To be filled)
int rank; // Rank of student (To be filled)
};
We use
std::sort() for
Structure Sorting.
In Structure sorting, all the respective properties possessed by the structure object are sorted on the basis of one (or more) property of the object.
In this example, marks of students in different subjects are provided by user.
These marks in individual subjects are added to calculate the total marks of the student, which is then used to sort different students on the basis of their ranks (as explained above).
#include <bits/stdc++.h>
using namespace std;
struct Student
{
string name;
int math;
int phy;
int che;
int total;
int rank;
};
bool compareTwoStudents(Student a, Student b)
{
if (a.total != b.total )
return a.total > b.total;
if (a.math != b.math)
return a.math > b.math;
return (a.phy > b.phy);
}
void computeRanks(Student a[], int n)
{
for (int i=0; i<n; i++)
a[i].total = a[i].math + a[i].phy + a[i].che;
sort(a, a+5, compareTwoStudents);
for (int i=0; i<n; i++)
a[i].rank = i+1;
}
int main()
{
int n = 5;
Student a[n];
a[0].name = "Bryan" ;
a[0].math = 80 ;
a[0].phy = 95 ;
a[0].che = 85 ;
a[1].name= "Kevin" ;
a[1].math= 95 ;
a[1].phy= 85 ;
a[1].che= 99 ;
a[2].name = "Nick" ;
a[2].math = 95 ;
a[2].phy = 85 ;
a[2].che = 80 ;
a[3].name = "AJ" ;
a[3].math = 80 ;
a[3].phy = 70 ;
a[3].che = 90 ;
a[4].name = "Howie" ;
a[4].math = 80 ;
a[4].phy = 80 ;
a[4].che = 80 ;
computeRanks(a, n);
cout << "Rank" <<"t" << "Name" << "t";
cout << "Maths" <<"t" <<"Physics" <<"t"
<< "Chemistry";
cout << "t" << "Totaln";
for (int i=0; i<n; i++)
{
cout << a[i].rank << "t";
cout << a[i].name << "t";
cout << a[i].math << "t"
<< a[i].phy << "t"
<< a[i].che << "tt";
cout << a[i].total <<"t";
cout <<"n";
}
return 0;
}
Output:
Rank Name Maths Physics Chemistry Total
1 Kevin 95 85 99 279
2 Nick 95 85 80 260
3 Bryan 80 95 85 260
4 Howie 80 80 80 240
5 AJ 80 70 90 240
Related Articles:
sort() in C++ STL
Comparator function of qsort() in C
C qsort() vs C++ sort()
Sort an array according to count of set bits
Flexible Array Members in a structure in C
Flexible Array Member(FAM) is a feature introduced in the C99 standard of the C programming language.
- For the structures in C programming language from C99 standard onwards, we can declare an array without a dimension and whose size is flexible in nature.
- Such an array inside the structure should preferably be declared as the last member of structure and its size is variable(can be changed be at runtime).
- The structure must contain at least one more named member in addition to the flexible array member.
What must be the size of the structure below?
struct student
{
int stud_id;
int name_len;
int struct_size;
char stud_name[];
};
The size of structure is = 4 + 4 + 4 + 0 = 12
In the above code snippet, the size i.e length of array “stud_name” isn’t fixed and is an FAM.
The memory allocation using flexible array members(as per C99 standards) for the above example can be done as:
struct student *s = malloc( sizeof(*s) + sizeof(char [strlen(stud_name)]) );
Note: While using flexible array members in structures some convention regarding actual size of the member is defined.
In the above example the convention is that the member “stud_name” has character size.
For Example, Consider the following structure:
Input : id = 15, name = "Kartik"
Output : Student_id : 15
Stud_Name : Kartik
Name_Length: 6
Allocated_Struct_size: 18
Memory allocation of above structure:
struct student *s =
malloc( sizeof(*s) + sizeof(char [strlen("Kartik")]));
Its structure representation is equal to:
struct student
{
int stud_id;
int name_len;
int struct_size;
char stud_name[6];
};
Implementation
#include<string.h>
#include<stdio.h>
#include<stdlib.h>
struct student
{
int stud_id;
int name_len;
int struct_size;
char stud_name[];
};
struct student *createStudent(struct student *s,
int id, char a[])
{
s =
malloc( sizeof(*s) + sizeof(char) * strlen(a));
s->stud_id = id;
s->name_len = strlen(a);
strcpy(s->stud_name, a);
s->struct_size =
(sizeof(*s) + sizeof(char) * strlen(s->stud_name));
return s;
}
void printStudent(struct student *s)
{
printf("Student_id : %d\n"
"Stud_Name : %s\n"
"Name_Length: %d\n"
"Allocated_Struct_size: %d\n\n",
s->stud_id, s->stud_name, s->name_len,
s->struct_size);
}
int main()
{
struct student *s1 = createStudent(s1, 523, "Cherry");
struct student *s2 = createStudent(s2, 535, "Sanjayulsha");
printStudent(s1);
printStudent(s2);
printf("Size of Struct student: %lu\n",
sizeof(struct student));
printf("Size of Struct pointer: %lu",
sizeof(s1));
return 0;
}
Output:
Student_id : 523
Stud_Name : SanjayKanna
Name_Length: 11
Allocated_Struct_size: 23
Student_id : 535
Stud_Name : Cherry
Name_Length: 6
Allocated_Struct_size: 18
Size of Struct student: 12
Size of Struct pointer: 8
Important Points:
- Adjacent memory locations are used to store structure members in memory.
- In previous standards of the C programming language, we were able to declare a zero size array member in place of a flexible array member.
The GCC compiler with C89 standard considers it as zero size array.
Difference between Structure and Union in C
structures in C
A structure is a user-defined data type available in C that allows to combining data items of different kinds.
Structures are used to represent a record.
Defining a structure: To define a structure, you must use the struct statement.
The struct statement defines a new data type, with more than or equal to one member.
The format of the struct statement is as follows:
struct [structure name]
{
member definition;
member definition;
...
member definition;
};
union
A union is a special data type available in C that allows storing different data types in the same memory location.
You can define a union with many members, but only one member can contain a value at any given time.
Unions provide an efficient way of using the same memory location for multiple purposes.
Defining a Union: To define a union, you must use the union statement in the same way as you did while defining a structure.
The union statement defines a new data type with more than one member for your program.
The format of the union statement is as follows:
union [union name]
{
member definition;
member definition;
...
member definition;
};
Similarities between Structure and Union
- Both are user-defined data types used to store data of different types as a single unit.
- Their members can be objects of any type, including other structures and unions or arrays.
A member can also consist of a bit field.
- Both structures and unions support only assignment = and sizeof operators.
The two structures or unions in the assignment must have the same members and member types.
- A structure or a union can be passed by value to functions and returned by value by functions.
The argument must have the same type as the function parameter.
A structure or union is passed by value just like a scalar variable as a corresponding parameter.
- ‘.’ operator is used for accessing members.
Differences
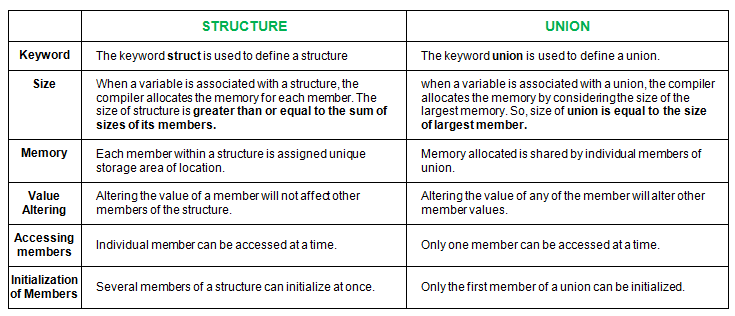
#include <stdio.h>
#include <string.h>
struct struct_example
{
int integer;
float decimal;
char name[20];
};
union union_example
{
int integer;
float decimal;
char name[20];
};
void main()
{
struct struct_example s={18,38,"geeksforgeeks"};
union union_example u={18,38,"geeksforgeeks"};
printf("structure data:\n integer: %d\n"
"decimal: %.2f\n name: %s\n",
s.integer, s.decimal, s.name);
printf("\nunion data:\n integeer: %d\n"
"decimal: %.2f\n name: %s\n",
u.integer, u.decimal, u.name);
printf("\nsizeof structure : %d\n", sizeof(s));
printf("sizeof union : %d\n", sizeof(u));
printf("\n Accessing all members at a time:");
s.integer = 183;
s.decimal = 90;
strcpy(s.name, "geeksforgeeks");
printf("structure data:\n integer: %d\n "
"decimal: %.2f\n name: %s\n",
s.integer, s.decimal, s.name);
u.integer = 183;
u.decimal = 90;
strcpy(u.name, "geeksforgeeks");
printf("\nunion data:\n integeer: %d\n "
"decimal: %.2f\n name: %s\n",
u.integer, u.decimal, u.name);
printf("\n Accessing one member at time:");
printf("\nstructure data:");
s.integer = 240;
printf("\ninteger: %d", s.integer);
s.decimal = 120;
printf("\ndecimal: %f", s.decimal);
strcpy(s.name, "C programming");
printf("\nname: %s\n", s.name);
printf("\n union data:");
u.integer = 240;
printf("\ninteger: %d", u.integer);
u.decimal = 120;
printf("\ndecimal: %f", u.decimal);
strcpy(u.name, "C programming");
printf("\nname: %s\n", u.name);
printf("\nAltering a member value:\n");
s.integer = 1218;
printf("structure data:\n integer: %d\n "
" decimal: %.2f\n name: %s\n",
s.integer, s.decimal, s.name);
u.integer = 1218;
printf("union data:\n integer: %d\n"
" decimal: %.2f\n name: %s\n",
u.integer, u.decimal, u.name);
}
Output:
structure data:
integer: 18
decimal: 38.00
name: geeksforgeeks
union data:
integeer: 18
decimal: 0.00
name: ?
sizeof structure: 28
sizeof union: 20
Accessing all members at a time: structure data:
integer: 183
decimal: 90.00
name: geeksforgeeks
union data:
integeer: 1801807207
decimal: 277322871721159510000000000.00
name: geeksforgeeks
Accessing one member at a time:
structure data:
integer: 240
decimal: 120.000000
name: C programming
union data:
integer: 240
decimal: 120.000000
name: C programming
Altering a member value:
structure data:
integer: 1218
decimal: 120.00
name: C programming
union data:
integer: 1218
decimal: 0.00
name: ?
In my opinion, structure is better because as memory is shared in union ambiguity is more.
Difference between C structures and C++ structures
In C++, struct and class are exactly the same things, except for that struct defaults to public visibility and class defaults to private visibility.
Some important differences between the C and C++ structures:
- Member functions inside structure: Structures in C cannot have member functions inside structure but Structures in C++ can have member functions along with data members.
- Direct Initialization: We cannot directly initialize structure data members in C but we can do it in C++.
C
#include <stdio.h>
struct Record {
int x = 7;
};
int main()
{
struct Record s;
printf("%d", s.x);
return 0;
}
C++
#include <iostream>
using namespace std;
struct Record {
int x = 7;
};
int main()
{
Record s;
cout << s.x << endl;
return 0;
}
Output:
7
- Using struct keyword: In C, we need to use struct to declare a struct variable.
In C++, struct is not necessary.
For example, let there be a structure for Record.
In C, we must use “struct Record” for Record variables.
In C++, we need not use struct and using ‘Record‘ only would work.
- Static Members: C structures cannot have static members but is allowed in C++.
C
struct Record {
static int x;
};
int main()
{
return 0;
}
C++
struct Record {
static int x;
};
int main()
{
return 0;
}
This will generate an error in C but no error in C++.
- Constructor creation in structure: Structures in C cannot have constructor inside structure but Structures in C++ can have Constructor creation.
C
#include <stdio.h>
struct Student {
int roll;
Student(int x)
{
roll = x;
}
};
int main()
{
struct Student s(2);
printf("%d", s.x);
return 0;
}
C++
#include <iostream>
using namespace std;
struct Student {
int roll;
Student(int x)
{
roll = x;
}
};
int main()
{
struct Student s(2);
cout << s.roll;
return 0;
}
Output:
2
- sizeof operator: This operator will generate 0 for an empty structure in C whereas 1 for an empty structure in C++.
#include <stdio.h>
struct Record {
};
int main()
{
struct Record s;
printf("%d\n", sizeof(s));
return 0;
}
Output in C:
0
Output in C++:
1
- Data Hiding: C structures do not allow concept of Data hiding but is permitted in C++ as C++ is an object oriented language whereas C is not.
- Access Modifiers: C structures do not have access modifiers as these modifiers are not supported by the language.
C++ structures can have this concept as it is inbuilt in the language.
Related Article: Structure vs Class in C++
Anonymous Union and Structure in C
In
C11 standard of C, anonymous Unions and structures were added.
Anonymous unions/structures are also known as unnamed unions/structures as they don’t have names.
Since there is no names, direct objects(or variables) of them are not created and we use them in nested structure or unions.
Definition is just like that of a normal union just without a name or tag.
For example,
// Anonymous union example
union
{
char alpha;
int num;
};
// Anonymous structure example
struct
{
char alpha;
int num;
};
Since there is no variable and no name, we can directly access members.
This accessibility works only inside the scope where the anonymous union is defined.
Following is a complete working example of anonymous union.
#include<stdio.h>
struct Scope
{
union
{
char alpha;
int num;
};
};
int main()
{
struct Scope x;
x.num = 65;
printf("x.alpha = %c, x.num = %d", x.alpha, x.num);
return 0;
}
Output:
x.alpha = A, x.num = 65
#include<stdio.h>
struct Scope
{
struct
{
char alpha;
int num;
};
};
int main()
{
struct Scope x;
x.num = 65;
x.alpha = 'B';
printf("x.alpha = %c, x.num = %d", x.alpha, x.num);
return 0;
}
Output:
x.alpha = B, x.num = 65
What about C++?
Anonymous Unions and Structures are NOT part of C++ 11 standard, but most of the C++ compilers support them.
Since this is a C only feature, the C++ implementations don’t allow to anonymous struct/union to have private or protected members, static members, and functions.
Compound Literals in C
Consider below program in C.
#include <stdio.h>
int main()
{
int *p = (int []){2, 4, 6};
printf("%d %d %d", p[0], p[1], p[2]);
return 0;
}
Output:
2 4 6
The above example is an example of compound literals.
Compound literals were introduced in
C99 standard of C.
Compound literals feature allows us to create unnamed objects with given list of initialized values.
In the above example, an array is created without any name.
Address of first element of array is assigned to pointer p.
What is the use of it?
Compound literals are mainly used with structures and are particularly useful when passing structures variables to functions.
We can pass a structure object without defining it
For example, consider the below code.
#include <stdio.h>
struct Point
{
int x, y;
};
void printPoint(struct Point p)
{
printf("%d, %d", p.x, p.y);
}
int main()
{
printPoint((struct Point){2, 3});
return 0;
}
Output:
2, 3
Memory Layout of C Programs
A typical memory representation of C program consists of following sections.
1.
Text segment
2.
Initialized data segment
3.
Uninitialized data segment
4.
Stack
5.
Heap

A typical memory layout of a running process
1.
Text Segment:
A text segment , also known as a code segment or simply as text, is one of the sections of a program in an object file or in memory, which contains executable instructions.
As a memory region, a text segment may be placed below the heap or stack in order to prevent heaps and stack overflows from overwriting it.
Usually, the text segment is sharable so that only a single copy needs to be in memory for frequently executed programs, such as text editors, the C compiler, the shells, and so on.
Also, the text segment is often read-only, to prevent a program from accidentally modifying its instructions.
2.
Initialized Data Segment:
Initialized data segment, usually called simply the Data Segment.
A data segment is a portion of virtual address space of a program, which contains the global variables and static variables that are initialized by the programmer.
Note that, data segment is not read-only, since the values of the variables can be altered at run time.
This segment can be further classified into initialized read-only area and initialized read-write area.
For instance the global string defined by char s[] = “hello world” in C and a C statement like int debug=1 outside the main (i.e.
global) would be stored in initialized read-write area.
And a global C statement like const char* string = “hello world” makes the string literal “hello world” to be stored in initialized read-only area and the character pointer variable string in initialized read-write area.
Ex: static int i = 10 will be stored in data segment and global int i = 10 will also be stored in data segment
3.
Uninitialized Data Segment:
Uninitialized data segment, often called the “bss” segment, named after an ancient assembler operator that stood for “block started by symbol.” Data in this segment is initialized by the kernel to arithmetic 0 before the program starts executing
uninitialized data starts at the end of the data segment and contains all global variables and static variables that are initialized to zero or do not have explicit initialization in source code.
For instance a variable declared static int i; would be contained in the BSS segment.
For instance a global variable declared int j; would be contained in the BSS segment.
4.
Stack:
The stack area traditionally adjoined the heap area and grew the opposite direction; when the stack pointer met the heap pointer, free memory was exhausted.
(With modern large address spaces and virtual memory techniques they may be placed almost anywhere, but they still typically grow opposite directions.)
The stack area contains the program stack, a LIFO structure, typically located in the higher parts of memory.
On the standard PC x86 computer architecture it grows toward address zero; on some other architectures it grows the opposite direction.
A “stack pointer” register tracks the top of the stack; it is adjusted each time a value is “pushed” onto the stack.
The set of values pushed for one function call is termed a “stack frame”; A stack frame consists at minimum of a return address.
Stack, where automatic variables are stored, along with information that is saved each time a function is called.
Each time a function is called, the address of where to return to and certain information about the caller’s environment, such as some of the machine registers, are saved on the stack.
The newly called function then allocates room on the stack for its automatic and temporary variables.
This is how recursive functions in C can work.
Each time a recursive function calls itself, a new stack frame is used, so one set of variables doesn’t interfere with the variables from another instance of the function.
5.
Heap:
Heap is the segment where dynamic memory allocation usually takes place.
The heap area begins at the end of the BSS segment and grows to larger addresses from there.The Heap area is managed by malloc, realloc, and free, which may use the brk and sbrk system calls to adjust its size (note that the use of brk/sbrk and a single “heap area” is not required to fulfill the contract of malloc/realloc/free; they may also be implemented using mmap to reserve potentially non-contiguous regions of virtual memory into the process’ virtual address space).
The Heap area is shared by all shared libraries and dynamically loaded modules in a process.
Examples.
The size(1) command reports the sizes (in bytes) of the text, data, and bss segments.
( for more details please refer man page of size(1) )
1.
Check the following simple C program
#include <stdio.h>
int main(void)
{
return 0;
}
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
text data bss dec hex filename
960 248 8 1216 4c0 memory-layout
2.
Let us add one global variable in program, now check the size of bss (highlighted in red color).
#include <stdio.h>
int global;
int main(void)
{
return 0;
}
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
text data bss dec hex filename
960 248 12 1220 4c4 memory-layout
3.
Let us add one static variable which is also stored in bss.
#include <stdio.h>
int global;
int main(void)
{
static int i;
return 0;
}
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
text data bss dec hex filename
960 248 16 1224 4c8 memory-layout
4.
Let us initialize the static variable which will then be stored in Data Segment (DS)
#include <stdio.h>
int global;
int main(void)
{
static int i = 100;
return 0;
}
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
text data bss dec hex filename
960 252 12 1224 4c8 memory-layout
5.
Let us initialize the global variable which will then be stored in Data Segment (DS)
#include <stdio.h>
int global = 10;
int main(void)
{
static int i = 100;
return 0;
}
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
text data bss dec hex filename
960 256 8 1224 4c8 memory-layout
How to deallocate memory without using free() in C?
Question: How to deallocate dynamically allocate memory without using “free()” function.
Solution: Standard library function
realloc() can be used to deallocate previously allocated memory.
Below is function declaration of “realloc()” from “stdlib.h”
void *realloc(void *ptr, size_t size);
If “size” is zero, then call to realloc is equivalent to “free(ptr)”.
And if “ptr” is NULL and size is non-zero then call to realloc is equivalent to “malloc(size)”.
Let us check with simple example.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int *ptr = (int*)malloc(10);
return 0;
}
Check the leak summary with valgrind tool.
It shows memory leak of 10 bytes, which is highlighed in red colour.
[narendra@ubuntu]$ valgrind –leak-check=full ./free
==1238== LEAK SUMMARY:
==1238== definitely lost: 10 bytes in 1 blocks.
==1238== possibly lost: 0 bytes in 0 blocks.
==1238== still reachable: 0 bytes in 0 blocks.
==1238== suppressed: 0 bytes in 0 blocks.
[narendra@ubuntu]$
Let us modify the above code.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int *ptr = (int*) malloc(10);
realloc(ptr, 0);
return 0;
}
Check the valgrind’s output.
It shows no memory leaks are possible, highlighted in red color.
[narendra@ubuntu]$ valgrind –leak-check=full ./a.out
==1435== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 11 from 1)
==1435== malloc/free: in use at exit: 0 bytes in 0 blocks.
==1435== malloc/free: 1 allocs, 1 frees, 10 bytes allocated.
==1435== For counts of detected errors, rerun with: -v
==1435== All heap blocks were freed — no leaks are possible.
[narendra@ubuntu]$
Difference Between malloc() and calloc() with Examples
Pre-requisite: Dynamic Memory Allocation in C using malloc(), calloc(), free() and realloc()
The name
malloc and
calloc() are library functions that allocate memory dynamically.
It means that memory is allocated during runtime(execution of the program) from the heap segment.
- Initialization: malloc() allocates memory block of given size (in bytes) and returns a pointer to the beginning of the block.
malloc() doesn’t initialize the allocated memory.
If we try to access the content of memory block(before initializing) then we’ll get segmentation fault error(or maybe garbage values).
void* malloc(size_t size);
calloc() allocates the memory and also initializes the allocated memory block to zero.
If we try to access the content of these blocks then we’ll get 0.
void* calloc(size_t num, size_t size);
- Number of arguments: Unlike malloc(), calloc() takes two arguments:
1) Number of blocks to be allocated.
2) Size of each block.
-
Return Value: After successful allocation in malloc() and calloc(), a pointer to the block of memory is returned otherwise NULL value is returned which indicates the failure of allocation.
For instance, If we want to allocate memory for array of 5 integers, see the following program:-
#include <stdio.h>
#include <stdlib.h>
int main()
{
int* arr;
arr = (int*)malloc(5 * sizeof(int));
free(arr);
arr = (int*)calloc(5, sizeof(int));
free(arr);
return (0);
}
We can achieve same functionality as calloc() by using malloc() followed by memset(),
ptr = malloc(size);
memset(ptr, 0, size);
Note: It would be better to use malloc over calloc, unless we want the zero-initialization because malloc is faster than calloc.
So if we just want to copy some stuff or do something that doesn’t require filling of the blocks with zeros, then malloc would be a better choice.
How does free() know the size of memory to be deallocated?
Consider the following prototype of free() function which is used to free memory allocated using malloc() or calloc() or realloc().
void free(void *ptr);
Note that the free function does not accept size as a parameter.
How does free() function know how much memory to free given just a pointer?
Following is the most common way to store size of memory so that free() knows the size of memory to be deallocated.
When memory allocation is done, the actual heap space allocated is one word larger than the requested memory.
The extra word is used to store the size of the allocation and is later used by free( )
Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
Use of realloc()
Size of dynamically allocated memory can be changed by using realloc().
As per the C99 standard:
void *realloc(void *ptr, size_t size);
realloc deallocates the old object pointed to by ptr and returns a pointer to a new object that has the size specified by size.
The contents of the new object is identical to that of the old object prior to deallocation, up to the lesser of the new and old sizes.
Any bytes in the new object beyond the size of the old object have indeterminate values.
The point to note is that realloc() should only be used for dynamically allocated memory.
If the memory is not dynamically allocated, then behavior is undefined.
For example, program 1 demonstrates incorrect use of realloc() and program 2 demonstrates correct use of realloc().
Program 1:
#include <stdio.h>
#include <stdlib.h>
int main()
{
int arr[2], i;
int *ptr = arr;
int *ptr_new;
arr[0] = 10;
arr[1] = 20;
ptr_new = (int *)realloc(ptr, sizeof(int)*3);
*(ptr_new + 2) = 30;
for(i = 0; i < 3; i++)
printf("%d ", *(ptr_new + i));
getchar();
return 0;
}
Output:
Undefined Behavior
Program 2:
#include <stdio.h>
#include <stdlib.h>
int main()
{
int *ptr = (int *)malloc(sizeof(int)*2);
int i;
int *ptr_new;
*ptr = 10;
*(ptr + 1) = 20;
ptr_new = (int *)realloc(ptr, sizeof(int)*3);
*(ptr_new + 2) = 30;
for(i = 0; i < 3; i++)
printf("%d ", *(ptr_new + i));
getchar();
return 0;
}
Output:
10 20 30
What is Memory Leak? How can we avoid?
Memory leak occurs when programmers create a memory in heap and forget to delete it.
Memory leaks are particularly serious issues for programs like daemons and servers which by definition never terminate.
#include <stdlib.h>
void f()
{
int *ptr = (int *) malloc(sizeof(int));
return;
}
To avoid memory leaks, memory allocated on heap should always be freed when no longer needed.
#include <stdlib.h>;
void f()
{
int *ptr = (int *) malloc(sizeof(int));
free(ptr);
return;
}
fseek() vs rewind() in C
In C, fseek() should be preferred over rewind().
Note the following text C99 standard:
The rewind function sets the file position indicator for the stream pointed to by stream to the beginning of the file.
It is equivalent to
(void)fseek(stream, 0L, SEEK_SET)
except that the error indicator for the stream is also cleared.
This following code example sets the file position indicator of an input stream back to the beginning using rewind().
But there is no way to check whether the rewind() was successful.
int main()
{
FILE *fp = fopen("test.txt", "r");
if ( fp == NULL ) {
}
rewind(fp);
return 0;
}
In the above code, fseek() can be used instead of rewind() to see if the operation succeeded.
Following lines of code can be used in place of rewind(fp);
if ( fseek(fp, 0L, SEEK_SET) != 0 ) {
}
Source:
https://www.securecoding.cert.org/confluence/display/seccode/FIO07-C.+Prefer+fseek%28%29+to+rewind%28%29
EOF, getc() and feof() in C
In C/C++, getc() returns EOF when end of file is reached.
getc() also returns EOF when it fails.
So, only comparing the value returned by getc() with EOF is not sufficient to check for actual end of file.
To solve this problem, C provides feof() which returns non-zero value only if end of file has reached, otherwise it returns 0.
For example, consider the following C program to print contents of file test.txt on screen.
In the program, returned value of getc() is compared with EOF first, then there is another check using feof().
By putting this check, we make sure that the program prints “End of file reached” only if end of file is reached.
And if getc() returns EOF due to any other reason, then the program prints “Something went wrong”
#include <stdio.h>
int main()
{
FILE *fp = fopen("test.txt", "r");
int ch = getc(fp);
while (ch != EOF)
{
putchar(ch);
ch = getc(fp);
}
if (feof(fp))
printf("\n End of file reached.");
else
printf("\n Something went wrong.");
fclose(fp);
getchar();
return 0;
}
fopen() for an existing file in write mode
In C, fopen() is used to open a file in different modes.
To open a file in write mode, “w” is specified.
When mode “w” is specified, it creates an empty file for output operations.
What if the file already exists?
If a file with the same name already exists, its contents are discarded and the file is treated as a new empty file.
For example, in the following program, if “test.txt” already exists, its contents are removed and “GeeksforGeeks” is written to it.
#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE *fp = fopen("test.txt", "w");
if (fp == NULL)
{
puts("Couldn't open file");
exit(0);
}
else
{
fputs("GeeksforGeeks", fp);
puts("Done");
fclose(fp);
}
return 0;
}
The above behavior may lead to unexpected results.
If programmer’s intention was to create a new file and a file with same name already exists, the existing file’s contents are overwritten.
The latest C standard C11 provides a new mode “x” which is exclusive create-and-open mode.
Mode “x” can be used with any “w” specifier, like “wx”, “wbx”.
When x is used with w, fopen() returns NULL if file already exists or could not open. Following is modified C11 program that doesn’t overwrite an existing file.
#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE *fp = fopen("test.txt", "wx");
if (fp == NULL)
{
puts("Couldn't open file or file already exists");
exit(0);
}
else
{
fputs("GeeksforGeeks", fp);
puts("Done");
fclose(fp);
}
return 0;
}
Read/Write structure to a file in C
Prerequisite: Structure in C
For writing in file, it is easy to write string or int to file using fprintf and putc, but you might have faced difficulty when writing contents of struct.
fwrite and fread make task easier when you want to write and read blocks of data.
- fwrite : Following is the declaration of fwrite function
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream)
ptr - This is pointer to array of elements to be written
size - This is the size in bytes of each element to be written
nmemb - This is the number of elements, each one with a size of size bytes
stream - This is the pointer to a FILE object that specifies an output stream
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct person
{
int id;
char fname[20];
char lname[20];
};
int main ()
{
FILE *outfile;
outfile = fopen ("person.dat", "w");
if (outfile == NULL)
{
fprintf(stderr, "\nError opend file\n");
exit (1);
}
struct person input1 = {1, "rohan", "sharma"};
struct person input2 = {2, "mahendra", "dhoni"};
fwrite (&input1, sizeof(struct person), 1, outfile);
fwrite (&input2, sizeof(struct person), 1, outfile);
if(fwrite != 0)
printf("contents to file written successfully !\n");
else
printf("error writing file !\n");
fclose (outfile);
return 0;
}
Output:
gcc demowrite.c
./a.out
contents to file written successfully!
- fread : Following is the declaration of fread function
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream)
ptr - This is the pointer to a block of memory with a minimum size of size*nmemb bytes.
size - This is the size in bytes of each element to be read.
nmemb - This is the number of elements, each one with a size of size bytes.
stream - This is the pointer to a FILE object that specifies an input stream.
#include <stdio.h>
#include <stdlib.h>
struct person
{
int id;
char fname[20];
char lname[20];
};
int main ()
{
FILE *infile;
struct person input;
infile = fopen ("person.dat", "r");
if (infile == NULL)
{
fprintf(stderr, "\nError opening file\n");
exit (1);
}
while(fread(&input, sizeof(struct person), 1, infile))
printf ("id = %d name = %s %s\n", input.id,
input.fname, input.lname);
fclose (infile);
return 0;
}
Output:
gcc demoread.c
./a.out
id = 1 name = rohan sharma
id = 2 name = mahendra dhoni
fgets() and gets() in C language
For reading a string value with spaces, we can use either gets() or fgets() in C programming language.
Here, we will see what is the difference between gets() and fgets().
fgets()
It reads a line from the specified stream and stores it into the string pointed to by str.
It stops when either (n-1) characters are read, the newline character is read, or the end-of-file is reached, whichever comes first.
Syntax :
char *fgets(char *str, int n, FILE *stream)
str : Pointer to an array of chars where the string read is copied.
n : Maximum number of characters to be copied into str
(including the terminating null-character).
*stream : Pointer to a FILE object that identifies an input stream.
stdin can be used as argument to read from the standard input.
returns : the function returns str
- It follow some parameter such as Maximum length, buffer, input device reference.
- It is safe to use because it checks the array bound.
- It keep on reading until new line character encountered or maximum limit of character array.
Example : Let’s say the maximum number of characters are 15 and input length is greater than 15 but still fgets() will read only 15 character and print it.
#include <stdio.h>
#define MAX 15
int main()
{
char buf[MAX];
fgets(buf, MAX, stdin);
printf("string is: %s\n", buf);
return 0;
}
Since fgets() reads input from user, we need to provide input during runtime.
Input:
Hello and welcome to GeeksforGeeks
Output:
Hello and welc
gets()
Reads characters from the standard input (stdin) and stores them as a C string into str until a newline character or the end-of-file is reached.
Syntax:
char * gets ( char * str );
str :Pointer to a block of memory (array of char)
where the string read is copied as a C string.
returns : the function returns str
- It is not safe to use because it does not check the array bound.
- It is used to read string from user until newline character not encountered.
Example : Suppose we have a character array of 15 characters and input is greater than 15 characters, gets() will read all these characters and store them into variable.Since, gets() do not check the maximum limit of input characters, so at any time compiler may return buffer overflow error.
#include <stdio.h>
#define MAX 15
int main()
{
char buf[MAX];
printf("Enter a string: ");
gets(buf);
printf("string is: %s\n", buf);
return 0;
}
Since gets() reads input from user, we need to provide input during runtime.
Input:
Hello and welcome to GeeksforGeeks
Output:
Hello and welcome to GeeksforGeeks
Basics of File Handling in C
So far the operations using C program are done on a prompt / terminal which is not stored anywhere.
But in the software industry, most of the programs are written to store the information fetched from the program.
One such way is to store the fetched information in a file.
Different operations that can be performed on a file are:
- Creation of a new file (fopen with attributes as “a” or “a+” or “w” or “w++”)
- Opening an existing file (fopen)
- Reading from file (fscanf or fgetc)
- Writing to a file (fprintf or fputs)
- Moving to a specific location in a file (fseek, rewind)
- Closing a file (fclose)
The text in the brackets denotes the functions used for performing those operations.
Functions in File Operations:
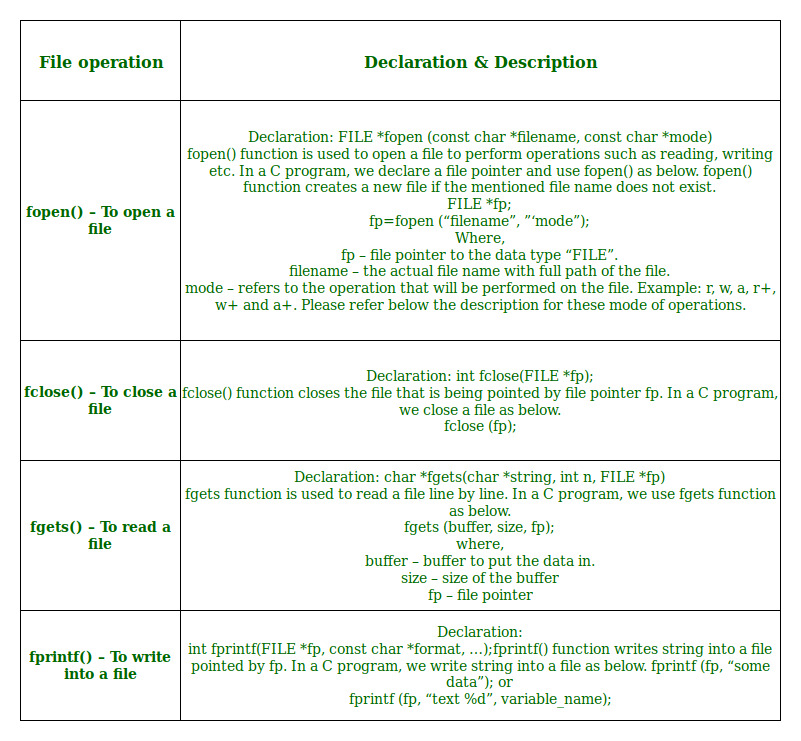 Opening or creating file
Opening or creating file
For opening a file, fopen function is used with the required access modes.
Some of the commonly used file access modes are mentioned below.
File opening modes in C:
- “r” – Searches file.
If the file is opened successfully fopen( ) loads it into memory and sets up a pointer which points to the first character in it.
If the file cannot be opened fopen( ) returns NULL.
- “w” – Searches file.
If the file exists, its contents are overwritten.
If the file doesn’t exist, a new file is created.
Returns NULL, if unable to open file.
- “a” – Searches file.
If the file is opened successfully fopen( ) loads it into memory and sets up a pointer that points to the last character in it.
If the file doesn’t exist, a new file is created.
Returns NULL, if unable to open file.
- “r+” – Searches file.
If is opened successfully fopen( ) loads it into memory and sets up a pointer which points to the first character in it.
Returns NULL, if unable to open the file.
- “w+” – Searches file.
If the file exists, its contents are overwritten.
If the file doesn’t exist a new file is created.
Returns NULL, if unable to open file.
- “a+” – Searches file.
If the file is opened successfully fopen( ) loads it into memory and sets up a pointer which points to the last character in it.
If the file doesn’t exist, a new file is created.
Returns NULL, if unable to open file.
As given above, if you want to perform operations on a binary file, then you have to append ‘b’ at the last.
For example, instead of “w”, you have to use “wb”, instead of “a+” you have to use “a+b”.
For performing the operations on the file, a special pointer called File pointer is used which is declared as
FILE *filePointer;
So, the file can be opened as
filePointer = fopen(“fileName.txt”, “w”)
The second parameter can be changed to contain all the attributes listed in the above table.
- Reading from a file –
The file read operations can be performed using functions fscanf or fgets.
Both the functions performed the same operations as that of scanf and gets but with an additional parameter, the file pointer.
So, it depends on you if you want to read the file line by line or character by character.
And the code snippet for reading a file is as:
FILE * filePointer;
filePointer = fopen(“fileName.txt”, “r”);
fscanf(filePointer, "%s %s %s %d", str1, str2, str3, &year);
- Writing a file –:
The file write operations can be perfomed by the functions fprintf and fputs with similarities to read operations.
The snippet for writing to a file is as :
FILE *filePointer ;
filePointer = fopen(“fileName.txt”, “w”);
fprintf(filePointer, "%s %s %s %d", "We", "are", "in", 2012);
- Closing a file –:
After every successful fie operations, you must always close a file.
For closing a file, you have to use fclose function.
The snippet for closing a file is given as :
FILE *filePointer ;
filePointer= fopen(“fileName.txt”, “w”);
---------- Some file Operations -------
fclose(filePointer)
Example 1: Program to Open a File, Write in it, And Close the File
# include <stdio.h>
# include <string.h>
int main( )
{
FILE *filePointer ;
char dataToBeWritten[50]
= "GeeksforGeeks-A Computer Science Portal for Geeks";
filePointer = fopen("GfgTest.c", "w") ;
if ( filePointer == NULL )
{
printf( "GfgTest.c file failed to open." ) ;
}
else
{
printf("The file is now opened.\n") ;
if ( strlen ( dataToBeWritten ) > 0 )
{
fputs(dataToBeWritten, filePointer) ;
fputs("\n", filePointer) ;
}
fclose(filePointer) ;
printf("Data successfully written in file GfgTest.c\n");
printf("The file is now closed.") ;
}
return 0;
}
Example 2: Program to Open a File, Read from it, And Close the File
# include <stdio.h>
# include <string.h>
int main( )
{
FILE *filePointer ;
char dataToBeRead[50];
filePointer = fopen("GfgTest.c", "r") ;
if ( filePointer == NULL )
{
printf( "GfgTest.c file failed to open." ) ;
}
else
{
printf("The file is now opened.\n") ;
while( fgets ( dataToBeRead, 50, filePointer ) != NULL )
{
printf( "%s" , dataToBeRead ) ;
}
fclose(filePointer) ;
printf("Data successfully read from file GfgTest.c\n");
printf("The file is now closed.") ;
}
return 0;
}
fsetpos() (Set File Position) in C
The fsetpos() function moves the file position indicator to the location specified by the object pointed to by position.
When fsetpos() is executed ,the end-of-file indecator is reset.
Declaration
int fsetpos(FILE *stream, const fpos_t *position)
Parameters –
- stream – This is the pointer to a FILE object that identifies the stream.
- position – This is the pointer to a fpos_t object containing a position previously obtained with fgetpos.
Return – If it successful, it return
zero otherwise returns nonzero value.
#include <stdio.h>
int main () {
FILE *fp;
fpos_t position;
fp = fopen("myfile.txt","w+");
fgetpos(fp, &position);
fputs("HelloWorld!", fp);
fsetpos(fp, &position);
fputs("geeksforgeeks", fp);
fclose(fp);
return(0);
}
Output –
geeksforgeeks
rename function in C/C++
rename() function is used to change the name of the file or directory i.e.
from
old_name to
new_name without changing the content present in the file.
This function takes name of the file as its argument.
If
new_name is the name of an existing file in the same folder then the function may either fail or override the existing file, depending on the specific system and library implementation.
Syntax:
int rename (const char *old_name, const char *new_name);
Parameters:
old_name : Name of an existing file to be renamed.
new_name : String containing new name of the file.
Return:
Return type of function is an integer.
If the file is renamed successfully, zero is returned.
On failure, a nonzero value is returned.
Assume that we have a text file having name
geeks.txt, having some content.
So, we are going to rename this file, using the below C program present in the same folder where this file is present.
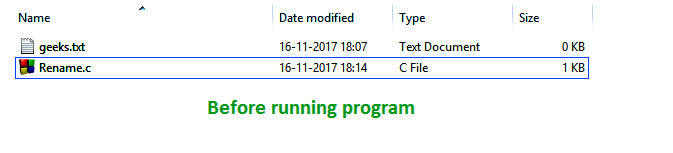
#include<stdio.h>
int main()
{
char old_name[] = "geeks.txt";
char new_name[] = "geeksforgeeks.txt";
int value;
value = rename(old_name, new_name);
if(!value)
{
printf("%s", "File name changed successfully");
}
else
{
perror("Error");
}
return 0;
}
Output:
If file name changed
File name changed successfully
OR
If file name not changed
Error: No such file or directory
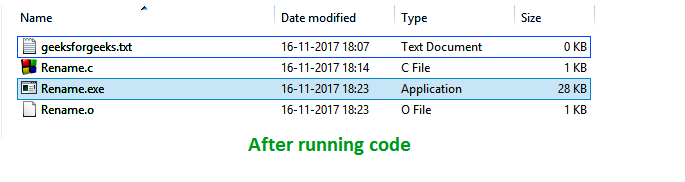
tmpfile() function in C
In
C Programming Language, the tmpfile() function is used to produce/create a temporary file.
- tmpfile() function is defined in the “stdio.h” header file.
- The created temporary file will automatically be deleted after the termination of program.
- It opens file in binary update mode i.e., wb+ mode.
- The syntax of tmpfile() function is:
FILE *tmpfile(void)
- The tmpfile() function always returns a pointer after the creation of file to the temporary file.
If by chance temporary file can not be created, then the tmpfile() function returns NULL pointer.
#include <stdio.h>
int main()
{
char str[] = "Hello GeeksforGeeks";
int i = 0;
FILE* tmp = tmpfile();
if (tmp == NULL)
{
puts("Unable to create temp file");
return 0;
}
puts("Temporary file is created\n");
while (str[i] != '\0')
{
fputc(str[i], tmp);
i++;
}
rewind(tmp);
while (!feof(tmp))
putchar(fgetc(tmp));
}
Output:
Temporary file is created
Hello GeeksforGeeks
fgetc() and fputc() in C
fgetc()
fgetc() is used to obtain input from a file single character at a time.
This function returns the number of characters read by the function.
It returns the character present at position indicated by file pointer.
After reading the character, the file pointer is advanced to next character.
If pointer is at end of file or if an error occurs EOF file is returned by this function.
Syntax:
int fgetc(FILE *pointer)
pointer: pointer to a FILE object that identifies
the stream on which the operation is to be performed.
#include <stdio.h>
int main ()
{
FILE *fp = fopen("test.txt","r");
if (fp == NULL)
return 0;
do
{
char c = fgetc(fp);
if (feof(fp))
break ;
printf("%c", c);
} while(1);
fclose(fp);
return(0);
}
Output:
The entire content of file is printed character by
character till end of file.
It reads newline character
as well.
Using fputc()
fputc() is used to write a single character at a time to a given file.
It writes the given character at the position denoted by the file pointer and then advances the file pointer.
This function returns the character that is written in case of successful write operation else in case of error EOF is returned.
Syntax:
int fputc(int char, FILE *pointer)
char: character to be written.
This is passed as its int promotion.
pointer: pointer to a FILE object that identifies the
stream where the character is to be written.
#include<stdio.h>
int main()
{
int i = 0;
FILE *fp = fopen("output.txt","w");
if (fp == NULL)
return 0;
char string[] = "good bye", received_string[20];
for (i = 0; string[i]!='\0'; i++)
fputc(string[i], fp);
fclose(fp);
fp = fopen("output.txt","r");
fgets(received_string,20,fp);
printf("%s", received_string);
fclose(fp);
return 0;
}
Output:
good bye
When fputc() is executed characters of string variable are written into the file one by one.
When we read the line from the file we get the same string that we entered.
fseek() in C/C++ with example
fseek() is used to move file pointer associated with a given file to a specific position.
Syntax:
int fseek(FILE *pointer, long int offset, int position)
pointer: pointer to a FILE object that identifies the stream.
offset: number of bytes to offset from position
position: position from where offset is added.
returns:
zero if successful, or else it returns a non-zero value
position defines the point with respect to which the file pointer needs to be moved.
It has three values:
SEEK_END : It denotes end of the file.
SEEK_SET : It denotes starting of the file.
SEEK_CUR : It denotes file pointer’s current position.
#include <stdio.h>
int main()
{
FILE *fp;
fp = fopen("test.txt", "r");
fseek(fp, 0, SEEK_END);
printf("%ld", ftell(fp));
return 0;
}
Output:
81
Explanation
The file test.txt contains the following text:
"Someone over there is calling you.
we are going for work.
take care of yourself."
When we implement fseek() we move the pointer by 0 distance with respect to end of file i.e pointer now points to end of the file.
Therefore the output is 81.
Related article: fseek vs rewind in C
ftell() in C with example
ftell() in C is used to find out the position of file pointer in the file with respect to starting of the file.
Syntax of ftell() is:
long ftell(FILE *pointer)
Consider below C program.
The file taken in the example contains the following data :
“Someone over there is calling you.
We are going for work.
Take care of yourself.” (without the quotes)
When the fscanf statement is executed word “Someone” is stored in string and the pointer is moved beyond “Someone”.
Therefore ftell(fp) returns 7 as length of “someone” is 6.
#include<stdio.h>
int main()
{
FILE *fp = fopen("test.txt","r");
char string[20];
fscanf(fp,"%s",string);
printf("%ld", ftell(fp));
return 0;
}
Output : Assuming test.txt contains “Someone over there ….”.
7
lseek() in C/C++ to read the alternate nth byte and write it in another file
From a given file (e.g.
input.txt) read the alternate nth byte and write it on another file with the help of “lseek”.
lseek (C System Call): lseek is a system call that is used to change the location of the read/write pointer of a file descriptor.
The location can be set either in absolute or relative terms.
Function Definition
off_t lseek(int fildes, off_t offset, int whence);
Field Description
int fildes : The file descriptor of the pointer that is going to be moved
off_t offset : The offset of the pointer (measured in bytes).
int whence : The method in which the offset is to be interpreted
(rela, absolute, etc.).
Legal value r this variable are provided at the end.
return value : Returns the offset of the pointer (in bytes) from the
beginning of the file.
If the return value is -1,
then there was an error moving the pointer.
For example, say our Input file is as follows:

#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <fcntl.h>
void func(char arr[], int n)
{
int f_write = open("start.txt", O_RDONLY);
int f_read = open("end.txt", O_WRONLY);
int count = 0;
while (read(f_write, arr, 1))
{
if (count < n)
{
lseek (f_write, n, SEEK_CUR);
write (f_read, arr, 1);
count = n;
}
else
{
count = (2*n);
lseek(f_write, count, SEEK_CUR);
write(f_read, arr, 1);
}
}
close(f_write);
close(f_read);
}
int main()
{
char arr[100];
int n;
n = 5;
func(arr, n);
return 0;
}
Output file (end.txt)
C program to delete a file
The
remove function in C/C++ can be used to delete a file.
The function returns 0 if files is deleted successfully, other returns a non-zero value.
#include<stdio.h>
int main()
{
if (remove("abc.txt") == 0)
printf("Deleted successfully");
else
printf("Unable to delete the file");
return 0;
}
Using remove() function in C, we can write a program which can destroy itself after it is compiled and executed.
Explanation: This can be done using the
remove function in C.
Note that, this is done in Linux environment.
So, the remove function is fed the first parameter in command line argument i.e.
a.out file (executable file) created after compiling .
Hence the program will be destroyed.
#include<stdio.h>
#include<stdlib.h>
int main(int c, char *argv[])
{
printf("By the time you will compile me I will be destroyed \n");
remove(argv[0]);
return 0;
}
Output:
By the time you will compile me I will be destroyed
After the output shown above, the
a.out file will be removed.
C Program to merge contents of two files into a third file
Let the given two files be file1.txt and file2.txt.
The following are steps to merge.
1) Open file1.txt and file2.txt in read mode.
2) Open file3.txt in write mode.
3) Run a loop to one by one copy characters of file1.txt to file3.txt.
4) Run a loop to one by one copy characters of file2.txt to file3.txt.
5) Close all files.
To successfully run the below program file1.txt and fil2.txt must exits in same folder.
#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE *fp1 = fopen("file1.txt", "r");
FILE *fp2 = fopen("file2.txt", "r");
FILE *fp3 = fopen("file3.txt", "w");
char c;
if (fp1 == NULL || fp2 == NULL || fp3 == NULL)
{
puts("Could not open files");
exit(0);
}
while ((c = fgetc(fp1)) != EOF)
fputc(c, fp3);
while ((c = fgetc(fp2)) != EOF)
fputc(c, fp3);
printf("Merged file1.txt and file2.txt into file3.txt");
fclose(fp1);
fclose(fp2);
fclose(fp3);
return 0;
}
Output:
Merged file1.txt and file2.txt into file3.txt
Related Articles :
C Program to print contents of file
fopen() is used to open and
fclose() is used to close a file in C
#include <stdio.h>
#include <stdlib.h> // For exit()
int main()
{
FILE *fptr;
char filename[100], c;
printf("Enter the filename to open \n");
scanf("%s", filename);
fptr = fopen(filename, "r");
if (fptr == NULL)
{
printf("Cannot open file \n");
exit(0);
}
c = fgetc(fptr);
while (c != EOF)
{
printf ("%c", c);
c = fgetc(fptr);
}
fclose(fptr);
return 0;
}
Output:
Enter the filename to open
a.txt
/*Contents of a.txt*/
C Program to print numbers from 1 to N without using semicolon?
How to print numbers from 1 to N without using any semicolon in C.
#include<stdio.h>
#define N 100
What code to add in above snippet such that it doesn’t contain semicolon and prints numbers from 1 to N?
We strongly recommend you to minimize your browser and try this yourself first
Method 1 (Recursive)
#include<stdio.h>
#define N 10
int main(int num)
{
if (num <= N && printf("%d ", num) && main(num + 1))
{
}
}
Output:
1 2 3 4 5 6 7 8 9 10
See
this for complete run.
Thanks to Utkarsh Trivedi for suggesting this solution.
Method 2 (Iterative)
#include<stdio.h>
#define N 10
int main(int num, char *argv[])
{
while (num <= N && printf("%d ", num) && num++)
{
}
}
Output:
1 2 3 4 5 6 7 8 9 10
See
this for complete run.
Thanks to Rahul Huria for suggesting this solution.
How do these solutions work?
main() function can receive arguments.
The first argument is argument count whose value is 1 if no argument is passed to it.
The first argument is always program name.
#include<stdio.h>
int main(int num, char *argv[])
{
printf("num = %d\n", num);
printf("argv[0] = %s ", argv[0]);
}
Output:
num = 1
argv[0] = <file_name>
How will you show memory representation of C variables?
Write a C program to show memory representation of C variables like int, float, pointer, etc.
Algorithm:
Get the address and size of the variable.
Typecast the address to char pointer.
Now loop for size of the variable and print the value at the typecasted pointer.
Program:
#include <stdio.h>
typedef unsigned char *byte_pointer;
void show_bytes(byte_pointer start, int len)
{
int i;
for (i = 0; i < len; i++)
printf(" %.2x", start[i]);
printf("\n");
}
void show_int(int x)
{
show_bytes((byte_pointer) &x, sizeof(int));
}
void show_float(float x)
{
show_bytes((byte_pointer) &x, sizeof(float));
}
void show_pointer(void *x)
{
show_bytes((byte_pointer) &x, sizeof(void *));
}
int main()
{
int i = 1;
float f = 1.0;
int *p = &i;
show_float(f);
show_int(i);
show_pointer(p);
show_int(i);
getchar();
return 0;
}
Condition To Print “HelloWord”
What should be the “condition” so that the following code snippet prints both HelloWorld!
if "condition"
printf ("Hello");
else
printf("World");
Method 1:
#include<stdio.h>
int main()
{
if(!printf("Hello"))
printf("Hello");
else
printf("World");
getchar();
}
Explanation: Printf returns the number of character it has printed successfully.
So, following solutions will also work
if (printf(“Hello”) < 0) or
if (printf("Hello") < 1) etc
Method 2: Using fork()
#include<stdio.h>
#include<unistd.h>
int main()
{
if(fork())
printf("Hello");
else
printf("World");
getchar();
}
This method is contributed by Aravind Alapati.
Please comment if you find more solutions of this.
Change/add only one character and print ‘*’ exactly 20 times
In the below code, change/add only one character and print ‘*’ exactly 20 times.
int main()
{
int i, n = 20;
for (i = 0; i < n; i--)
printf("*");
getchar();
return 0;
}
Solutions:
1.
Replace i by n in for loop’s third expression
C
#include <stdio.h>
int main()
{
int i, n = 20;
for (i = 0; i < n; n--)
printf("*");
getchar();
return 0;
}
Java
edit
link
class GfG {
public static void main(String[] args)
{
int i, n = 20;
for (i = 0; i < n; n--)
System.out.print("*");
}
}
C#
edit
link
using System;
class GfG
{
public static void Main()
{
int i, n = 20;
for (i = 0; i < n; n--)
Console.Write("*");
}
}
2.
Put ‘-‘ before i in for loop’s second expression
#include <stdio.h>
int main()
{
int i, n = 20;
for (i = 0; -i < n; i--)
printf("*");
getchar();
return 0;
}
3.
Replace < by + in for loop's second expression
#include <stdio.h>
int main()
{
int i, n = 20;
for (i = 0; i + n; i--)
printf("*");
getchar();
return 0;
}
Let’s extend the problem little.
Change/add only one character and print ‘*’ exactly 21 times.
Solution: Put negation operator before i in for loop’s second expression.
Explanation: Negation operator converts the number into its one’s complement.
No.
One's complement
0 (00000..00) -1 (1111..11)
-1 (11..1111) 0 (00..0000)
-2 (11..1110) 1 (00..0001)
-3 (11..1101) 2 (00..0010)
...............................................
-20 (11..01100) 19 (00..10011)
#include <stdio.h>
int main()
{
int i, n = 20;
for (i = 0; ~i < n; i--)
printf("*");
getchar();
return 0;
}
Please comment if you find more solutions of above problems.
Program for Sum of the digits of a given number
Given a number, find sum of its digits.
Examples :
Input : n = 687
Output : 21
Input : n = 12
Output : 3
General Algorithm for sum of digits in a given number:
- Get the number
- Declare a variable to store the sum and set it to 0
- Repeat the next two steps till the number is not 0
- Get the rightmost digit of the number with help of remainder ‘%’ operator by dividing it with 10 and add it to sum.
- Divide the number by 10 with help of ‘/’ operator
- Print or return the sum
Below are the solutions to get sum of the digits.
1.
Iterative:
C++
# include<iostream>
using namespace std;
class gfg
{
public:
int getSum(int n)
{
int sum = 0;
while (n != 0)
{
sum = sum + n % 10;
n = n/10;
}
return sum;
}
};
int main()
{
gfg g;
int n = 687;
cout<< g.getSum(n);
return 0;
}
C
# include<stdio.h>
int getSum(int n)
{
int sum = 0;
while (n != 0)
{
sum = sum + n % 10;
n = n/10;
}
return sum;
}
int main()
{
int n = 687;
printf(" %d ", getSum(n));
return 0;
}
Java
edit
link
import java.io.*;
class GFG {
static int getSum(int n)
{
int sum = 0;
while (n != 0)
{
sum = sum + n % 10;
n = n/10;
}
return sum;
}
public static void main(String[] args)
{
int n = 687;
System.out.println(getSum(n));
}
}
Python3
edit
link
def getSum(n):
sum = 0
while (n != 0):
sum = sum + int(n % 10)
n = int(n/10)
return sum
n = 687
print(getSum(n))
C#
edit
link
using System;
class GFG
{
static int getSum(int n)
{
int sum = 0;
while (n != 0)
{
sum = sum + n % 10;
n = n/10;
}
return sum;
}
public static void Main()
{
int n = 687;
Console.Write(getSum(n));
}
}
PHP
edit
link
<?php
function getsum($n)
{
$sum = 0;
while ($n != 0)
{
$sum = $sum + $n % 10;
$n = $n/10;
}
return $sum;
}
$n = 687;
$res = getsum($n);
echo("$res");
?>
Output :
21
How to compute in single line?
Below function has three lines instead of one line but it calculates sum in line.
It can be made one line function if we pass pointer to sum.
C++
# include<iostream>
using namespace std;
class gfg
{
public:
int getSum(int n)
{
int sum;
for (sum = 0; n > 0; sum += n % 10, n /= 10);
return sum;
}
};
int main()
{
gfg g;
int n = 687;
cout<< g.getSum(n);
return 0;
}
C
# include<stdio.h>
int getSum(int n)
{
int sum;
for (sum = 0; n > 0; sum += n % 10, n /= 10);
return sum;
}
int main()
{
int n = 687;
printf(" %d ", getSum(n));
return 0;
}
Java
edit
link
import java.io.*;
class GFG {
static int getSum(int n)
{
int sum;
for (sum = 0; n > 0; sum += n % 10,
n /= 10);
return sum;
}
public static void main(String[] args)
{
int n = 687;
System.out.println(getSum(n));
}
}
Python3
edit
link
def getSum(n):
sum = 0
while(n > 0):
sum += int(n%10)
n = int(n/10)
return sum
n = 687
print(getSum(n))
C#
edit
link
using System;
class GFG
{
static int getSum(int n)
{
int sum;
for (sum = 0; n > 0; sum += n % 10,
n /= 10);
return sum;
}
public static void Main()
{
int n = 687;
Console.Write(getSum(n));
}
}
PHP
edit
link
<?php
function getsum($n)
{
for ($sum = 0; $n > 0; $sum += $n % 10,
$n /= 10);
return $sum;
}
$n = 687;
echo(getsum($n));
?>
Output :
21
2.
Recursive
Thanks to ayesha for providing the below recursive solution.
C++
#include<iostream>
using namespace std;
class gfg
{
public: int sumDigits(int no)
{
return no == 0 ? 0 : no%10 + sumDigits(no/10) ;
}
};
int main(void)
{
gfg g;
cout<<g.sumDigits(687);
return 0;
}
C
int sumDigits(int no)
{
return no == 0 ? 0 : no%10 + sumDigits(no/10) ;
}
int main(void)
{
printf("%d", sumDigits(687));
return 0;
}
Java
edit
link
import java.io.*;
class GFG {
static int sumDigits(int no)
{
return no == 0 ? 0 : no%10 +
sumDigits(no/10) ;
}
public static void main(String[] args)
{
System.out.println(sumDigits(687));
}
}
Python3
edit
link
def sumDigits(no):
return 0 if no == 0 else int(no%10) + sumDigits(int(no/10))
print(sumDigits(687))
C#
edit
link
using System;
class GFG
{
static int sumDigits(int no)
{
return no == 0 ? 0 : no % 10 +
sumDigits(no / 10);
}
public static void Main()
{
Console.Write(sumDigits(687));
}
}
PHP
edit
link
<?php
function sumDigits($no)
{
return $no == 0 ? 0 : $no % 10 +
sumDigits($no / 10) ;
}
echo sumDigits(687);
?>
Output :
21
Please write comments if you find the above codes/algorithms incorrect, or find better ways to solve the same problem.
What is the best way in C to convert a number to a string?
Solution: Use sprintf() function.
#include<stdio.h>
int main()
{
char result[50];
float num = 23.34;
sprintf(result, "%f", num);
printf("\n The string for the num is %s", result);
getchar();
}
You can also write your own function using ASCII values of numbers.
Program to compute Log n
Write a one line C function that calculates and returns

.
For example, if n = 64, then your function should return 6, and if n = 129, then your function should return 7.
Using Recursion
C
#include <stdio.h>
unsigned int Log2n(unsigned int n)
{
return (n > 1) ? 1 + Log2n(n / 2) : 0;
}
int main()
{
unsigned int n = 32;
printf("%u", Log2n(n));
getchar();
return 0;
}
Java
edit
link
class Gfg1
{
static int Log2n(int n)
{
return (n > 1) ? 1 + Log2n(n / 2) : 0;
}
public static void main(String args[])
{
int n = 32;
System.out.println(Log2n(n));
}
}
Python3
edit
link
def Log2n(n):
return 1 + Log2n(n / 2) if (n > 1) else 0
n = 32
print(Log2n(n))
C#
edit
link
using System;
class GFG {
static int Log2n(int n)
{
return (n > 1) ? 1 +
Log2n(n / 2) : 0;
}
public static void Main()
{
int n = 32;
Console.Write(Log2n(n));
}
}
Output :
5
Time complexity: O(log n)
Auxiliary space: O(log n) if the stack size is considered during recursion otherwise O(1)
Using inbuilt log function
We can use the inbuilt function of standard library which is available in library.
C
#include <math.h>
#include <stdio.h>
int main()
{
unsigned int n = 32;
printf("%d", (int)log2(n));
return 0;
}
Java
edit
link
import java.util.*;
class Gfg2
{
public static void main(String args[])
{
int n = 32;
System.out.println((int)(Math.log(n) / Math.log(2)));
}
}
Output :
5
Time complexity: O(1)
Auxiliary space: O(1)
Let us try an extended version of the problem.
Write a one line function Logn(n, r) which returns

.
Using Recursion
C
#include <stdio.h>
unsigned int Logn(unsigned int n, unsigned int r)
{
return (n > r - 1) ? 1 + Logn(n / r, r) : 0;
}
int main()
{
unsigned int n = 256;
unsigned int r = 3;
printf("%u", Logn(n, r));
return 0;
}
Java
edit
link
class Gfg3
{
static int Logn(int n, int r)
{
return (n > r - 1) ? 1 + Logn(n / r, r) : 0;
}
public static void main(String args[])
{
int n = 256;
int r = 3;
System.out.println(Logn(n, r));
}
}
Output :
5
Time complexity: O(log n)
Auxiliary space: O(log n) if the stack size is considered during recursion otherwise O(1)
Using inbuilt log function
We only need to use logarithm property to find the value of log(n) on arbitrary base
r.
i.e.,

where
k can be any anything, which for standard log functions are either
e or
10
C
#include <math.h>
#include <stdio.h>
unsigned int Logn(unsigned int n, unsigned int r)
{
return log(n) / log(r);
}
int main()
{
unsigned int n = 256;
unsigned int r = 3;
printf("%u", Logn(n, r));
return 0;
}
Java
edit
link
import java.util.*;
class Gfg4 {
public static void main(String args[])
{
int n = 256;
int r = 3;
System.out.println((int)(Math.log(n) / Math.log(r)));
}
}
Output :
5
Time complexity: O(1)
Auxiliary space: O(1)
Print “Even” or “Odd” without using conditional statement
Write a C/C++ program that accepts a number from the user and prints “Even” if the entered number is even and prints “Odd” if the number is odd.
You are not allowed to use any comparison (==, <,>,…etc) or conditional (if, else, switch, ternary operator,..etc) statement.
Method 1
Below is a tricky code can be used to print “Even” or “Odd” accordingly.
C++
#include<iostream>
#include<conio.h>
using namespace std;
int main()
{
char arr[2][5] = {"Even", "Odd"};
int no;
cout << "Enter a number: ";
cin >> no;
cout << arr[no%2];
getch();
return 0;
}
Python3
edit
link
arr = ["Even", "Odd"]
print ("Enter the number")
no = input()
print (arr[int(no) % 2])
PHP
edit
link
<?php
$arr = ["Even", "Odd"];
$input = 5;
echo ($arr[$input % 2]);
?>
Method 2
Below is another tricky code can be used to print “Even” or “Odd” accordingly.
Thanks to
student for suggesting this method.
#include<stdio.h>
int main()
{
int no;
printf("Enter a no: ");
scanf("%d", &no);
(no & 1 && printf("odd"))|| printf("even");
return 0;
}
Please write comments if you find the above code incorrect, or find better ways to solve the same problem
How will you print numbers from 1 to 100 without using loop?
If we take a look at this problem carefully, we can see that the idea of “loop” is to track some counter value e.g.
“i=0” till “i <= 100".
So if we aren't allowed to use loop, how else can be track something in C language!
Well, one possibility is the use of ‘recursion’ provided we use the terminating condition carefully.
Here is a solution that prints numbers using recursion.
C++
#include <iostream>
using namespace std;
class gfg
{
public:
void printNos(unsigned int n)
{
if(n > 0)
{
printNos(n - 1);
cout << n << " ";
}
return;
}
};
int main()
{
gfg g;
g.printNos(100);
return 0;
}
C
#include <stdio.h>
void printNos(unsigned int n)
{
if(n > 0)
{
printNos(n - 1);
printf("%d ", n);
}
return;
}
int main()
{
printNos(100);
getchar();
return 0;
}
Java
edit
link
import java.io.*;
import java.util.*;
import java.text.*;
import java.math.*;
import java.util.regex.*;
class GFG
{
static void printNos(int n)
{
if(n > 0)
{
printNos(n - 1);
System.out.print(n + " ");
}
return;
}
public static void main(String[] args)
{
printNos(100);
}
}
Python3
edit
link
def printNos(n):
if n > 0:
printNos(n - 1)
print(n, end = ' ')
printNos(100)
C#
edit
link
using System;
class GFG
{
static void printNos(int n)
{
if(n > 0)
{
printNos(n - 1);
Console.Write(n + " ");
}
return;
}
public static void Main()
{
printNos(100);
}
}
PHP
edit
link
<?php
function printNos($n)
{
if($n > 0)
{
printNos($n - 1);
echo $n, " ";
}
return;
}
printNos(100);
?>
Output :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
16 17 18 19 20 21 22 23 24 25 26 27
28 29 30 31 32 33 34 35 36 37 38 39
40 41 42 43 44 45 46 47 48 49 50 51
52 53 54 55 56 57 58 59 60 61 62 63
64 65 66 67 68 69 70 71 72 73 74 75
76 77 78 79 80 81 82 83 84 85 86 87
88 89 90 91 92 93 94 95 96 97 98 99
100
Time Complexity : O(n)
Now try writing a program that does the same but without any “if” construct.
Hint — use some operator which can be used instead of “if”.
Please note that recursion technique is good but every call to the function creates one “stack-frame” in program stack.
So if there’s constraint to the limited memory and we need to print large set of numbers, “recursion” might not be a good idea.
So what could be the other alternative?
Another alternative is “goto” statement.
Though use of “goto” is not suggestible as a general programming practice as “goto” statement changes the normal program execution sequence yet in some cases, use of “goto” is the best working solution.
So please give a try printing numbers from 1 to 100 with “goto” statement.
You can use
GfG IDE!
Print 1 to 100 in C++, without loop and recursion
Write a C program to print “Geeks for Geeks” without using a semicolon
First of all we have to understand how printf() function works.
Prototype of printf() function is:
int printf( const char *format , ...)
Parameter
-
format: This is a string that contains a text to be written to stdout.
-
Additional arguments: … (Three dots are called ellipses) which indicates the variable number of arguments depending upon the format string.
printf() returns the total number of characters written to stdout.
Therefore it can be used as a condition check in an if condition, while condition, switch case and Macros.
Let’s see each of these conditions one by one.
-
Using if condition:
#include<stdio.h>
int main()
{
if (printf("Geeks for Geeks") )
{ }
}
-
Using while condition:
#include<stdio.h>
int main(){
while (!printf( "Geeks for Geeks" ))
{ }
}
-
Using switch case:
#include<stdio.h>
int main(){
switch (printf("Geeks for Geeks" ))
{ }
}
-
Using Macros:
#include<stdio.h>
#define PRINT printf("Geeks for Geeks")
int main()
{
if (PRINT)
{ }
}
Output: Geeks for Geeks
One trivial extension of the above problem: Write a C program to print “;” without using a semicolon
#include<stdio.h>
int main()
{
if (printf("%c", 59))
{
}
}
Output: ;
This blog is contributed by
Shubham Bansal.
If you like GeeksforGeeks and would like to contribute, you can also write an article using
contribute.geeksforgeeks.org or mail your article to contribute@geeksforgeeks.org.
See your article appearing on the GeeksforGeeks main page and help other Geeks.
Write a one line C function to round floating point numbers
Algorithm: roundNo(num)
1.
If num is positive then add 0.5.
2.
Else subtract 0.5.
3.
Type cast the result to int and return.
Example:
num = 1.67, (int) num + 0.5 = (int)2.17 = 2
num = -1.67, (int) num – 0.5 = -(int)2.17 = -2
Implementation:
# include<stdio.h>
int roundNo(float num)
{
return num < 0 ? num - 0.5 : num + 0.5;
}
int main()
{
printf("%d", roundNo(-1.777));
getchar();
return 0;
}
Output: -2
Time complexity: O(1)
Space complexity: O(1)
Now try rounding for a given precision.
i.e., if given precision is 2 then function should return 1.63 for 1.63322 and -1.63 for 1.6332.
Implement Your Own sizeof
Here is an implementation.
#include<stdio.h>
#define my_sizeof(type) (char *)(&type+1)-(char*)(&type)
int main()
{
double x;
printf("%ld", my_sizeof(x));
getchar();
return 0;
}
Type is like a local variable to the macro.
&type gives the address of the variable (double x) declared in the program and incrementing it with 1 gives the address where the next variable of type x can be stored (here addr_of(x) + 8, for the size of a double is 8B).
The difference gives the result that how many variables of type of x can be stored in that amount of memory which will obviously be 1 for the type x (for incrementing it with 1 and taking the difference is what we’ve done).
Typecasting it into char* and taking the difference will tell us how many variables of type char can be stored in the given memory space (the difference).
Since each char requires the only 1B of memory, therefore (amount of memory)/1 will give the number of bytes between two successive memory locations of the type of the variable passed on to the macro and hence the amount of memory that the variable of type x requires.
But you won’t be able to pass any literal to this macro and know their size.
You can also implement using the function instead of a macro, but function implementation cannot be done in C as C doesn’t support function overloading and sizeof() is supposed to receive parameters of all data types.
Note that the above implementation assumes that the size of character is one byte.
Time Complexity: O(1)
Space Complexity: O(1)
How to count set bits in a floating point number in C?
Given a
floating point number, write a function to count set bits in its binary representation.
For example, floating point representation of 0.15625 has 6 set bits (See
this).
A typical C compiler uses
single precision floating point format.
We can use the idea discussed
here.
The idea is to take address of the given floating point number in a pointer variable, typecast the pointer to char * type and process individual bytes one by one.
We can easily count set bits in a char using the techniques discussed
here.
Following is C implementation of the above idea.
#include <stdio.h>
unsigned int countSetBitsChar(char n)
{
unsigned int count = 0;
while (n)
{
n &= (n-1);
count++;
}
return count;
}
unsigned int countSetBitsFloat(float x)
{
unsigned int n = sizeof(float)/sizeof(char);
char *ptr = (char *)&x;
int count = 0;
for (int i = 0; i < n; i++)
{
count += countSetBitsChar(*ptr);
ptr++;
}
return count;
}
int main()
{
float x = 0.15625;
printf ("Binary representation of %f has %u set bits ", x,
countSetBitsFloat(x));
return 0;
}
Output:
Binary representation of 0.156250 has 6 set bits
How to change the output of printf() in main() ?
Consider the following program.
Change the program so that the output of printf is always 10.
It is not allowed to change main().
Only fun() can be changed.
void fun()
{
}
int main()
{
int i = 10;
fun();
i = 20;
printf("%d", i);
return 0;
}
We can use
Macro Arguments to change the output of printf.
#include <stdio.h>
void fun()
{
#define printf(x, y) printf(x, 10);
}
int main()
{
int i = 10;
fun();
i = 20;
printf("%d", i);
return 0;
}
Output:
10
How to find length of a string without string.h and loop in C?
Find the length of a string without using any loops and string.h in C.
Your program is supposed to behave in following way:
Enter a string: GeeksforGeeks (Say user enters GeeksforGeeks)
Entered string is: GeeksforGeeks
Length is: 13
You may assume that the length of entered string is always less than 100.
The following is solution.
#include <stdio.h>
int main()
{
char str[100];
printf("Enter a string: \n");
gets(str);
printf("Entered string is:%s\n", str);
printf( "\rLength is: %d",strlen(str));
return 0;
}
Output:
Enter a string: GeeksforGeeks
Entered string is: GeeksforGeeks
Length is: 13
The idea is to use return values of printf() and gets().
gets() returns the enereed string.
printf() returns the number of characters successfully written on output.
In the above program, gets() returns the entered string.
We print the length using the first printf.
The second printf() calls gets() and prints the entered string using returned value of gets(), it also prints 20 extra characters for printing “Entered string is: ” and “\n”.
That is why we subtract 20 from the returned value of second printf and get the length.
Implement your own itoa()
itoa function converts integer into null-terminated string.
It can convert negative numbers too.
The standard definition of itoa function is give below:-
char* itoa(int num, char* buffer, int base)
The third parameter base specify the conversion base.
For example:- if base is 2, then it will convert the integer into its binary compatible string or if base is 16, then it will create hexadecimal converted string form of integer number.
If base is 10 and value is negative, the resulting string is preceded with a minus sign (-).
With any other base, value is always considered unsigned.
Reference:
http://www.cplusplus.com/reference/cstdlib/itoa/?kw=itoa
Examples:
itoa(1567, str, 10) should return string "1567"
itoa(-1567, str, 10) should return string "-1567"
itoa(1567, str, 2) should return string "11000011111"
itoa(1567, str, 16) should return string "61f"
Individual digits of the given number must be processed and their corresponding characters must be put in the given string.
Using repeated division by the given base, we get individual digits from least significant to most significant digit.
But in the output, these digits are needed in reverse order.
Therefore, we reverse the string obtained after repeated division and return it.
#include <iostream>
using namespace std;
void reverse(char str[], int length)
{
int start = 0;
int end = length -1;
while (start < end)
{
swap(*(str+start), *(str+end));
start++;
end--;
}
}
char* itoa(int num, char* str, int base)
{
int i = 0;
bool isNegative = false;
if (num == 0)
{
str[i++] = '0';
str[i] = '\0';
return str;
}
if (num < 0 && base == 10)
{
isNegative = true;
num = -num;
}
while (num != 0)
{
int rem = num % base;
str[i++] = (rem > 9)? (rem-10) + 'a' : rem + '0';
num = num/base;
}
if (isNegative)
str[i++] = '-';
str[i] = '\0';
reverse(str, i);
return str;
}
int main()
{
char str[100];
cout << "Base:10 " << itoa(1567, str, 10) << endl;
cout << "Base:10 " << itoa(-1567, str, 10) << endl;
cout << "Base:2 " << itoa(1567, str, 2) << endl;
cout << "Base:8 " << itoa(1567, str, 8) << endl;
cout << "Base:16 " << itoa(1567, str, 16) << endl;
return 0;
}
Output:
Base:10 1567
Base:10 -1567
Base:2 11000011111
Base:8 3037
Base:16 61f
Write a C program that does not terminate when Ctrl+C is pressed
Write a C program that doesn’t terminate when Ctrl+C is pressed.
It prints a message “Cannot be terminated using Ctrl+c” and continues execution.
We can use
signal handling in C for this.
When
Ctrl+C is pressed, SIGINT signal is generated, we can catch this signal and run our defined signal handler.
C standard defines following 6 signals in signal.h header file.
SIGABRT – abnormal termination.
SIGFPE – floating point exception.
SIGILL – invalid instruction.
SIGINT – interactive attention request sent to the program.
SIGSEGV – invalid memory access.
SIGTERM – termination request sent to the program.
Additional signals are specified Unix and Unix-like operating systems (such as Linux) defines more than 15 additional signals.
See
http://en.wikipedia.org/wiki/Unix_signal#POSIX_signals
The standard C library function
signal() can be used to set up a handler for any of the above signals.
#include <stdio.h>
#include <signal.h>
void sigintHandler(int sig_num)
{
signal(SIGINT, sigintHandler);
printf("\n Cannot be terminated using Ctrl+C \n");
fflush(stdout);
}
int main ()
{
signal(SIGINT, sigintHandler);
while(1)
{
}
return 0;
}
Output: When Ctrl+C was pressed two times
Cannot be terminated using Ctrl+C
Cannot be terminated using Ctrl+C
How to measure time taken by a function in C?
To calculate time taken by a process, we can use
clock() function which is available
time.h.
We can call the clock function at the beginning and end of the code for which we measure time, subtract the values, and then divide by
CLOCKS_PER_SEC (the number of clock ticks per second) to get processor time, like following.
#include <time.h>
clock_t start, end;
double cpu_time_used;
start = clock();
...
/* Do the work.*/
end = clock();
cpu_time_used = ((double) (end - start)) / CLOCKS_PER_SEC;
Following is a sample C program where we measure time taken by fun().
The function fun() waits for enter key press to terminate.
#include <stdio.h>
#include <time.h>
void fun()
{
printf("fun() starts \n");
printf("Press enter to stop fun \n");
while(1)
{
if (getchar())
break;
}
printf("fun() ends \n");
}
int main()
{
clock_t t;
t = clock();
fun();
t = clock() - t;
double time_taken = ((double)t)/CLOCKS_PER_SEC;
printf("fun() took %f seconds to execute \n", time_taken);
return 0;
}
Output: The following output is obtained after waiting for around 4 seconds and then hitting enter key.
fun() starts
Press enter to stop fun
fun() ends
fun() took 4.017000 seconds to execute
How to find time taken by a command/program on Linux Shell?
Print a long int in C using putchar() only
Write a C function
print(n) that takes a long int number
n as argument, and prints it on console.
The only allowed library function is
putchar(), no other function like
itoa() or
printf() is allowed.
Use of loops is also not allowed.
We strongly recommend to minimize the browser and try this yourself first.
This is a simple trick question.
Since putchar() prints a character, we need to call putchar() for all digits.
Recursion can always be used to replace iteration, so using recursion we can print all digits one by one.
Now the question is
putchar() prints a character, how to print digits using putchar().
We need to convert every digit to its corresponding ASCII value, this can be done by using ASCII value of ‘0’.
Following is complete C program.
#include <stdio.h>
void print(long n)
{
if (n < 0) {
putchar('-');
n = -n;
}
if (n/10)
print(n/10);
putchar(n%10 + '0');
}
int main()
{
long int n = 12045;
print(n);
return 0;
}
Output:
12045
One important thing to note is the sequence of putchar() and recursive call print(n/10).
Since the digits should be printed left to right, the recursive call must appear before putchar() (The rightmost digit should be printed at the end, all other digits must be printed before it).
Convert a floating point number to string in C
Write a C function ftoa() that converts a given floating-point number or a double to a string.
Use of standard library functions for direct conversion is not allowed.
The following is prototype of ftoa().
The article provides insight of conversion of C double to string.
ftoa(n, res, afterpoint)
n --> Input Number
res[] --> Array where output string to be stored
afterpoint --> Number of digits to be considered after the point.
Example:
- ftoa(1.555, str, 2) should store “1.55” in res.
- ftoa(1.555, str, 0) should store “1” in res.
We strongly recommend to minimize the browser and try this yourself first.
A simple way is to use
sprintf(), but use of standard library functions for direct conversion is not allowed.
Approach: The idea is to separate integral and fractional parts and convert them to strings separately.
Following are the detailed steps.
- Extract integer part from floating-point or double number.
- First, convert integer part to the string.
- Extract fraction part by exacted integer part from n.
- If d is non-zero, then do the following.
- Convert fraction part to an integer by multiplying it with pow(10, d)
- Convert the integer value to string and append to the result.
Following is C implementation of the above approach.
#include <math.h>
#include <stdio.h>
void reverse(char* str, int len)
{
int i = 0, j = len - 1, temp;
while (i < j) {
temp = str[i];
str[i] = str[j];
str[j] = temp;
i++;
j--;
}
}
int intToStr(int x, char str[], int d)
{
int i = 0;
while (x) {
str[i++] = (x % 10) + '0';
x = x / 10;
}
while (i < d)
str[i++] = '0';
reverse(str, i);
str[i] = '\0';
return i;
}
void ftoa(float n, char* res, int afterpoint)
{
int ipart = (int)n;
float fpart = n - (float)ipart;
int i = intToStr(ipart, res, 0);
if (afterpoint != 0) {
res[i] = '.';
fpart = fpart * pow(10, afterpoint);
intToStr((int)fpart, res + i + 1, afterpoint);
}
}
int main()
{
char res[20];
float n = 233.007;
ftoa(n, res, 4);
printf("\"%s\"\n", res);
return 0;
}
Output:
"233.0070"
Note: The program performs similar operation if instead of float, a double type is taken.
How to write a running C code without main()?
Write a C language code that prints
GeeksforGeeks without any main function.
Logically it’s seems impossible to write a C program without using a main() function.
Since every program must have a main() function because:-
-
It’s an entry point of every C/C++ program.
-
All Predefined and User-defined Functions are called directly or indirectly through the main.
Therefore we will use preprocessor(a program which processes the source code before compilation) directive #define with arguments to give an impression that the program runs without main.
But in reality it runs with a hidden main function.
Let’s see how the preprocessor doing their job:-
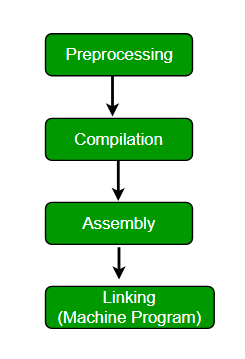
Hence it can be solved in following ways:-
- Using a macro that defines main
#include<stdio.h>
#define fun main
int fun(void)
{
printf("Geeksforgeeks");
return 0;
}
Output: Geeksforgeeks
- Using Token-Pasting Operator
The above solution has word ‘main’ in it.
If we are not allowed to even write main, we can use token-pasting operator (see this for details)
#include<stdio.h>
#define fun m##a##i##n
int fun()
{
printf("Geeksforgeeks");
return 0;
}
Output: Geeksforgeeks
-
Using Argumented Macro
#include<stdio.h>
#define begin(m,a,i,n) m##a##i##n
#define start begin(m,a,i,n)
void start() {
printf("Geeksforgeeks");
}
Output: Geeksforgeeks
-
Modify the entry point during compilation
#include<stdio.h>
#include<stdlib.h>
int nomain();
void _start(){
nomain();
exit(0);
}
int nomain()
{
puts("Geeksforgeeks");
return 0;
}
Output:
Geeksforgeeks
Compilation using command :
gcc filename.c -nostartfiles
(nostartfiles option tells the compiler to avoid standard linking)
Explanation:
Under normal compilation the body of _start() will contain a function call to main() [ this _start() will be appended to every code during normal compilation], so if that main() definition is not present it will result in error like “In function `_start’:
(.text+0x20): undefined reference to `main’.
In the above code what we have done is that we have defined our own _start() and defined our own entry point i.e nomain()
- This method is contributed by Aravind Alapati
Refer
Executing main() in C – behind the scene for another solution.
Write your own memcpy() and memmove()
The
memcpy function is used to copy a block of data from a source address to a destination address.
Below is its prototype.
void * memcpy(void * destination, const void * source, size_t num);
The idea is to simply typecast given addresses to char *(char takes 1 byte).
Then one by one copy data from source to destination.
Below is implementation of this idea.
#include<stdio.h>
#include<string.h>
void myMemCpy(void *dest, void *src, size_t n)
{
char *csrc = (char *)src;
char *cdest = (char *)dest;
for (int i=0; i<n; i++)
cdest[i] = csrc[i];
}
int main()
{
char csrc[] = "GeeksforGeeks";
char cdest[100];
myMemCpy(cdest, csrc, strlen(csrc)+1);
printf("Copied string is %s", cdest);
int isrc[] = {10, 20, 30, 40, 50};
int n = sizeof(isrc)/sizeof(isrc[0]);
int idest[n], i;
myMemCpy(idest, isrc, sizeof(isrc));
printf("\nCopied array is ");
for (i=0; i<n; i++)
printf("%d ", idest[i]);
return 0;
}
Output:
Copied string is GeeksforGeeks
Copied array is 10 20 30 40 50
memmove() is similar to memcpy() as it also copies data from a source to destination.
memcpy() leads to problems when source and destination addresses overlap as memcpy() simply copies data one by one from one location to another.
For example consider below program.
#include <stdio.h>
#include <string.h>
int main()
{
char csrc[100] = "Geeksfor";
memcpy(csrc+5, csrc, strlen(csrc)+1);
printf("%s", csrc);
return 0;
}
Output:
GeeksGeeksfor
Since the input addresses are overlapping, the above program overwrites the original string and causes data loss.
#include <stdio.h>
#include <string.h>
int main()
{
char csrc[100] = "Geeksfor";
memmove(csrc+5, csrc, strlen(csrc)+1);
printf("%s", csrc);
return 0;
}
Output:
GeeksGeeksfor
How to implement memmove()?
The trick here is to use a temp array instead of directly copying from src to dest.
The use of temp array is important to handle cases when source and destination addresses are overlapping.
#include<stdio.h>
#include<string.h>
void myMemMove(void *dest, void *src, size_t n)
{
char *csrc = (char *)src;
char *cdest = (char *)dest;
char *temp = new char[n];
for (int i=0; i<n; i++)
temp[i] = csrc[i];
for (int i=0; i<n; i++)
cdest[i] = temp[i];
delete [] temp;
}
int main()
{
char csrc[100] = "Geeksfor";
myMemMove(csrc+5, csrc, strlen(csrc)+1);
printf("%s", csrc);
return 0;
}
Output:
GeeksGeeksfor
Optimizations:
The algorithm is inefficient (and honestly double the time if you use a temporary array).
Double copies should be avoided unless if it is really impossible.
In this case though it is easily possible to avoid double copies by picking a direction of copy.
In fact this is what the memmove() library function does.
By comparing the src and the dst addresses you should be able to find if they overlap.
– If they do not overlap, you can copy in any direction
– If they do overlap, find which end of dest overlaps with the source and choose the direction of copy accordingly.
– If the beginning of dest overlaps, copy from end to beginning
– If the end of dest overlaps, copy from beginning to end
– Another optimization would be to copy by word size.
Just be careful to handle the boundary conditions.
– A further optimization would be to use vector instructions for the copy since they’re contiguous.
C program to print characters without using format specifiers
As we know that there are various
format specifiers in C like %d, %f, %c etc, to help us print characters or other data types.
We normally use these specifiers along with the
printf() function to print any variables.
But there is also a way to print characters specifically without the use of %c format specifier.
This can be obtained by using the below-shown method to get the character value of any ASCII codes of any particular character.
Example:
#include <stdio.h>
int main()
{
printf("\x47 \n");
printf("\x45 \n");
printf("\x45 \n");
printf("\x4b \n");
printf("\x53");
return 0;
}
Output:
G
E
E
K
S
C program to print a string without any quote (singe or double) in the program
Print a string without using quotes anywhere in the program using C or C++.
Note : should not read input from the console.
The idea is to use
macro processor in C (Refer point 6 of this article).
A token passed to macro can be converted to a string literal by using # before it.
#include <stdio.h>
#define get(x) #x
int main()
{
printf(get(vignesh));
return 0;
}
Output:
vignesh
Execute both if and else statements in C/C++ simultaneously
Write a C/C++ program that execute both if-else block statements simultaneously.
Syntax of if-else statement in C/C++ language is:
if (Boolean expression)
{
// Statement will execute only
// if Boolean expression is true
}
else
{
// Statement will execute only if
// the Boolean expression is false
}
Hence we can conclude that only one of the block of if-else statement will execute according to the condition of Boolean expression.
But we can able to make our program so that both the statements inside if and else will execute simultaneously.
The trick is to use goto statement which provides an unconditional jump from the ‘goto’ to a labelled statement in the same function.
Below is C/C++ program to execute both statements simultaneously:-
#include <stdio.h>
int main()
{
if (1)
{
label_1: printf("Hello ");
goto label_2;
}
else
{
goto label_1;
label_2: printf("Geeks");
}
return 0;
}
Output:
Hello Geeks
Therefore both the statements of if and else block executed simultaneously.
Another interesting fact can be seen that Output will always remain same and will not depend upon the whether the Boolean condition is true or false.
NOTE – Use of goto statement is highly discouraged in any programming language because it makes difficult to trace the control flow of a program, making the program hard to understand and hard to modify.
As a programmer we should avoid the use of goto statement in C/C++.
This blog is contributed by
Shubham Bansal.
If you like GeeksforGeeks and would like to contribute, you can also write an article using
contribute.geeksforgeeks.org or mail your article to contribute@geeksforgeeks.org.
See your article appearing on the GeeksforGeeks main page and help other Geeks.
Print “Hello World” in C/C++ without using any header file
Write a C/C++ program that prints
Hello World without including any header file.
Conceptually it’s seems impractical to write a C/C++ program that print Hello World without using a header file of “stdio.h”.
Since the declaration of printf() function contains in the “stdio.h” header file.
But we can easily achieve this by taking the advantage of C pre-processor directives.
The fact is at the time of compiling a program, the first phase of C preprocessing expands all header files into a single file and after that compiler itself compiles the expanded file.
Therefore we just need to extract the declaration of printf() function from header file and use it in our main program like that:-
- C language: Just declare the printf() function taken from “stdio.h” header file.
int printf(const char *format, ...);
int main()
{
printf( "Hello World" );
return 0;
}
Output: Hello World
- C++ language: We can’t directly put the declaration of printf() function as in previous case due to the problem of Name mangling in C++.
See this to know more about Name mangling.
Therefore we just need to declare the printf() inside extern keyword like that:-
extern "C"
{
int printf(const char *format, ...);
}
int main()
{
printf( "Hello World" );
return 0;
}
Output: Hello World
See
this to know more about all phases of compilation of C program.
This blog is contributed by
Shubham Bansal.
If you like GeeksforGeeks and would like to contribute, you can also write an article using
contribute.geeksforgeeks.org or mail your article to contribute@geeksforgeeks.org.
See your article appearing on the GeeksforGeeks main page and help other Geeks.
Quine – A self-reproducing program
A quine is a program which prints a copy of its own as the only output.
A quine takes no input.
Quines are named after the American mathematician and logician Willard Van Orman Quine (1908–2000).
The interesting thing is you are not allowed to use open and then print file of the program.
To the best of our knowledge, below is the shortest quine in C.
main() { char *s="main() { char *s=%c%s%c; printf(s,34,s,34); }"; printf(s,34,s,34); }
This program uses the printf function without including its corresponding header (#include
), which can result in undefined behavior.
Also, the return type declaration for main has been left off to reduce the length of the program.
Two 34s are used to print double quotes around the string s.
Following is a shorter version of the above program suggested by Narendra.
main(a){printf(a="main(a){printf(a=%c%s%c,34,a,34);}",34,a,34);}
If you find a shorter C quine or you want to share quine in other programming languages, then please do write in the comment section.
Quine in Python
Source:
http://en.wikipedia.org/wiki/Quine_%28computing%29
Optimization Techniques | Set 2 (swapping)
How to swap two variables?
The question may look silly, neither geeky.
See the following piece of code to swap two integers (XOR swapping),
void myswap(int *x, int *y)
{
if (x != y)
{
*x^=*y^=*x^=*y;
}
}
At first glance, we may think nothing wrong with the code.
However, when prompted for reason behind opting for XOR swap logic, the person was clue less.
Perhaps any commutative operation can fulfill the need with some corner cases.
Avoid using fancy code snippets in production software.
They create runtime surprises.
We can observe the following notes on above code
- The code behavior is undefined.
The statement *x^=*y^=*x^=*y; modifying a variable more than once in without any sequence point.
- It creates pipeline stalls when executed on a processor with pipeline architecture.
- The compiler can’t take advantage in optimizing the swapping operation.
Some processors will provide single instruction to swap two variables.
When we opted for standard library functions, there are more chances that the library would have been optimized.
Even the compiler can recognize such standard function and generates optimum code.
- Code readability is poor.
It is very much important to write maintainable code.
ASCII NUL, ASCII 0 (‘0’) and Numeric literal 0
The ASCII NUL and zero are represented as 0x00 and 0x30 respectively.
An ASCII NUL character serves as sentinel characters of strings in C/C++.
When the programmer uses ‘0’ in his code, it will be represented as 0x30 in hex form.
What will be filled in the binary representation of ‘integer’ in the following program?
char charNUL = '\0';
unsigned int integer = 0;
char charBinary = '0';
The binary form of charNUL will have all its bits set to logic 0.
The binary form of integer will have all its bits set to logic 0, which means each byte will be filled with NUL character (\ 0).
The binary form of charBinary will be set to binary equivalent of hex 0x30.
Little and Big Endian Mystery
What are these?
Little and big endian are two ways of storing multibyte data-types ( int, float, etc).
In little endian machines, last byte of binary representation of the multibyte data-type is stored first.
On the other hand, in big endian machines, first byte of binary representation of the multibyte data-type is stored first.
Suppose integer is stored as 4 bytes (For those who are using DOS based compilers such as C++ 3.0 , integer is 2 bytes) then a variable x with value 0x01234567 will be stored as following.
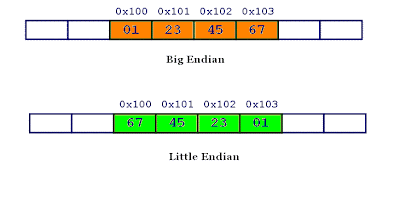
Memory representation of integer ox01234567 inside Big and little endian machines
How to see memory representation of multibyte data types on your machine?
Here is a sample C code that shows the byte representation of int, float and pointer.
#include <stdio.h>
void show_mem_rep(char *start, int n)
{
int i;
for (i = 0; i < n; i++)
printf(" %.2x", start[i]);
printf("\n");
}
int main()
{
int i = 0x01234567;
show_mem_rep((char *)&i, sizeof(i));
getchar();
return 0;
}
When above program is run on little endian machine, gives “67 45 23 01” as output , while if it is run on big endian machine, gives “01 23 45 67” as output.
Is there a quick way to determine endianness of your machine?
There are n no.
of ways for determining endianness of your machine.
Here is one quick way of doing the same.
C++
#include <bits/stdc++.h>
using namespace std;
int main()
{
unsigned int i = 1;
char *c = (char*)&i;
if (*c)
cout<<"Little endian";
else
cout<<"Big endian";
return 0;
}
C
#include <stdio.h>
int main()
{
unsigned int i = 1;
char *c = (char*)&i;
if (*c)
printf("Little endian");
else
printf("Big endian");
getchar();
return 0;
}
Output:
Little endian
In the above program, a character pointer c is pointing to an integer i.
Since size of character is 1 byte when the character pointer is de-referenced it will contain only first byte of integer.
If machine is little endian then *c will be 1 (because last byte is stored first) and if machine is big endian then *c will be 0.
Does endianness matter for programmers?
Most of the times compiler takes care of endianness, however, endianness becomes an issue in following cases.
It matters in network programming: Suppose you write integers to file on a little endian machine and you transfer this file to a big endian machine.
Unless there is little endian to big endian transformation, big endian machine will read the file in reverse order.
You can find such a practical example here.
Standard byte order for networks is big endian, also known as network byte order.
Before transferring data on network, data is first converted to network byte order (big endian).
Sometimes it matters when you are using type casting, below program is an example.
#include <stdio.h>
int main()
{
unsigned char arr[2] = {0x01, 0x00};
unsigned short int x = *(unsigned short int *) arr;
printf("%d", x);
getchar();
return 0;
}
In the above program, a char array is typecasted to an unsigned short integer type.
When I run above program on little endian machine, I get 1 as output, while if I run it on a big endian machine I get 256.
To make programs endianness independent, above programming style should be avoided.
What are bi-endians?
Bi-endian processors can run in both modes little and big endian.
What are the examples of little, big endian and bi-endian machines ?
Intel based processors are little endians.
ARM processors were little endians.
Current generation ARM processors are bi-endian.
Motorola 68K processors are big endians.
PowerPC (by Motorola) and SPARK (by Sun) processors were big endian.
Current version of these processors are bi-endians.
Does endianness affects file formats?
File formats which have 1 byte as a basic unit are independent of endianness e.g., ASCII files .
Other file formats use some fixed endianness forrmat e.g, JPEG files are stored in big endian format.
Which one is better — little endian or big endian?
The term little and big endian came from Gulliver’s Travels by Jonathan Swift.
Two groups could not agree by which end an egg should be opened -a- the little or the big.
Just like the egg issue, there is no technological reason to choose one byte ordering convention over the other, hence the arguments degenerate into bickering about sociopolitical issues.
As long as one of the conventions is selected and adhered to consistently, the choice is arbitrary.
Comparator function of qsort() in C
Standard C library provides qsort() that can be used for sorting an array.
As the name suggests, the function uses QuickSort algorithm to sort the given array.
Following is prototype of qsort()
void qsort (void* base, size_t num, size_t size,
int (*comparator)(const void*,const void*));
The key point about qsort() is comparator function comparator.
The comparator function takes two arguments and contains logic to decide their relative order in sorted output.
The idea is to provide flexibility so that qsort() can be used for any type (including user defined types) and can be used to obtain any desired order (increasing, decreasing or any other).
The comparator function takes two pointers as arguments (both type-casted to const void*) and defines the order of the elements by returning (in a stable and transitive manner
int comparator(const void* p1, const void* p2);
Return value meaning
<0 The element pointed by p1 goes before the element pointed by p2
0 The element pointed by p1 is equivalent to the element pointed by p2
>0 The element pointed by p1 goes after the element pointed by p2
Source: http://www.cplusplus.com/reference/cstdlib/qsort/
For example, let there be an array of students where following is type of student.
struct Student
{
int age, marks;
char name[20];
};
Lets say we need to sort the students based on marks in ascending order.
The comparator function will look like:
int comparator(const void *p, const void *q)
{
int l = ((struct Student *)p)->marks;
int r = ((struct Student *)q)->marks;
return (l - r);
}
See following posts for more sample uses of qsort().
Given a sequence of words, print all anagrams together
Box Stacking Problem
Closest Pair of Points
Following is an interesting problem that can be easily solved with the help of qsort() and comparator function.
Given an array of integers, sort it in such a way that the odd numbers appear first and the even numbers appear later.
The odd numbers should be sorted in descending order and the even numbers should be sorted in ascending order.
The simple approach is to first modify the input array such that the even and odd numbers are segregated followed by applying some sorting algorithm on both parts(odd and even) separately.
However, there exists an interesting approach with a little modification in comparator function of Quick Sort.
The idea is to write a comparator function that takes two addresses p and q as arguments.
Let l and r be the number pointed by p and q.
The function uses following logic:
1) If both (l and r) are odd, put the greater of two first.
2) If both (l and r) are even, put the smaller of two first.
3) If one of them is even and other is odd, put the odd number first.
Following is C implementation of the above approach.
#include <stdio.h>
#include <stdlib.h>
int comparator(const void *p, const void *q)
{
int l = *(const int *)p;
int r = *(const int *)q;
if ((l&1) && (r&1))
return (r-l);
if ( !(l&1) && !(r&1) )
return (l-r);
if (!(l&1))
return 1;
return -1;
}
void printArr(int arr[], int n)
{
int i;
for (i = 0; i < n; ++i)
printf("%d ", arr[i]);
}
int main()
{
int arr[] = {1, 6, 5, 2, 3, 9, 4, 7, 8};
int size = sizeof(arr) / sizeof(arr[0]);
qsort((void*)arr, size, sizeof(arr[0]), comparator);
printf("Output array is\n");
printArr(arr, size);
return 0;
}
Output:
Output array is
9 7 5 3 1 2 4 6 8
Exercise:
Given an array of integers, sort it in alternate fashion.
Alternate fashion means that the elements at even indices are sorted separately and elements at odd indices are sorted separately.
Program to validate an IP address
Write a program to Validate an IPv4 Address.
According to Wikipedia, IPv4 addresses are canonically represented in dot-decimal notation, which consists of four decimal numbers, each ranging from 0 to 255, separated by dots, e.g., 172.16.254.1
Following are steps to check whether a given string is valid IPv4 address or not:
step 1) Parse string with “.” as delimiter using “
strtok()” function.
e.g.
ptr = strtok(str, DELIM);
step 2)
……..a) If ptr contains any character which is not digit then return 0
……..b) Convert “ptr” to decimal number say ‘NUM’
……..c) If NUM is not in range of 0-255 return 0
……..d) If NUM is in range of 0-255 and ptr is non-NULL increment “dot_counter” by 1
……..e) if ptr is NULL goto step 3 else goto step 1
step 3) if dot_counter != 3 return 0 else return 1.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define DELIM "."
int valid_digit(char *ip_str)
{
while (*ip_str) {
if (*ip_str >= '0' && *ip_str <= '9')
++ip_str;
else
return 0;
}
return 1;
}
int is_valid_ip(char *ip_str)
{
int i, num, dots = 0;
char *ptr;
if (ip_str == NULL)
return 0;
ptr = strtok(ip_str, DELIM);
if (ptr == NULL)
return 0;
while (ptr) {
if (!valid_digit(ptr))
return 0;
num = atoi(ptr);
if (num >= 0 && num <= 255) {
ptr = strtok(NULL, DELIM);
if (ptr != NULL)
++dots;
} else
return 0;
}
if (dots != 3)
return 0;
return 1;
}
int main()
{
char ip1[] = "128.0.0.1";
char ip2[] = "125.16.100.1";
char ip3[] = "125.512.100.1";
char ip4[] = "125.512.100.abc";
is_valid_ip(ip1)? printf("Valid\n"): printf("Not valid\n");
is_valid_ip(ip2)? printf("Valid\n"): printf("Not valid\n");
is_valid_ip(ip3)? printf("Valid\n"): printf("Not valid\n");
is_valid_ip(ip4)? printf("Valid\n"): printf("Not valid\n");
return 0;
}
Output:
Valid
Valid
Not valid
Not valid
Multithreading in C
What is a Thread?
A thread is a single sequence stream within in a process.
Because threads have some of the properties of processes, they are sometimes called
lightweight processes.
What are the differences between process and thread?
Threads are not independent of one other like processes as a result threads shares with other threads their code section, data section and OS resources like open files and signals.
But, like process, a thread has its own program counter (PC), a register set, and a stack space.
Why Multithreading?
Threads are popular way to improve application through parallelism.
For example, in a browser, multiple tabs can be different threads.
MS word uses multiple threads, one thread to format the text, other thread to process inputs, etc.
Threads operate faster than processes due to following reasons:
1) Thread creation is much faster.
2) Context switching between threads is much faster.
3) Threads can be terminated easily
4) Communication between threads is faster.
See
http://www.personal.kent.edu/~rmuhamma/OpSystems/Myos/threads.htm for more details.
Can we write multithreading programs in C?
Unlike Java, multithreading is not supported by the language standard.
POSIX Threads (or Pthreads) is a POSIX standard for threads.
Implementation of pthread is available with gcc compiler.
A simple C program to demonstrate use of pthread basic functions
Please note that the below program may compile only with C compilers with pthread library.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h> //Header file for sleep().
man 3 sleep for details.
#include <pthread.h>
void *myThreadFun(void *vargp)
{
sleep(1);
printf("Printing GeeksQuiz from Thread \n");
return NULL;
}
int main()
{
pthread_t thread_id;
printf("Before Thread\n");
pthread_create(&thread_id, NULL, myThreadFun, NULL);
pthread_join(thread_id, NULL);
printf("After Thread\n");
exit(0);
}
In main() we declare a variable called thread_id, which is of type pthread_t, which is an integer used to identify the thread in the system.
After declaring thread_id, we call pthread_create() function to create a thread.
pthread_create() takes 4 arguments.
The first argument is a pointer to thread_id which is set by this function.
The second argument specifies attributes.
If the value is NULL, then default attributes shall be used.
The third argument is name of function to be executed for the thread to be created.
The fourth argument is used to pass arguments to the function, myThreadFun.
The pthread_join() function for threads is the equivalent of wait() for processes.
A call to pthread_join blocks the calling thread until the thread with identifier equal to the first argument terminates.
How to compile above program?
To compile a multithreaded program using gcc, we need to link it with the pthreads library.
Following is the command used to compile the program.
gfg@ubuntu:~/$ gcc multithread.c -lpthread
gfg@ubuntu:~/$ ./a.out
Before Thread
Printing GeeksQuiz from Thread
After Thread
gfg@ubuntu:~/$
A C program to show multiple threads with global and static variables
As mentioned above, all threads share data segment.
Global and static variables are stored in data segment.
Therefore, they are shared by all threads.
The following example program demonstrates the same.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
int g = 0;
void *myThreadFun(void *vargp)
{
int *myid = (int *)vargp;
static int s = 0;
++s; ++g;
printf("Thread ID: %d, Static: %d, Global: %d\n", *myid, ++s, ++g);
}
int main()
{
int i;
pthread_t tid;
for (i = 0; i < 3; i++)
pthread_create(&tid, NULL, myThreadFun, (void *)&tid);
pthread_exit(NULL);
return 0;
}
gfg@ubuntu:~/$ gcc multithread.c -lpthread
gfg@ubuntu:~/$ ./a.out
Thread ID: 3, Static: 2, Global: 2
Thread ID: 3, Static: 4, Global: 4
Thread ID: 3, Static: 6, Global: 6
gfg@ubuntu:~/$
Please note that above is simple example to show how threads work.
Accessing a global variable in a thread is generally a bad idea.
What if thread 2 has priority over thread 1 and thread 1 needs to change the variable.
In practice, if it is required to access global variable by multiple threads, then they should be accessed using a mutex.
Assertions in C/C++
Assertions are statements used to test assumptions made by programmer.
For example, we may use assertion to check if pointer returned by malloc() is NULL or not.
Following is syntax for assertion.
void assert( int expression );
If expression evaluates to 0 (false), then the expression, sourcecode filename, and line number are sent to the standard error, and then abort() function is called.
For example, consider the following program.
#include <stdio.h>
#include <assert.h>
int main()
{
int x = 7;
x = 9;
assert(x==7);
return 0;
}
Output
Assertion failed: x==7, file test.cpp, line 13
This application has requested the Runtime to terminate it in an unusual
way.
Please contact the application's support team for more information.
Assertion Vs Normal Error Handling
Assertions are mainly used to check logically impossible situations.
For example, they can be used to check the state a code expects before it starts running or state after it finishes running.
Unlike normal error handling, assertions are generally disabled at run-time.
Therefore, it is not a good idea to write statements in asser() that can cause side effects.
For example writing something like assert(x = 5) is not a good ideas as x is changed and this change won’t happen when assertions are disabled.
See
this for more details.
Ignoring Assertions
In C/C++, we can completely remove assertions at compile time using the preprocessor NODEBUG.
# define NDEBUG
# include <assert.h>
int main()
{
int x = 7;
assert (x==5);
return 0;
}
The above program compiles and runs fine.
In Java, assertions are not enabled by default and we must pass an option to run-time engine to enable them.
Reference:
http://en.wikipedia.org/wiki/Assertion_%28software_development%29
fork() in C
Fork system call is used for creating a new process, which is called
child process, which runs concurrently with the process that makes the fork() call (parent process).
After a new child process is created, both processes will execute the next instruction following the fork() system call.
A child process uses the same pc(program counter), same CPU registers, same open files which use in the parent process.
It takes no parameters and returns an integer value.
Below are different values returned by fork().
Negative Value: creation of a child process was unsuccessful.
Zero: Returned to the newly created child process.
Positive value: Returned to parent or caller.
The value contains process ID of newly created child process.
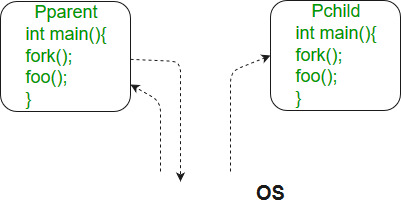 Please note that the above programs don’t compile in Windows environment.
Please note that the above programs don’t compile in Windows environment.
- Predict the Output of the following program:.
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
fork();
printf("Hello world!\n");
return 0;
}
Output:
Hello world!
Hello world!
- Calculate number of times hello is printed:
#include <stdio.h>
#include <sys/types.h>
int main()
{
fork();
fork();
fork();
printf("hello\n");
return 0;
}
Output:
hello
hello
hello
hello
hello
hello
hello
hello
The number of times ‘hello’ is printed is equal to number of process created.
Total Number of Processes = 2n, where n is number of fork system calls.
So here n = 3, 23 = 8
Let us put some label names for the three lines:
fork (); // Line 1
fork (); // Line 2
fork (); // Line 3
L1 // There will be 1 child process
/ \ // created by line 1.
L2 L2 // There will be 2 child processes
/ \ / \ // created by line 2
L3 L3 L3 L3 // There will be 4 child processes
// created by line 3
So there are total eight processes (new child processes and one original process).
If we want to represent the relationship between the processes as a tree hierarchy it would be the following:
The main process: P0
Processes created by the 1st fork: P1
Processes created by the 2nd fork: P2, P3
Processes created by the 3rd fork: P4, P5, P6, P7
P0
/ | \
P1 P4 P2
/ \ \
P3 P6 P5
/
P7
- Predict the Output of the following program:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
void forkexample()
{
if (fork() == 0)
printf("Hello from Child!\n");
else
printf("Hello from Parent!\n");
}
int main()
{
forkexample();
return 0;
}
Output:
1.
Hello from Child!
Hello from Parent!
(or)
2.
Hello from Parent!
Hello from Child!
In the above code, a child process is created.
fork() returns 0 in the child process and positive integer in the parent process.
Here, two outputs are possible because the parent process and child process are running concurrently.
So we don’t know whether the OS will first give control to the parent process or the child process.
Important: Parent process and child process are running the same program, but it does not mean they are identical.
OS allocate different data and states for these two processes, and the control flow of these processes can be different.
See next example:
- Predict the Output of the following program:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
void forkexample()
{
int x = 1;
if (fork() == 0)
printf("Child has x = %d\n", ++x);
else
printf("Parent has x = %d\n", --x);
}
int main()
{
forkexample();
return 0;
}
Output:
Parent has x = 0
Child has x = 2
(or)
Child has x = 2
Parent has x = 0
Here, global variable change in one process does not affected two other processes because data/state of two processes are different.
And also parent and child run simultaneously so two outputs are possible.
fork() vs exec()
The fork system call creates a new process.
The new process created by fork() is a copy of the current process except for the returned value.
The exec() system call replaces the current process with a new program.
Exercise:
- A process executes the following code:
for (i = 0; i < n; i++)
fork();
The total number of child processes created is: (GATE-CS-2008)
(A) n
(B) 2^n – 1
(C) 2^n
(D) 2^(n+1) – 1;
See this for solution.
- Consider the following code fragment:
if (fork() == 0) {
a = a + 5;
printf("%d, %d\n", a, &a);
}
else {
a = a –5;
printf("%d, %d\n", a, &a);
}
Let u, v be the values printed by the parent process, and x, y be the values printed by the child process.
Which one of the following is TRUE? (GATE-CS-2005)
(A) u = x + 10 and v = y
(B) u = x + 10 and v != y
(C) u + 10 = x and v = y
(D) u + 10 = x and v != y
See this for solution.
-
Predict output of below program.
#include <stdio.h>
#include <unistd.h>
int main()
{
fork();
fork() && fork() || fork();
fork();
printf("forked\n");
return 0;
}
See this for solution
Related Articles :
C program to demonstrate fork() and pipe()
Zombie and Orphan Processes in C
fork() and memory shared b/w processes created using it.
Interesting Facts in C Programming
Below are some interesting facts about C programming:
1) The case labels of a switch statement can occur inside if-else statements.
#include <stdio.h>
int main()
{
int a = 2, b = 2;
switch(a)
{
case 1:
;
if (b==5)
{
case 2:
printf("GeeksforGeeks");
}
else case 3:
{
}
}
}
Output :
GeeksforGeeks
2) arr[index] is same as index[arr]
The reason for this to work is, array elements are accessed using pointer arithmetic.
#include<stdio.h>
int main()
{
int arr[10];
arr[0] = 1;
printf("%d", 0[arr] );
return 0;
}
Output :
1
3) We can use ‘<:, :>’ in place of ‘[,]’ and ‘<%, %>’ in place of ‘{,}’
#include<stdio.h>
int main()
<%
int arr <:10:>;
arr<:0:> = 1;
printf("%d", arr<:0:>);
return 0;
%>
Output :
1
4) Using #include in strange places.
Let “a.txt” contains (“GeeksforGeeks”);
#include<stdio.h>
int main()
{
printf
#include "a.txt"
;
}
Output :
GeeksforGeeks
5) We can ignore input in scanf() by using an ‘*’ after ‘%’ in format specifiers
#include<stdio.h>
int main()
{
int a;
scanf("%*d%d", &a);
printf( "%d ", a);
return 0;
}
Precision of floating point numbers in C++ (floor(), ceil(), trunc(), round() and setprecision())
Decimal equivalent of 1/3 is 0.33333333333333….
An infinite length number would require infinite memory to store, and we typically have 4 or 8 bytes.
Therefore, Floating point numbers store only a certain number of significant digits, and the rest are lost.
The
precision of a floating point number defines how many significant digits it can represent without information loss.
When outputting floating point numbers, cout has a default precision of 6 and it truncates anything after that.
Given below are few libraries and methods which are used to provide precision to floating point numbers in C++:
floor():
Floor rounds off the given value to the closest integer which is less than the given value.
#include<bits/stdc++.h>
using namespace std;
int main()
{
double x =1.411, y =1.500, z =1.711;
cout << floor(x) << endl;
cout << floor(y) << endl;
cout << floor(z) << endl;
double a =-1.411, b =-1.500, c =-1.611;
cout << floor(a) << endl;
cout << floor(b) << endl;
cout << floor(c) << endl;
return 0;
}
Output:
1
1
1
-2
-2
-2
ceil():
Ceil rounds off the given value to the closest integer which is more than the given value.
#include<bits/stdc++.h>
using namespace std;
int main()
{
double x = 1.411, y = 1.500, z = 1.611;
cout << ceil(x) << endl;
cout << ceil(y) << endl;
cout << ceil(z) << endl;
double a = -1.411, b = -1.500, c = -1.611;
cout << ceil(a) << endl;
cout << ceil(b) << endl;
cout << ceil(c) << endl;
return 0;
}
Output:
2
2
2
-1
-1
-1
trunc():
Trunc rounds removes digits after decimal point.
#include<bits/stdc++.h>
using namespace std;
int main()
{
double x = 1.411, y = 1.500, z = 1.611;
cout << trunc(x) << endl;
cout << trunc(y) << endl;
cout << trunc(z) <<endl;
double a = -1.411, b = -1.500, c = -1.611;
cout << trunc(a) <<endl;
cout << trunc(b) <<endl;
cout << trunc(c) <<endl;
return 0;
}
Output:
1
1
1
-1
-1
-1
round():
Rounds given number to the closest integer.
#include<bits/stdc++.h>
using namespace std;
int main()
{
double x = 1.411, y = 1.500, z = 1.611;
cout << round(x) << endl;
cout << round(y) << endl;
cout << round(z) << endl;
double a = -1.411, b = -1.500, c = -1.611;
cout << round(a) << endl;
cout << round(b) << endl;
cout << round(c) << endl;
return 0;
}
Output:
1
2
2
-1
-2
-2
setprecision():
Setprecision when used along with ‘fixed’ provides precision to floating point numbers correct to decimal numbers mentioned in the brackets of the setprecison.
#include<bits/stdc++.h>
using namespace std;
int main()
{
double pi = 3.14159, npi = -3.14159;
cout << fixed << setprecision(0) << pi <<" "<<npi<<endl;
cout << fixed << setprecision(1) << pi <<" "<<npi<<endl;
cout << fixed << setprecision(2) << pi <<" "<<npi<<endl;
cout << fixed << setprecision(3) << pi <<" "<<npi<<endl;
cout << fixed << setprecision(4) << pi <<" "<<npi<<endl;
cout << fixed << setprecision(5) << pi <<" "<<npi<<endl;
cout << fixed << setprecision(6) << pi <<" "<<npi<<endl;
}
Output:
3 -3
3.1 -3.1
3.14 -3.14
3.142 -3.142
3.1416 -3.1416
3.14159 -3.14159
3.141590 -3.141590
Note: When the value mentioned in the setprecision() exceeds the number of floating point digits in the original number then 0 is appended to floating point digit to match the precision mentioned by the user.
There exists other methods too to provide precision to floating point numbers.
The above mentioned are few of the most commonly used methods to provide precision to floating point numbers during competitive coding.
Concept of setjump and longjump in C
“Setjump” and “Longjump” are defined in
setjmp.h, a header file in C standard library.
- setjump(jmp_buf buf) : uses buf to remember current position and returns 0.
- longjump(jmp_buf buf, i) : Go back to place buf is pointing to and return i .
#include<stdio.h>
#include<setjmp.h>
jmp_buf buf;
void func()
{
printf("Welcome to GeeksforGeeks\n");
longjmp(buf, 1);
printf("Geek2\n");
}
int main()
{
if (setjmp(buf))
printf("Geek3\n");
else
{
printf("Geek4\n");
func();
}
return 0;
}
Output :
Geek4
Welcome to GeeksforGeeks
Geek3
The main feature of these function is to provide a way that deviates from standard call and return sequence.
This is mainly used to implement exception handling in C.
setjmp can be used like
try (in languages like C++ and Java).
The call to
longjmp can be used like
throw (Note that longjmp() transfers control to the point set by setjmp()).
nextafter() and nexttoward() in C/C++
How would you solve below problems in C/C++?
- What is the smallest representable positive floating point number in C/C++?
- What is the largest representable negative floating point number in C/C++?
- Given a positive floating point number x, find the largest representable floating point value smaller than x?
nextafter(x, y) and nexttoward(x.y)
In C and C++, both nextafter(x, y) and nexttoward(x.y) are similar functions defined in math.h or cmath header files.
They both return next representable value after x in the direction of y.
nexttoward() has more precise second parameter y.
The following program demonstrates the concept :
#include <stdio.h>
#include <math.h>
int main ()
{
printf ("Smallest positive floating point number : %e\n",
nextafter(0.0, 1.0));
printf ("Largest negative floating point number :%e\n",
nextafter(0.0, -1.0));
printf ("Largest positive floating point number smaller than 0.5 : %e\n",
nextafter(0.5, 0.0));
printf ("Smallest positive floating point number : %e\n",
nexttoward(0.0, 1.0));
printf ("Largest negative floating point number : %e\n",
nexttoward(0.0, -1.0));
printf ("Largest positive floating point number smaller than 0.5 : %e\n",
nexttoward(0.5, 0.0));
return (0);
}
Output:
nextafter first value greater than zero: 4.940656e-324
nextafter first value less than zero: -4.940656e-324
nexttoward first value greater than zero: 4.940656e-324
nexttoward first valnextafter first value greater than zero: 4.940656e-324
nextafter first value less than zero: -4.940656e-324
nexttoward first value greater than zero: 4.940656e-324
nexttoward first value less than zero: -4.940656e-324 ue less than zero: -4.940656e-324
pthread_cancel() in C with example
prerequisite: Multithreading, pthread_self() in C with Example
pthread_cancel() = This function cancel a particular thread using thread id.
This function send a cancellation request to the thread.
Syntax : – int pthread_cancel(pthread_t thread);
First Program : – Cancel self thread
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void* calls(void* ptr)
{
printf("GeeksForGeeks");
pthread_cancel(pthread_self());
return NULL;
}
int main()
{
pthread_t thread;
pthread_create(&thread, NULL, calls, NULL);
pthread_join(thread, NULL);
return 0;
}
Output:
GeeksForGeeks
If you use Linux then compile this program
gcc program_name.c -lpthread
Second Program : – Cancel other thread
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <pthread.h>
int counter = 0;
pthread_t tmp_thread;
void* func(void* p)
{
while (1) {
printf("thread number one\n");
sleep(1);
counter++;
if (counter = = 2) {
pthread_cancel(tmp_thread);
pthread_exit(NULL);
}
}
}
void* func2(void* p)
{
tmp_thread = pthread_self();
while (1) {
printf("thread Number two");
sleep(1);
}
}
int main()
{
pthread_t thread_one, thread_two;
pthread_create(&thread_one, NULL, func, NULL);
pthread_create(&thread_two, NULL, func2, NULL);
pthread_join(thread_one, NULL);
pthread_join(thread_two, NULL);
}
Output:
thread number one
thread number two
thread number one
thread number two
If you use Linux then compile this program
gcc program_name.c -lpthread
pthread_equal() in C with example
Prerequisite :
Multithreading,
pthread_self() in C with Example
pthread_equal() = This compares two thread which is equal or not.
This function compares two thread identifiers.
It return ‘0’ and non zero value.
If it is equal then return non zero value else return 0.
Syntax:- int pthread_equal (pthread_t t1, pthread_t t2);
First Method :- Compare with self thread
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <pthread.h>
pthread_t tmp_thread;
void* func_one(void* ptr)
{
if (pthread_equal(tmp_thread, pthread_self())) {
printf("equal\n");
} else {
printf("not equal\n");
}
}
int main()
{
pthread_t thread_one;
tmp_thread = thread_one;
pthread_create(&thread_one, NULL, func_one, NULL);
pthread_join(thread_one, NULL);
}
Output:
equal
Second Method :- Compare with other thread
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <pthread.h>
pthread_t tmp_thread;
void* func_one(void* ptr)
{
tmp_thread = pthread_self();
}
void* func_two(void* ptr)
{
pthread_t thread_two = pthread_self();
if (pthread_equal(tmp_thread, thread_two)) {
printf("equal\n");
} else {
printf("not equal\n");
}
}
int main()
{
pthread_t thread_one, thread_two;
pthread_create(&thread_one, NULL, func_one, NULL);
pthread_create(&thread_two, NULL, func_two, NULL);
pthread_join(thread_one, NULL);
pthread_join(thread_two, NULL);
}
Output:
not equal
pthread_self() in C with Example
Prerequisite :
Multithreading in C
Syntax :- pthread_t pthread_self(void);
The pthread_self() function returns the ID of the thread in which it is invoked.
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void* calls(void* ptr)
{
printf("In function \nthread id = %d\n", pthread_self());
pthread_exit(NULL);
return NULL;
}
int main()
{
pthread_t thread;
pthread_create(&thread, NULL, calls, NULL);
printf("In main \nthread id = %d\n", thread);
pthread_join(thread, NULL);
return 0;
}
Output:
In function
thread id = 1
In main
thread id = 1
Local Labels in C
Everybody who has programmed in C programming language must be aware about “goto” and “labels” used in C to jump within a C function.
GCC provides an extension to C called “local labels”.
Conventional Labels vs Local Labels
Conventional labels in C have function scope.
Where as local label can be scoped to a inner nested block.
Therefore, conventional Labels cannot be declared more than once in a function and that is where local labels are used.
A label can appear more than once in function when the label is inside a macro and macro is expanded multiple times in a function.
For example if a macro funcMacro() has definition which involves jump instructions (goto statement) within the block and funcMacro is used by a function foo() several times.
#define funcMacro(params …)
do { \
if (cond == true) \
goto x; \
<some code > \
\
x: \
<some code> \
} while(0); \
Void foo()
{
<some code>
funcMacro(params …);
<some code >
funcMacro(params…);
}
In such a function foo() , the function macro will be expanded two times.
This will result in having more than one definition of label ‘x’ in a function, which leads to confusion to the compiler and results in compilation error.
In such cases local labels are useful.
The above problem can be avoided by using local labels.
A local label are declared as below:
__label__ label;
Local label declarations must come at the beginning of the block, before any ordinary declarations or statements.
Below is C example where a macro IS_STR_EMPTY() is expanded multiple times.
Since local labels have block scope and every expansion of macro causes a new do while block, the program compiles and runs fine.
#include <stdio.h>
#include <string.h>
#define IS_STR_EMPTY(str) \
do { \
__label__ empty, not_empty, exit; \
if (strlen(str)) \
goto not_empty; \
else \
goto empty; \
\
not_empty: \
printf("string = %s\n", str); \
goto exit; \
empty: \
printf("string is empty\n"); \
exit: ; \
} while(0); \
int main()
{
char string[20] = {'\0'};
IS_STR_EMPTY(string);
strcpy(string, "geeksForgeeks");
IS_STR_EMPTY(string);
return 0;
}
Output:
string is empty
string = geeksForgeeks
lvalue and rvalue in C language
L-value: “l-value” refers to memory location which identifies an object.
l-value may appear as either left hand or right hand side of an assignment operator(=).
l-value often represents as identifier.
Expressions referring to modifiable locations are called “
modifiable l-values“.
A modifiable l-value cannot have an array type, an incomplete type, or a type with the
const attribute.
For structures and unions to be modifiable
lvalues, they must not have any members with the
const attribute.
The name of the identifier denotes a storage location, while the value of the variable is the value stored at that location.
An identifier is a modifiable
lvalue if it refers to a memory location and if its type is arithmetic, structure, union, or pointer.
For example, if ptr is a pointer to a storage region, then
*ptr is a modifiable l-value that designates the storage region to which
ptr points.
In C, the concept was renamed as
“locator value”, and referred to expressions that locate (designate) objects.
The l-value is one of the following:
-
The name of the variable of any type i.e, an identifier of integral, floating, pointer, structure, or union type.
-
A subscript ([ ]) expression that does not evaluate to an array.
-
A unary-indirection (*) expression that does not refer to an array
-
An l-value expression in parentheses.
-
A const object (a nonmodifiable l-value).
-
The result of indirection through a pointer, provided that it isn’t a function pointer.
-
The result of member access through pointer(-> or .)
int a;
a = 1;
int b = a;
9 = a;
R-value: r-value” refers to data value that is stored at some address in memory.
A r-value is an expression that can’t have a value assigned to it which means r-value can appear on right but not on left hand side of an assignment operator(=).
int a = 1, b;
a + 1 = b;
int *p, *q;
*p = 1;
q = p + 5;
*(p + 2) = 18;
p = &b;
int arr[20];
struct S { int m; };
struct S obj;
struct S* ptr = &obj;
Note: The unary & (address-of) operator requires an lvalue as its operand.
That is, &n is a valid expression only if n is an lvalue.
Thus, an expression such as &12 is an error.
Again, 12 does not refer to an object, so it’s not addressable.
For instance,
int a, *p;
p = &a;
&a = p;
int x, y;
( x < y ? y : x) = 0;
Remembering the mnemonic, that lvalues can appear on the left of an assignment operator while rvalues can appear on the right
Reference:
https://msdn.microsoft.com/en-us/library/bkbs2cds.aspx
Get the stack size and set the stack size of thread attribute in C
Prerequisite :
Multithreading
Syntax :
int pthread_attr_getstacksize(const pthread_attr_t* restrict attr,
size_t* restrict stacksize);
int pthread_attr_setstacksize(pthread_attr_t* attr, size_t stacksize);
.
pthread_attr_getstacksize() :
It is use for get threads stack size.
The stacksize attribute gives the minimum stack size allocated to threads stack.
When successfully run then it gives 0 otherwise gives any value.
First argument – It takes pthread attribute.
Second argument – It takes a variable and give the size of the thread attribute.
pthread_attr_setstacksize() :
It is use for set new threads stack size.
The stacksize attribute gives the minimum stack size allocated to threads stack.
When successfully run then it gives 0 otherwise if error gives any value.
First argument – It takes pthread attribute.
Second argument – It takes the size of new stack (In bytes)
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
int main()
{
size_t stksize;
pthread_attr_t atr;
pthread_attr_getstacksize(&atr, &stksize);
printf("Current stack size - > %d\n", stksize);
pthread_attr_setstacksize(&atr, 320000034);
pthread_attr_getstacksize(&atr, &stksize);
printf("New stack size-> %d\n", stksize);
return 0;
}
Output :
Current stack size - > 4196464
New stack size-> 320000034
For compile use gcc program_name.c -lpthread
Difference between fork() and exec()
Every application(program) comes into execution through means of process,
process is a running instance of a program.
Processes are created through different system calls, most popular are
fork() and
exec()
fork()
pid_t pid = fork();
fork() creates a new process by duplicating the calling process, The new process, referred to as child, is an exact duplicate of the calling process, referred to as parent, except for the following :
- The child has its own unique process ID, and this PID does not match the ID of any existing process group.
- The child’s parent process ID is the same as the parent’s process ID.
- The child does not inherit its parent’s memory locks and semaphore adjustments.
- The child does not inherit outstanding asynchronous I/O operations from its parent nor does it inherit any asynchronous I/O contexts from its parent.
Return value of fork()
On success, the PID of the child process is returned in the parent, and 0 is returned in the child.
On failure, -1 is returned in the parent, no child process is created, and errno is set appropriately.
Detailed article on fork system call
exec()
The exec() family of functions replaces the current process image with a new process image.
It loads the program into the current process space and runs it from the entry point.
The exec() family consists of following functions, I have implemented execv() in following C program, you can try rest as an exercise
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ...,
char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[],
char *const envp[]);
fork vs exec
- fork starts a new process which is a copy of the one that calls it, while exec replaces the current process image with another (different) one.
- Both parent and child processes are executed simultaneously in case of fork() while Control never returns to the original program unless there is an exec() error.
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
#include <errno.h>
#include <sys/wait.h>
int main(){
pid_t pid;
int ret = 1;
int status;
pid = fork();
if (pid == -1){
printf("can't fork, error occured\n");
exit(EXIT_FAILURE);
}
else if (pid == 0){
printf("child process, pid = %u\n",getpid());
char * argv_list[] = {"ls","-lart","/home",NULL};
execv("ls",argv_list);
exit(0);
}
else{
printf("parent process, pid = %u\n",getppid());
if (waitpid(pid, &status, 0) > 0) {
if (WIFEXITED(status) && !WEXITSTATUS(status))
printf("program execution successful\n");
else if (WIFEXITED(status) && WEXITSTATUS(status)) {
if (WEXITSTATUS(status) == 127) {
printf("execv failed\n");
}
else
printf("program terminated normally,"
" but returned a non-zero status\n");
}
else
printf("program didn't terminate normally\n");
}
else {
printf("waitpid() failed\n");
}
exit(0);
}
return 0;
}
Output:
parent process, pid = 11523
child process, pid = 14188
Program execution successful
Errors in C/C++
Error is an illegal operation performed by the user which results in abnormal working of the program.
Programming errors often remain undetected until the program is compiled or executed.
Some of the errors inhibit the program from getting compiled or executed.
Thus errors should be removed before compiling and executing.
The most common errors can be broadly classified as follows.
Type of errors

- Syntax errors: Errors that occur when you violate the rules of writing C/C++ syntax are known as syntax errors.
This compiler error indicates something that must be fixed before the code can be compiled.
All these errors are detected by compiler and thus are known as compile-time errors.
Most frequent syntax errors are:
- Run-time Errors : Errors which occur during program execution(run-time) after successful compilation are called run-time errors.
One of the most common run-time error is division by zero also known as Division error.
These types of error are hard to find as the compiler doesn’t point to the line at which the error occurs.
For more understanding run the example given below.
#include<stdio.h>
void main()
{
int n = 9, div = 0;
div = n/0;
printf("resut = %d", div);
}
Error:
warning: division by zero [-Wdiv-by-zero]
div = n/0;
In the given example, there is Division by zero error.
This is an example of run-time error i.e errors occurring while running the program.
- Linker Errors: These error occurs when after compilation we link the different object files with main’s object using Ctrl+F9 key(RUN).
These are errors generated when the executable of the program cannot be generated.
This may be due to wrong function prototyping, incorrect header files.
One of the most common linker error is writing Main() instead of main().
#include<stdio.h>
void Main()
{
int a = 10;
printf("%d", a);
}
Error:
(.text+0x20): undefined reference to `main'
- Logical Errors : On compilation and execution of a program, desired output is not obtained when certain input values are given.
These types of errors which provide incorrect output but appears to be error free are called logical errors.
These are one of the most common errors done by beginners of programming.
These errors solely depend on the logical thinking of the programmer and are easy to detect if we follow the line of execution and determine why the program takes that path of execution.
int main()
{
int i = 0;
for(i = 0; i < 3; i++);
{
printf("loop ");
continue;
}
getchar();
return 0;
}
No output
- Semantic errors : This error occurs when the statements written in the program are not meaningful to the compiler.
void main()
{
int a, b, c;
a + b = c;
}
Error
error: lvalue required as left operand of assignment
a + b = c; //semantic error
Why is C considered faster than other languages ?
You might have came across these statements, C is more optimised or performance of C is better than higher languages, so I’ll be discussing the reasons for this hypothesis.
First let’s list out functionalities which are provided by languages like Java and not C :
- Array index bound checking
- Uninitialized variable values checking
- Check for memory leaks
- Check for null pointer dereference
- Automatic garbage collection
- Run-time type checking
- Exception handling
and there are more such features which are not present in C.
Extra features comes at cost and the cost includes decreased
speed and increased
size.
Let’s take an example for dynamic allocation in C and Java
Java
MyClass obj = new MyClass();
Did you considered size of
obj, the answer is
No.
The reason being it is automatically handled by language itself in background and you don’t have to write specific code for it.
But in case of
C
struct MyStruct *obj = malloc(sizeof(struct MyStruct));
As you can see in above code the tasks of assigning reference to pointer, allocation of size is done explictly by programmer and at last free up allocated memory.
The array bound check is supported by Thumb Execution Environment (ThumbEE), its other features includes automatic null pointer checks on every load and store instruction, an special instruction that call a handler.
Another reason is closeness of C to the Assembly language, in most of the cases its instructions directly map to assembly language, C is only one or level two levels of abstraction away from assembly language while Java is at minimum 3 levels abstraction away from assembler.
Incompatibilities between C and C++ codes
The C/C++ incompatibilities that cause most real problems are not subtle.
Most are easily caught by compilers.
This section gives examples of C code that is not C++ :
1) In C, functions can be defined using a syntax that optionally specifies argument types after the list of arguments:
#include<stdio.h>
void fun(a, b)int a;int b;
{
printf("%d %d", a, b);
}
int main()
{
fun(8, 9);
return 0;
}
Output:
8 9
Error in C++ :- a and b was not declared in this scope
2) In C and in pre-standard versions of C++, the type specifier defaults to int.
#include<stdio.h>
int main()
{
const a = 7;
printf("%d", a);
return 0;
}
Output:
7
Error in C++ :- a does not name a type
3) In C, a global data object may be declared several times without using the
extern specifier.
As long as at most one such declaration provides an initializer, the object is considered defined only once.
#include<stdio.h>
int a; int a;
int main()
{
return 0;
}
Error in C++ :- Redefinition of int a
4) In C, a void* may be used as the right-hand operand of an assignment to or initialization of a variable of any pointer type.
#include<stdio.h>
#include<malloc.h>
void f(int n)
{
int* p = malloc(n* sizeof(int));
}
int main()
{
f(7);
return 0;
}
Error in C++ :- Invalid conversion of void* to int*
5) In C, an array can be initialized by an initializer that has more elements than the array requires.
#include<stdio.h>
int main()
{
char array[5] = "Geeks";
printf("%s", array);
return 0;
}
Output:
Geeks
Error in C++ :- Initializer-string for array of chars is too long
6) In C, a function declared without specifying any argument types can take any number of arguments of any type at all.
Click
here to know more about this.
#include<stdio.h>
void fun() { }
int main(void)
{
fun(10, "GfG", "GQ");
return 0;
}
Error in C++ :- Too many arguments to function 'void fun()'
Related Articles:
Convert C/C++ code to assembly language
We use g++ compiler to turn provided C code into assembly language.
To see the assembly code generated by the C compiler, we can use the
“-S” option on the command line:
Syntax:
$ gcc -S filename.c
This will cause gcc to run the compiler, generating an assembly file.
Suppose we write a C code and store it in a file name “geeks.c” .
#include <stdio.h>
char s[] = "GeeksforGeeks";
int main()
{
int a = 2000, b =17;
printf("%s %d \n", s, a+b);
}
Running the command:
$ gcc -S geeks.c
This will cause gcc to run the compiler, generating an assembly file
geeks.s, and go no further.
(Normally it would then invoke the assembler to generate an object- code file.)
The assembly-code file contains various declarations including the set of lines:
.section __TEXT, __text, regular, pure_instructions
.macosx_version_min 10, 12
.globl _main
.align 4, 0x90
_main: ## @main
.cfi_startproc
## BB#0:
pushq %rbp
Ltmp0:
.cfi_def_cfa_offset 16
Ltmp1:
.cfi_offset %rbp, -16
movq %rsp, %rbp
Ltmp2:
.cfi_def_cfa_register %rbp
subq $16, %rsp
leaq L_.str(%rip), %rdi
leaq _s(%rip), %rsi
movl $2000, -4(%rbp) ## imm = 0x7D0
movl $17, -8(%rbp)
movl -4(%rbp), %eax
addl -8(%rbp), %eax
movl %eax, %edx
movb $0, %al
callq _printf
xorl %edx, %edx
movl %eax, -12(%rbp) ## 4-byte Spill
movl %edx, %eax
addq $16, %rsp
popq %rbp
retq
.cfi_endproc
.section __DATA, __data
.globl _s ## @s
_s:
.asciz "GeeksforGeeks"
.section __TEXT, __cstring, cstring_literals
L_.str: ## @.str
.asciz "%s %d \n"
.subsections_via_symbols
Each indented line in the above code corresponds to a single machine instruction.
For example, the
pushq instruction indicates that the contents of register
%rbp should be pushed onto the program stack.
All information about local variable names or data types has been stripped away.
We still see a reference to the global
variable
s[]= “GeeksforGeeks”, since the compiler has not yet determined where in memory this variable will be stored.
Error Handling in C programs
Although C does not provide direct support to error handling (or exception handling), there are ways through which error handling can be done in C.
A programmer has to prevent errors at the first place and test return values from the functions.
A lot of C function calls return a -1 or NULL in case of an error, so quick test on these return values are easily done with for instance an ‘if statement’. For example, In
Socket Programming, the returned value of the functions like socket(), listen() etc.
are checked to see if there is an error or not.
Example: Error handling in Socket Programming
if ((server_fd = socket(AF_INET, SOCK_STREAM, 0)) == 0)
{
perror("socket failed");
exit(EXIT_FAILURE);
}
Different methods of Error handling in C
- Global Variable errno: When a function is called in C, a variable named as errno is automatically assigned a code (value) which can be used to identify the type of error that has been encountered.
Its a global variable indicating the error occurred during any function call and defined in the header file errno.h.
Different codes (values) for errno mean different types of errors.
Below is a list of few different errno values and its corresponding meaning:
errno value Error
1 /* Operation not permitted */
2 /* No such file or directory */
3 /* No such process */
4 /* Interrupted system call */
5 /* I/O error */
6 /* No such device or address */
7 /* Argument list too long */
8 /* Exec format error */
9 /* Bad file number */
10 /* No child processes */
11 /* Try again */
12 /* Out of memory */
13 /* Permission denied */
#include <stdio.h>
#include <errno.h>
int main()
{
FILE * fp;
fp = fopen("GeeksForGeeks.txt", "r");
printf(" Value of errno: %d\n ", errno);
return 0;
}
Output:
Value of errno: 2
Note: Here the errno is set to 2 which means – No such file or directory.
On online IDE it may give errorno 13, which says permission denied.
- perror() and strerror(): The errno value got above indicate the types of error encountered.
If it is required to show the error description, then there are two functions that can be used to display a text message that is associated with errorno.
The functions are:
#include <stdio.h>
#include <errno.h>
#include <string.h>
int main ()
{
FILE *fp;
fp = fopen(" GeeksForGeeks.txt ", "r");
printf("Value of errno: %d\n ", errno);
printf("The error message is : %s\n",
strerror(errno));
perror("Message from perror");
return 0;
}
Output:
On Personal desktop:
Value of errno: 2
The error message is : No such file or directory
Message from perror: No such file or directory
On online IDE:
Value of errno: 13
The error message is : Permission denied
Note: The function perror() displays a string passed to it, followed by a colon and the textual message of the current errno value.
- Exit Status: The C standard specifies two constants: EXIT_SUCCESS and EXIT_FAILURE, that may be passed to exit() to indicate successful or unsuccessful termination, respectively.
These are macros defined in stdlib.h.
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include <stdlib.h>
int main ()
{
FILE * fp;
fp = fopen ("filedoesnotexist.txt", "rb");
if (fp == NULL)
{
printf("Value of errno: %d\n", errno);
printf("Error opening the file: %s\n",
strerror(errno));
perror("Error printed by perror");
exit(EXIT_FAILURE);
printf("I will not be printed\n");
}
else
{
fclose (fp);
exit(EXIT_SUCCESS);
printf("I will not be printed\n");
}
return 0;
}
Output:
Value of errno: 2
Error opening the file: No such file or directory
Error printed by perror: No such file or directory
- Divide by Zero Errors: A common pitfall made by C programmers is not checking if a divisor is zero before a division command.
Division by zero leads to undefined behavior, there is no C language construct that can do anything about it.
Your best bet is to not divide by zero in the first place, by checking the denominator.
#include<stdio.h>
#include <stdlib.h>
void function(int);
int main()
{
int x = 0;
function(x);
return 0;
}
void function(int x)
{
float fx;
if (x==0)
{
printf("Division by Zero is not allowed");
fprintf(stderr, "Division by zero! Exiting...\n");
exit(EXIT_FAILURE);
}
else
{
fx = 10 / x;
printf("f(x) is: %.5f", fx);
}
}
Output:
Division by Zero is not allowed
Executing main() in C/C++ – behind the scene
How to write a C program to print “Hello world” without main() function?
At first, it seems impractical to execute a program without a main() function because the main() function is the entry point of any program.
Let us first understand what happens under the hood while executing a C program in Linux system, how main() is called and how to execute a program without main().
Following setup is considered for the demonstration.
- Ubuntu 16.4 LTS operating system
- GCC 5.4.0 compiler
- objdump utility
From C/C++ programming perspective, the program entry point is main() function.
From the perspective of program execution, however, it is not.
Prior to the point when the execution flow reaches to the main(), calls to few other functions are made, which setup arguments, prepare environment variables for program execution etc.
The executable file created after compiling a C source code is a
Executable and Linkable Format (ELF) file.
Every ELF file have a ELF header where there is a
e_entry field which contains the program memory address from which the execution of executable will start.
This memory address point to the
_start() function.
After loading the program, loader looks for the
e_entry field from the ELF file header.
Executable and Linkable Format (ELF) is a common standard file format used in UNIX system for executable files, object code, shared libraries, and core dumps.
Let’s see this using an example.
I’m creating a
example.c file to demonstrate this.
int main()
{
return(0);
}
Now compiling this using following commands
gcc -o example example.c
Now an
example executable is created, let us examine this using objdump utility
objdump -f example
This outputs following critical information of executable on my machine.
Have a look at start address below, this is the address pointing to _start() function.
example: file format elf64-x86-64
architecture: i386:x86-64, flags 0x00000112:
EXEC_P, HAS_SYMS, D_PAGED
start address 0x00000000004003e0
We can cross check this address by deassembling the executable, the output is long so I’m just pasting the output which shows where this address
0x00000000004003e0 is pointing
objdump --disassemble example
Output :
00000000004003e0 <_start>:
4003e0: 31 ed xor %ebp,%ebp
4003e2: 49 89 d1 mov %rdx,%r9
4003e5: 5e pop %rsi
4003e6: 48 89 e2 mov %rsp,%rdx
4003e9: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp
4003ed: 50 push %rax
4003ee: 54 push %rsp
4003ef: 49 c7 c0 60 05 40 00 mov $0x400560,%r8
4003f6: 48 c7 c1 f0 04 40 00 mov $0x4004f0,%rcx
4003fd: 48 c7 c7 d6 04 40 00 mov $0x4004d6,%rdi
400404: e8 b7 ff ff ff callq 4003c0
400409: f4 hlt
40040a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
As we can clearly see this is pointing to the _start() function.
The role of _start() function
The _start() function prepare the input arguments for another function
_libc_start_main() which will be called next.
This is prototype of
_libc_start_main() function.
Here we can see the arguments which were prepared by _start() function.
int __libc_start_main(int (*main) (int, char * *, char * *),
int argc,
char ** ubp_av,
void (*init) (void),
void (*fini) (void),
void (*rtld_fini) (void),
void (* stack_end)
);
The role of _libc_start_main() function
The role of _libs_start_main() function is following –
- Preparing environment variables for program execution
- Calls _init() function which performs initialization before the main() function start.
- Register _fini() and _rtld_fini() functions to perform cleanup after program terminates
After all the prerequisite actions has been completed, _libc_start_main() calls the main() function.
Writing program without main()
Now we know how the call to the main() is made.To make it clear, main() is nothing but a agreed term for startup code.
We can have any name for startup code it doesn’t necessarily have to be “main”.
As _start() function by default calls main(), we have to change it if we want to execute our custom startup code.
We can override the _start() function to make it call our custom startup code not main().
Let’s have an example, save it as nomain.c –
#include<stdio.h>
#include<stdlib.h>
void _start()
{
int x = my_fun();
exit(x);
}
int my_fun()
{
printf("Hello world!\n");
return 0;
}
Now we have to force compiler to not use it’s own implementation of _start().In GCC we can do this using -nostartfiles
gcc -nostartfiles -o nomain nomain.c
Execute the executable nomain
./nomain
Output:
Hello world!
Hygienic Macros : An Introduction
We are all familiar with the working of
macros in languages like C.
There are certain situations in which macro expansions can lead to undesirable results because of accidental capture of identifiers.
For example:
#define INCI(i) do { int x = 0; ++i; } while(0)
int main(void)
{
int x = 4, y = 8;
INCI(x);
INCI(y);
printf("x = %d, b = %d\n", x, y);
return 0;
}
The code is actually equivalent to:
int main(void)
{
int x = 4, y = 8;
do { int x = 0; ++x; } while(0);
do { int x = 0; ++y; } while(0);
printf("x = %d, b = %d\n", x, y);
return 0;
}
Output:
x = 4, y = 9
The variable a declared in the scope of the main function is overshadowed by the variable a in the macro definition so
a = 4 never gets updated (known as accidental capture).
Hygienic macros
Hygienic macros are macros whose expansion is guaranteed not to cause the accidental capture of identifiers.
A hygienic macro doesn’t use variable names that can risk interfering with the code under expansion.
The situation in the above code can be avoided simply by changing the name of the variable in the macro definition, which will produce a different output.
#define INCI(i) do { int m = 0; ++i; } while(0)
int main(void)
{
int x = 4, y = 8;
INCI(x);
INCI(y);
printf("x = %d, y = %d\n", x, y);
return 0;
}
Output:
x = 5, y = 9
Command line arguments in C/C++
The most important function of C/C++ is main() function.
It is mostly defined with a return type of int and without parameters :
int main() { /* ...*/ }
We can also give command-line arguments in C and C++.
Command-line arguments are given after the name of the program in command-line shell of Operating Systems.
To pass command line arguments, we typically define main() with two arguments : first argument is the number of command line arguments and second is list of command-line arguments.
int main(int argc, char *argv[]) { /* ...*/ }
or
int main(int argc, char **argv) { /* ...*/ }
- argc (ARGument Count) is int and stores number of command-line arguments passed by the user including the name of the program.
So if we pass a value to a program, value of argc would be 2 (one for argument and one for program name)
- The value of argc should be non negative.
- argv(ARGument Vector) is array of character pointers listing all the arguments.
- If argc is greater than zero,the array elements from argv[0] to argv[argc-1] will contain pointers to strings.
- Argv[0] is the name of the program , After that till argv[argc-1] every element is command -line arguments.
For better understanding run this code on your linux machine.
#include <iostream>
using namespace std;
int main(int argc, char** argv)
{
cout << "You have entered " << argc
<< " arguments:" << "\n";
for (int i = 0; i < argc; ++i)
cout << argv[i] << "\n";
return 0;
}
Input:
$ g++ mainreturn.cpp -o main
$ ./main geeks for geeks
Output:
You have entered 4 arguments:
./main
geeks
for
geeks
Note : Other platform-dependent formats are also allowed by the C and C++ standards; for example, Unix (though not POSIX.1) and Microsoft Visual C++ have a third argument giving the program’s environment, otherwise accessible through getenv in stdlib.h: Refer
C program to print environment variables for details.
Properties of Command Line Arguments:
- They are passed to main() function.
- They are parameters/arguments supplied to the program when it is invoked.
- They are used to control program from outside instead of hard coding those values inside the code.
- argv[argc] is a NULL pointer.
- argv[0] holds the name of the program.
- argv[1] points to the first command line argument and argv[n] points last argument.
Note : You pass all the command line arguments separated by a space, but if argument itself has a space then you can pass such arguments by putting them inside double quotes “” or single quotes ”.
#include<stdio.h>
int main(int argc,char* argv[])
{
int counter;
printf("Program Name Is: %s",argv[0]);
if(argc==1)
printf("\nNo Extra Command Line Argument Passed Other Than Program Name");
if(argc>=2)
{
printf("\nNumber Of Arguments Passed: %d",argc);
printf("\n----Following Are The Command Line Arguments Passed----");
for(counter=0;counter<argc;counter++)
printf("\nargv[%d]: %s",counter,argv[counter]);
}
return 0;
}
Output in different scenarios:
- Without argument: When the above code is compiled and executed without passing any argument, it produces following output.
$ ./a.out
Program Name Is: ./a.out
No Extra Command Line Argument Passed Other Than Program Name
- Three arguments : When the above code is compiled and executed with a three arguments, it produces the following output.
$ ./a.out First Second Third
Program Name Is: ./a.out
Number Of Arguments Passed: 4
----Following Are The Command Line Arguments Passed----
argv[0]: ./a.out
argv[1]: First
argv[2]: Second
argv[3]: Third
- Single Argument : When the above code is compiled and executed with a single argument separated by space but inside double quotes, it produces the following output.
$ ./a.out "First Second Third"
Program Name Is: ./a.out
Number Of Arguments Passed: 2
----Following Are The Command Line Arguments Passed----
argv[0]: ./a.out
argv[1]: First Second Third
- Single argument in quotes separated by space : When the above code is compiled and executed with a single argument separated by space but inside single quotes, it produces the following output.
$ ./a.out 'First Second Third'
Program Name Is: ./a.out
Number Of Arguments Passed: 2
----Following Are The Command Line Arguments Passed----
argv[0]: ./a.out
argv[1]: First Second Third
Inbuilt library functions for user Input | scanf, fscanf, sscanf, scanf_s, fscanf_s, sscanf_s
- scanf() : The C library function int scanf (const char *format, …) reads formatted input from stdin.
Syntax:
int scanf(const char *format, ...)
Return type: Integer
Parameters:
format: string that contains the type specifier(s)
"..." (ellipsis): indicates that the function accepts
a variable number of arguments
Each argument must be a memory address where the converted result is written to.
On success, the function returns the number of variables filled.
In case of an input failure, before any data could be successfully read, EOF is returned.
Type specifiers that can be used in scanf:
%c — Character
%d — Signed integer
%f — Floating point
%s — String
#include <stdio.h>
#include <stdlib.h>
int main()
{
char a[10];
printf("Please enter your name : \n");
scanf("%s", a);
printf("You entered: \n%s", a);
return 0;
}
Input:
Geek
Output:
Please enter your name :
You entered:
Geek
- sscanf(): sscanf() is used to read formatted input from the string.
Syntax:
int sscanf ( const char * s, const char * format, ...);
Return type: Integer
Parameters:
s: string used to retrieve data
format: string that contains the type specifier(s)
… : arguments contains pointers to allocate
storage with appropriate type.
There should be at least as many of these arguments as the
number of values stored by the format specifiers.
On success, the function returns the number of variables filled.
In the case of an input failure, before any data could be successfully read, EOF is returned.
#include <stdio.h>
int main ()
{
char s [] = "3 red balls 2 blue balls";
char str [10],str2 [10];
int i;
sscanf (s,"%d %*s %*s %*s %s %s", &i, str, str2);
printf ("%d %s %s \n", i, str, str2);
return 0;
}
Output:
3 blue balls
- fscanf(): fscanf() reads formatted data from file and stores it into variables.
Syntax:
int fscanf(FILE *stream, const char *format, ...)
Parameters:
Stream: pointer to the File object that identifies the stream.
format : is a string that contains the type specifier(s)
On success, the function returns the number of variables filled.
In the case of an input failure, before any data could be successfully read, EOF is returned.
#include <stdio.h>
#include <stdlib.h>
int main()
{
char s1[10], s2[10], s3[10];
int year;
FILE * fp;
fp = fopen ("file.txt", "w+");
fputs("Hello World its 2017", fp);
rewind(fp);
fscanf(fp, "%s %s %s %d", s1, s2, s3, &year);
printf("String1 |%s|\n", s1 );
printf("String2 |%s|\n", s2 );
printf("String3 |%s|\n", s3 );
printf("Integer |%d|\n", year );
fclose(fp);
return(0);
}
Output:
String1 |Hello|
String2 |World|
String3 |its|
Integer |2017|
- scanf_s() : This function is specific to Microsoft compilers.
It is the same as scanf, except it does not cause buffer overload.
Syntax:
int scanf_s(const char *format [argument]...);
argument(parameter): here you can specify the buffer size and actually control the limit
of the input so you don't crash the whole application.
On success, the function returns the number of variables filled.
In the case of an input failure, before any data could be successfully read, EOF is returned.
Why to use scanf_s()?
scanf just reads whatever input is provided from the console.
C does not check whether the user input will fit in the variable that you’ve designated.
If you have an array called color[3] and you use scanf for “Red”, it will work fine but if user enters more than 3 characters scanf starts writing into memory that doesn’t belong to colour.
C won’t catch this or warn you and it might or might not crash the program, depending on if something tries to access and write on that memory slot that doesn’t belong to color.
This is where scanf_s comes into play.
scanf_s checks that the user input will fit in the given memory space.
#include <stdio.h>
#include <stdlib.h>
int main()
{
char a[5];
scanf_s("%s", a, sizeof(a));
printf("\n%s ", a);
return 0;
}
Input:
Red
Output:
Red
Input:
Yellow
Output:
No Output
Illustrating the relation between buffer size and array size.
C
#include<stdio.h>
char ch[100000];
printf("Enter characters: ");
scanf_s("%s", ch, 99999);
getchar();
C++
#include "stdafx.h"
int _tmain(int argc, _TCHAR* argv[])
{
char ch[100000];
printf("Enter characters: ");
scanf_s("%s", ch, 99999);
getchar();
return 0;
}
- If the buffer size is equal to or smaller than the size of the array, then inputting bigger than or equal to the buffer size will do nothing.
- If the buffer size is bigger than the size of an array, then
- inputting smaller than buffer size will work out but will give an error
“Run-Time Check Failure #2 – Stack around the variable ‘variable_name’ was corrupted.”
- inputting bigger than buffer size will do nothing and give the same error.
- fscanf_s() : Difference between fscanf() and fscanf_s() is same as that of scanf() and scanf_s().
fscanf_s() is secure function and secure functions require the size of each c, C, s, S and [ type field to be passed as an argument immediately following the variable.
Syntax:
int fscanf_s( FILE *stream, const char *format ,[argument ]...
);
fscanf_s has an extra argument(parameter) where you can
specify the buffer size and actually control the limit of the input.
On success, the function returns the number of variables filled.
In the case of an input failure, before any data could be successfully read, EOF is returned.
#include <stdio.h>
#include <stdlib.h>
int main()
{
char s1[10], s2[10], s3[10];
int year;
FILE * fp;
fopen_s(&fp,"file.txt", "w+");
fputs("Hello World its 2017", fp);
rewind(fp);
fscanf_s(fp, "%s", s1, sizeof(s1));
fscanf_s(fp, "%s", s2, sizeof(s2));
fscanf_s(fp, "%s", s3, sizeof(s3));
fscanf_s(fp, "%d", &year, sizeof(year));
printf("String1 |%s|\n", s1);
printf("String2 |%s|\n", s2);
printf("String3 |%s|\n", s3);
printf("Integer |%d|\n", year);
fclose(fp);
return(0);
}
Output:
String1 |Hello|
String2 |World|
String3 |its|
Integer |2017|
- sscanf_s() : sscanf_s() is secure function of sscanf() and secure functions require the size of each c, C, s, S and [ type field to be passed as an argument immediately following the variable.
Syntax:
int sscanf_s(const char *restrict buffer, const char *restrict format, ...);
sscanf_s has an extra argument(parameter) where you can specify
the buffer size and actually control the limit of the input.
On success, the function returns the number of variables filled.
In the case of an input failure, before any data could be successfully read, EOF is returned.
#include <stdio.h>
int main()
{
char s[] = "3 red balls 2 blue balls";
char str[10], str2[10];
int i;
sscanf_s(s, "%d", &i, sizeof(i));
sscanf_s(s, "%*d %*s %*s %*s %s", str, sizeof(str));
sscanf_s(s, "%*d %*s %*s %*s %*s %s", str2, sizeof(str2));
printf("%d %s %s \n", i, str, str2);
return 0;
}
Output:
3 blue balls
Note: sscanf_s() will only work in Microsoft Visual Studio.
Database Connectivity using C/C++
SQL (Structured Query Language) is a fourth-generation language (4GL) that is used to define, manipulate, and control an RDBMS (relational database management system).
Before starting the main article, let us get familiar with the used tools.
-
Compiler: Code::Blocks IDE with MinGW compiler
Download Link: Binary Download
Code::Blocks is a cross compiler (It can run on any platform like Windows, Linux and Mac) and it is free to download.
This IDE is specially designed for C and C++ and easy to use.
-
API: We are going to use SQLAPI++ Library
Download Link: SQLAPI Download
SQLAPI++ is a C++ library (basically a set of header files) for accessing multiple SQL databases (Oracle, SQL Server, DB2, Sybase, Informix, InterBase, SQLBase, MySQL, PostgreSQL, SQLite, SQL Anywhere and ODBC).
It is easy to implement and simple.
-
OCCI: Oracle C++ Call Interface
Download Link: OCCI C++ Download
OCCI is an interface defined by the database company ORACLE that defines a comfortable interfacefor the C++ programmer to access the Oracle database with classes using parameters that are reminiscent of SQL statements.
The interface exists for ORACLE 9i, ORACLE 10 and comes with the Oracle.
We must download and install the above three (if we don’t have them).
Now we are almost ready to start.
Some settings before starting:
-> Open the code::blocks IDE and go to or click on settings -> compiler and debugger settings (You will now see global compiler settings)
-> Now click on “Linker settings” in the linker settings click on ADD button and add the following
For Windows OS :
Code:
C:\SQLAPI\lib\libsqlapiddll.a
C:\Program Files\CodeBlocks\MinGW\lib\libuser32.a
C:\Program Files\CodeBlocks\MinGW\lib\libversion.a
C:\Program Files\CodeBlocks\MinGW\lib\liboleaut32.a
C:\Program Files\CodeBlocks\MinGW\lib\libole32.a
These will be found in your SQLAPI++ (If you have not extracted in C: drive then select the appropriate location and add the mentioned files to linker settings).
The above code is used to add library files to connect C/C++ program with SQLAPI.
Basically, there are 2 steps:
- Connecting to database (and error handling)
Code:
#include<stdio.h>
#include<SQLAPI.h> // main SQLAPI++ header
int main(int argc, char* argv[])
{
SAConnection con;
try
{
con.Connect ("test",
"tester",
"tester",
SA_Oracle_Client);
printf("We are connected!\n");
con.Disconnect();
printf("We are disconnected!\n");
}
catch(SAException & x)
{
try
{
con.Rollback ();
}
catch(SAException &)
{
}
printf("%s\n", (const char*)x.ErrText());
}
return 0;
}
Output:
We are Connected!
We are Disconnected!
- Executing a simple SQL Command
Now, we will look out to execute a simple SQL query.Firstly, creating a table for the database:
create table tb1(id number, name varchar(20);
Now, establish the connection to the database then, after your con.connect; method you should use cmd.setCommandText method to pass the query to the database, it is as shown below:
con.Connect("test", "tester", "tester", SA_Oracle_Client);
cmd.setCommandText("create table tb1(id number, name varchar(20));”);
and now, to execute the query we have to use the following command:
cmd.Execute();
Full Code:
#include<stdio.h>
#include <SQLAPI.h> // main SQLAPI++ header
int main(int argc, char* argv[])
{
SAConnection con;
SACommandcmd;
try
{
con.Connect("test", "tester", "tester", SA_Oracle_Client);
cmd.setConnection(&con);
cmd.setCommandText("create table tbl(id number, name varchar(20));");
cmd.Execute();
cmd.setCommandText("Insert into tbl(id, name) values (1,”Vinay”)");
cmd.setCommandText("Insert into tbl(id, name) values (2,”Kushal”)");
cmd.setCommandText("Insert into tbl(id, name) values (3,”Saransh”)");
cmd.Execute();
con.Commit();
printf("Table created, row inserted!\n");
}
catch(SAException &x)
{
try
{
con.Rollback();
}
catch(SAException &)
{
}
printf("%s\n", (const char*)x.ErrText());
}
return 0;
}
As we know, Oracle is not auto committed (committing is making permanent reflection of data in the database) so, we have to commit it.
con.Commit();
and similarly we can roll back the transactions when an exception occurs, so to do that we use:
con.Rollback();
For deleting a row, we use this command.
cmd.setCommandText("delete from tb1 where id= 2");
Thus, by the end of this article, we have learned how to connect your C/C++ program to database and perform manipulations.
Function Interposition in C with an example of user defined malloc()
Function interposition is the concept of replacing calls to functions in dynamic libraries with calls to user-defined wrappers.
What are applications?
- We can count number of calls to function.
- Store caller’s information and arguments passed to function to track usage.
- Detect memory leak, we can override malloc() and keep track of allocated spaces.
- We can add our own security policies.
For example, we can add a policy that fork cannot be called with more that specified recursion depth.
How to do function interposition?
The task is to write our own malloc() and make sure our own malloc() is called inplace of library malloc().
Below is a driver program to test different types of interpositions of malloc().
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
int main(void)
{
void *ptr = malloc(4);
printf("Hello World\n");
return 0;
}
- Compile time : Replace library call with our own function when the source code is compiled.
#include <stdio.h>
#include <malloc.h>
void *mymalloc(size_t s)
{
printf("My malloc called");
return NULL;
}
#define malloc(size) mymalloc(size)
void *mymalloc(size_t size);
Steps to execute above on Linux:
// Compile the file containing user defined malloc()
:~$ gcc -c mymalloc.c
// Compile hello.c with output file name as helloc.
// -I.
is used to include current folder (.) for header
// files to make sure our malloc.h is becomes available.
:~$ gcc -I.
-o helloc hello.c mymalloc.o
// Run the generated executable
:~$ ./helloc
My malloc called
Hello World
.
- Link time : When the relocatable object files are statically linked to form an executable object file.
#include <stdio.h>
void *__real_malloc(size_t size);
void *__wrap_malloc(size_t size)
{
printf("My malloc called");
return NULL;
}
Steps to execute above on Linux:
// Compile the file containing user defined malloc()
:~$ gcc -c mymalloc.c
// Compile hello.c with output name as hellol
// "-Wl,--wrap=malloc" is used tell the linker to use
// malloc() to call __wrap_malloc().
And to use
// __real_malloc() to actual library malloc()
:~$ gcc -Wl,--wrap=malloc -o hellol hello.c mymalloc.o
// Run the generated executable
:~$ ./hellol
My malloc called
Hello World
.
- Load/run time : When an executable object file is loaded into memory, dynamically linked, and then executed.
The environment variable LD_PRELOAD gives the loader a list of libraries to load be loaded before a command or executable.
We make a dynamic library and make sure it is loaded before our executable for hello.c.
#define _GNU_SOURCE
#include <stdio.h>
void *malloc(size_t s)
{
printf("My malloc called\n");
return NULL;
}
Steps to execute above on Linux:
// Compile hello.c with output name as helloc
:~$ gcc -o hellor hello.c
// Generate a shared library myalloc.so.
Refer
// https://www.geeksforgeeks.org/working-with-shared-libraries-set-2/
// for details.
:~$ gcc -shared -fPIC -o mymalloc.so mymalloc.c
// Make sure shared library is loaded and run before .
:~$ LD_PRELOAD=./mymalloc.so ./hellor
My malloc called
Hello World
.
The code for user defined malloc is kept small for better readability.
Ideally, it should allocate memory by making a call to library malloc().
Source:
https://www.utdallas.edu/~zxl111930/spring2012/public/lec18-handout.pdf
Macros vs Functions
Macros are pre-processed which means that all the macros would be processed before your program compiles.
However, functions are not preprocessed but compiled.
See the following example of Macro:
#include<stdio.h>
#define NUMBER 10
int main()
{
printf("%d", NUMBER);
return 0;
}
Output:
10
See the following example of Function:
#include<stdio.h>
int number()
{
return 10;
}
int main()
{
printf("%d", number());
return 0;
}
Output:
10
Now compile them using the command:
gcc –E file_name.c
This will give you the executable code as shown in the figure:
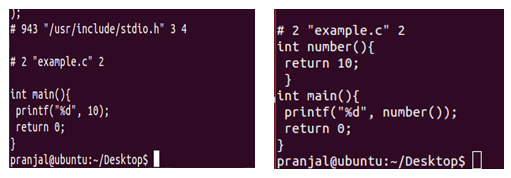 This shows that the macros are preprocessed while functions are not.
In macros, no type checking(incompatible operand, etc.) is done and thus use of micros can lead to errors/side-effects in some cases.
However, this is not the case with functions.
Also, macros do not check for compilation error (if any).
Consider the following two codes:
Macros:
This shows that the macros are preprocessed while functions are not.
In macros, no type checking(incompatible operand, etc.) is done and thus use of micros can lead to errors/side-effects in some cases.
However, this is not the case with functions.
Also, macros do not check for compilation error (if any).
Consider the following two codes:
Macros:
#include<stdio.h>
#define CUBE(b) b*b*b
int main()
{
printf("%d", CUBE(1+2));
return 0;
}
Output: Unexpected output
7
Functions:
#include<stdio.h>
int cube(int a)
{
return a*a*a;
}
int main()
{
printf("%d", cube(1+2));
return 0;
}
Output: As expected
27
- Macros are usually one liner.
However, they can consist of more than one line, Click here to see the usage.
There are no such constraints in functions.
- The speed at which macros and functions differs.
Macros are typically faster than functions as they don’t involve actual function call overhead.
Conclusion:
Macros are no longer recommended as they cause following issues.
There is a better way in modern compilers that is inline functions and const variable.
Below are disadvantages of macros:
a) There is no type checking
b) Difficult to debug as they cause simple replacement.
c) Macro don’t have namespace, so a macro in one section of code can affect other section.
d) Macros can cause side effects as shown in above CUBE() example.
| Macro |
Function |
| Macro is Preprocessed |
Function is Compiled |
| No Type Checking is done in Macro |
Type Checking is Done in Function |
| Using Macro increases the code length |
Using Function keeps the code length unaffected |
| Use of macro can lead to side effect at later stages |
Functions do not lead to any side effect in any case |
| Speed of Execution using Macro is Faster |
Speed of Execution using Function is Slower |
| Before Compilation, macro name is replaced by macro value |
During function call, transfer of control takes place |
| Macros are useful when small code is repeated many times |
Functions are useful when large code is to be written |
| Macro does not check any Compile-Time Errors |
Function checks Compile-Time Errors |
See following for more details on macros:
Interesting facts about Macros and Preprocessors
 The components of the above structure are:
The components of the above structure are: